Announcing DBRX: A new standard for efficient open source LLMs
Build high-quality generative AI applications with DBRX customized for your unique data

Databricks’ mission is to deliver data intelligence to every enterprise by allowing organizations to understand and use their unique data to build their own AI systems. Today, we are excited to advance our mission by open sourcing DBRX, a general purpose large language model (LLM) built by our Databricks AI Research team that outperforms all established open source models on standard benchmarks. We believe that pushing the boundary of open source models enables generative AI for all enterprises that is customizable and transparent.
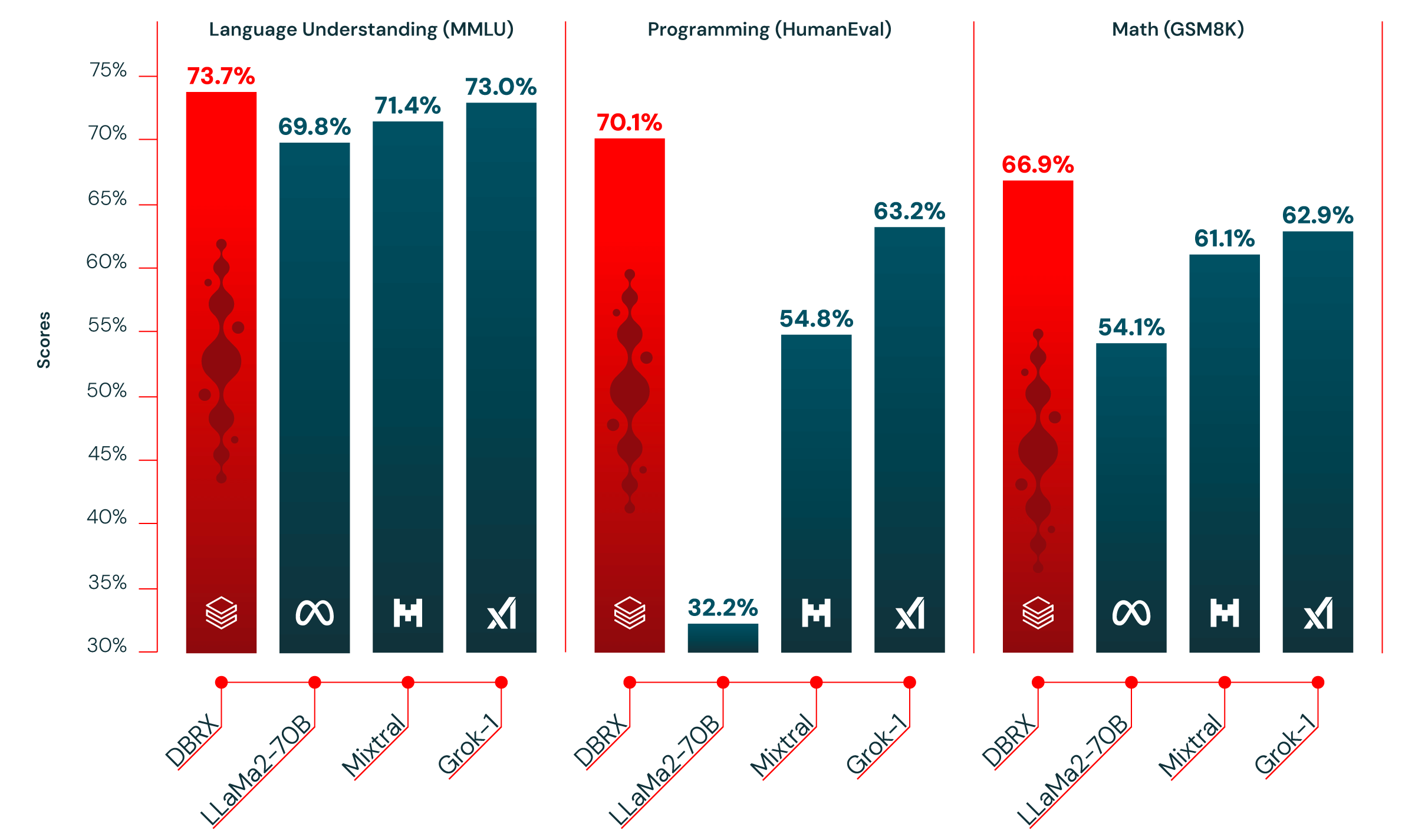
We are excited about DBRX for three distinct reasons. First, it handily beats open source models, such as, LLaMA2-70B, Mixtral, and Grok-1 on language understanding, programming, math, and logic (see Figure 1). In fact, our open source benchmark Gauntlet contains over 30 distinct state-of-the-art (SOTA) benchmarks and DBRX outperforms all those models. This shows that open source models are continuing to improve in quality, a trend that we are proud to play our part in.
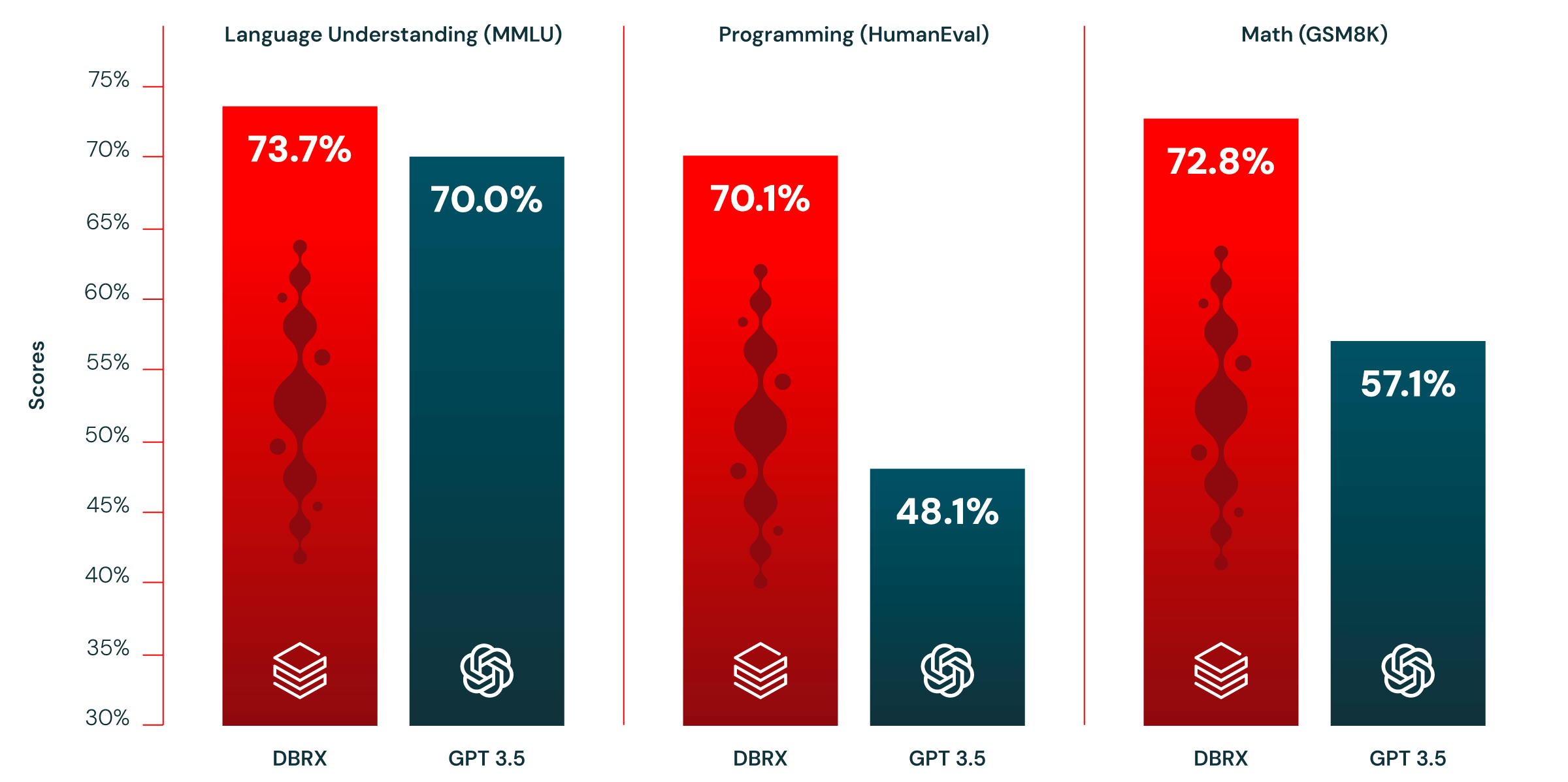
Second, DBRX beats GPT-3.5 on most benchmarks (see Figure 2). This is important as we have seen a major behavioral shift in the last quarter among our 12,000+ customer base. Enterprises and organizations are increasingly replacing proprietary models with open source models for better efficiency and control. In our experience, many customers can outperform the quality and speed of proprietary models by customizing open source models on their specific tasks. We hope that DBRX further accelerates this trend.
Third, DBRX is a Mixture-of-Experts (MoE) model built on the MegaBlocks research and open source project, making the model extremely fast in terms of tokens/second. We believe that this will pave the path for state-of-the-art open source models being MoEs going forward. This is significant because MoEs essentially let you train bigger models and serve them at faster throughput. DBRX uses only 36 billion parameters at any given time. But the model itself is 132 billion parameters, letting you have your cake and eat it too in terms of speed (tokens/second) vs performance (quality).

Databricks 101: A Practical Primer

The aforementioned three reasons lead us to believe that open source LLMs will continue gaining momentum. In particular, we think they provide an exciting opportunity for organizations to customize open source LLMs that can become their IP, which they use to be competitive in their industry.
Towards that, we designed DBRX to be easily customizable so that enterprises can improve the quality of their AI applications. Starting today on the Databricks Platform, enterprises can interact with DBRX, leverage its long context abilities in RAG systems, and build custom DBRX models on their own private data. These customization capabilities are powered by the most efficient MoE training platform that is commercially available. The community can access DBRX through our github repository and Hugging Face.
We built DBRX entirely on top of Databricks, so every enterprise can use the same tools and techniques to create or improve their own high quality models. Training data was centrally governed in Unity Catalog, processed and cleaned with Apache Spark™ and newly acquired Lilac AI. Large scale model training and fine-tuning used our Mosaic AI Training service. Human feedback for quality and safety was collected through Databricks Model Serving and Inference Tables. Customers and partners such as JetBlue, Block, NASDAQ, and Accenture are already using these same tools to build high quality AI systems.
“Databricks is a key partner to NASDAQ on some of our most important data systems. They continue to be at the forefront of the industry in managing data and leveraging AI, and we are excited about the release of DBRX. The combination of strong model performance and favorable serving economics is the kind of innovation we are looking for as we grow our use of generative AI at Nasdaq,” said Mike O'Rourke, Head of AI and Data Services at NASDAQ.
Databricks is the only end-to-end platform to build high quality AI applications, and the release today of DBRX, the highest quality open source model to date, is an expression of that capability. We are excited to learn what the open source community and our enterprise customers can do with DBRX. To continue the conversation, join us for a DBRX webinar with Naveen Rao and Jonathan Frankle.
To learn more, read our technical blog, access the model on GitHub and Databricks Marketplace, and read our documentation (AWS | Azure) on how to get started with DBRX on Databricks.