Announcing Support for Enhanced Fan-Out for Kinesis on Databricks
Simplify Spark Structured Streaming Infrastructure on Databricks

Historically, conventional wisdom held that stream processing is the domain of strictly low latency, operational use cases like sub-second inventory updates on an e-commerce website. In direct contradiction to that, we've observed that many of our customers' most important workloads process large volumes of continuously generated data for use in analytics, BI and ML. That's not to say that those operational use cases aren't important – they absolutely are. Instead, the conclusion here is that the world of stream processing isn't defined by latency, but by the paradigm of incrementally processing continuously generated data. Various consumers with different objectives may rely on the same data sources.
Databricks is on a mission to make stream processing faster, more consistent and easier to use for our customers, so we're building out new connectors and adding new functionality to our existing ones as part of the overall effort to develop the next generation of Structured Streaming. We're excited to announce that the Kinesis connector in the Databricks Runtime now supports Enhanced Fan-out (EFO) for Kinesis Data Streams.
Why does this matter? Our customers utilize Structured Streaming to power business-critical ETL workloads, but analytics and ML aren't the only uses for that data – there might be any number of other applications which consume from a given Kinesis stream. With support for EFO, our customers are now able to consolidate their infrastructure into fewer streams that power both operational and ETL use cases. Our connector still fully supports non-enhanced streams, so our customers retain the choice of when it makes sense to take on the additional cost of running EFO consumers.
Overview of Kinesis Data Streams
Since this is meant to be a technical blog, we're going to get into the details of how this all works, starting with an overview of Amazon Kinesis Data Streams (KDS).
KDS is a serverless streaming data service that makes it easy to capture, process, and store data streams at any scale. KDS serves as the backbone of custom streaming applications that collect from sources like application logs, social media feeds, and clickstream data. Data is put into Kinesis Data Streams, which ensures durability and elasticity. The managed service aspect of Kinesis Data Streams relieves users of the operational burden of creating and running a data intake pipeline. The elasticity of Kinesis Data Streams enables you to scale the stream up or down, so that you never lose data records before they expire.
Consumer modes
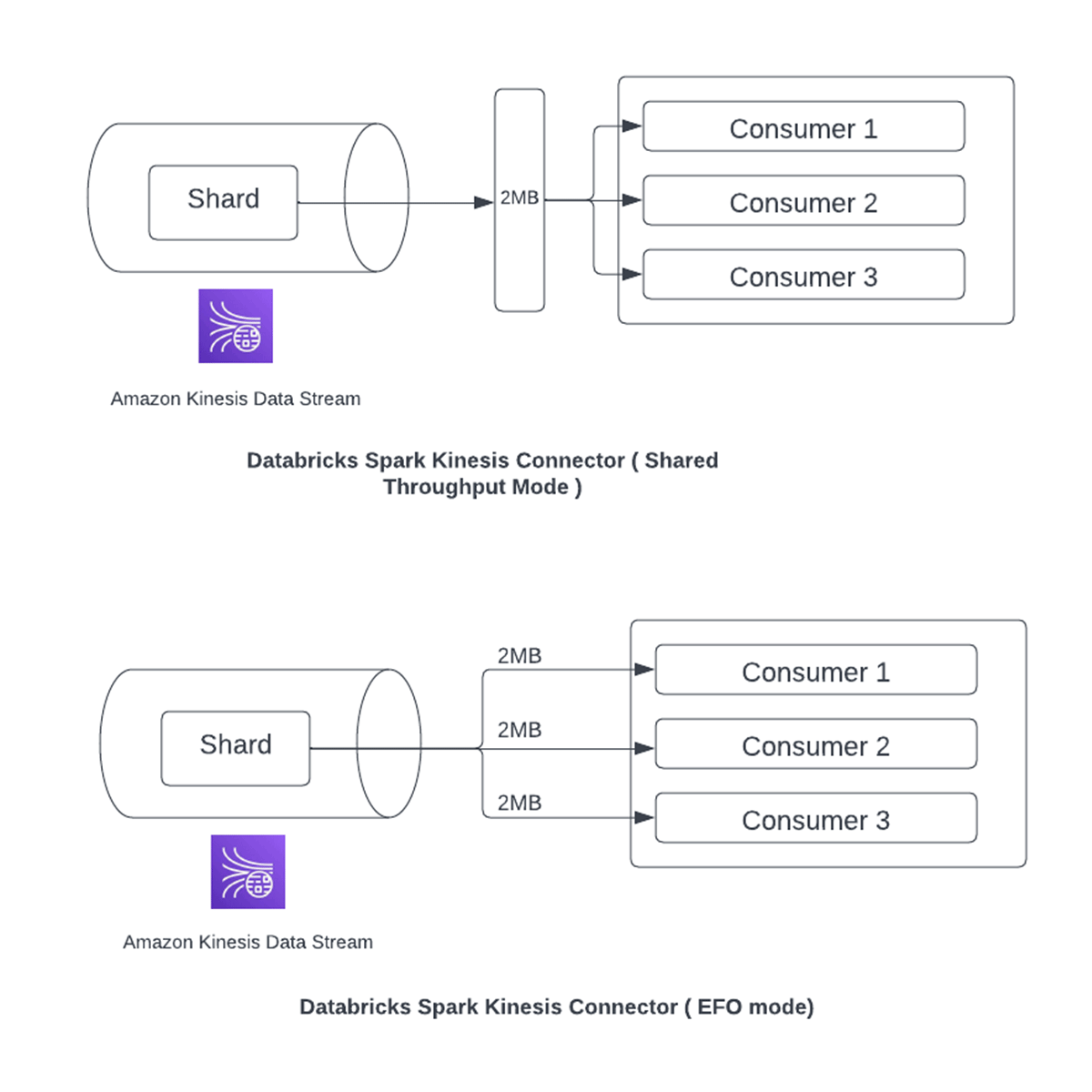
KDS achieves throughput parallelism through the concept of shards, each of which contains a sequence of messages or records. There are two different ways to consume data from shards:
- Shared Throughput Mode: This is the default mode. Every shard in a stream provides a maximum of 2MB/sec of read throughput. This throughput is shared amongst consumers reading from a shard. Therefore, if multiple applications consume messages from a shard then 2MB/sec of read throughput gets shared amongst them.
- Enhanced Fan-Out (Dedicated Throughput) Mode: As part of this mode, every application reading from a shard is registered as a consumer and gets 2MB/sec read throughput individually. This allows multiple applications to read in parallel from a shard without sharing the read throughput which in turns improves processing performance.
- Note: there is a limit of 20 registered consumers for each enhanced stream and an associated data retrieval cost
Databricks Kinesis connector
The Kinesis connector in the Databricks Runtime previously supported only Shared Throughput Mode along with support for resharding (both merging & splitting shards). It's built on the Kinesis APIs and uses the AWS Java SDK.
With the release of Databricks Runtime 11.3 LTS, the Kinesis connector now supports streams that utilize EFO.
The following configurations are introduced to enable and configure this feature:
- streamName - A comma-separated list of stream names.
- Default: None (This is a mandatory parameter)
- region - Region for the streams to be specified.
- Default: Locally resolved region
- initialPosition - Defines where to start reading from in the stream.latest,.
- Default: latest
- Possible Values: latest, trim_horizon, earliest , at_timestamp
- consumerMode - Consumer type to run the streaming query with..
- Default: polling
- Possible Values: polling or efo
Here is a Scala example of a Structured Streaming application reading from a Kinesis data stream utilizing EFO and writing to a Delta Lake table:
Running in Enhanced Fan-out (EFO) mode
Here is some useful information to consider while running streaming pipelines in EFO mode.
Consumer Registration
- Amazon Kinesis requires consumers to be registered explicitly for use with EFO mode
- The Databricks Kinesis connector offers the option to either register a new consumer or reuse an existing consumer
- The consumer name is an optional field. If one is explicitly provided with the streaming query, that name is used as the EFO consumer name. If one is not provided, then the unique query identifier associated with the streaming query is used as the consumer name
- If the EFO consumer with the above name is already registered with Amazon Kinesis, then that consumer is used directly. Otherwise, a new EFO consumer is registered with Amazon Kinesis.
- For example, to register a new consumer with name "testConsumer" for stream "testStream", you could write the query as
Consumer De-registration
- Similar to registration, Kinesis EFO consumers also need to be de-registered explicitly to avoid incurring hourly charges per consumer
The Databricks Kinesis connector provides a couple of options to perform this de-registration from within the Databricks platform:
- One option is to set the "requireConsumerDeregistration" flag to true, which would perform the consumer de-registration on query exit on a best-effort basis. If the Databricks Runtime de-registers the consumer because a query stops or fails, then the query runs again, it will create a consumer with the same name, but with a different ARN. If you rely on the consumer ARN for any reason, do not use this automatic de-registration functionality
- Note: it is possible for the consumer de-registration to fail because of situations like program crashes and network outages, so we recommend that customers still periodically check on all registered consumers to ensure that there are no orphaned consumers incurring costs unnecessarily
- The other option is to run the offline consumer management utility from within a Databricks notebook that allows you to list, register and de-register consumers associated with a Kinesis data stream on an ad-hoc basis.
- One option is to set the "requireConsumerDeregistration" flag to true, which would perform the consumer de-registration on query exit on a best-effort basis. If the Databricks Runtime de-registers the consumer because a query stops or fails, then the query runs again, it will create a consumer with the same name, but with a different ARN. If you rely on the consumer ARN for any reason, do not use this automatic de-registration functionality
Combining polling and EFO consumers
- Amazon Kinesis allows for the use of both types of consumers for the same stream at the same time
- Note: polling mode consumers are still subject to the same 2MB/s throughput limit that is shared amongst all such consumers
- The Databricks Kinesis connector also allows for running both consumer types in parallel by simply providing the same kinesis stream name and different consumer modes, as required on a per query basis.
Reference architecture
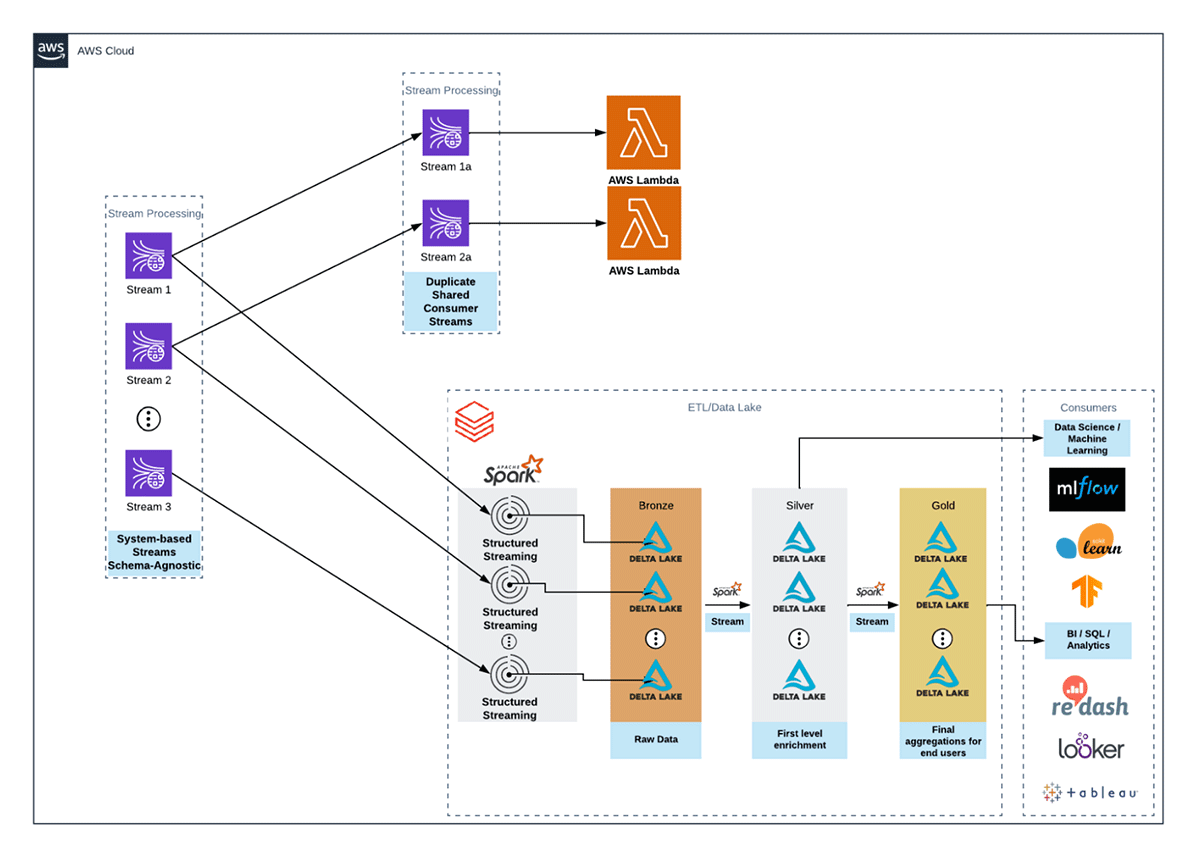
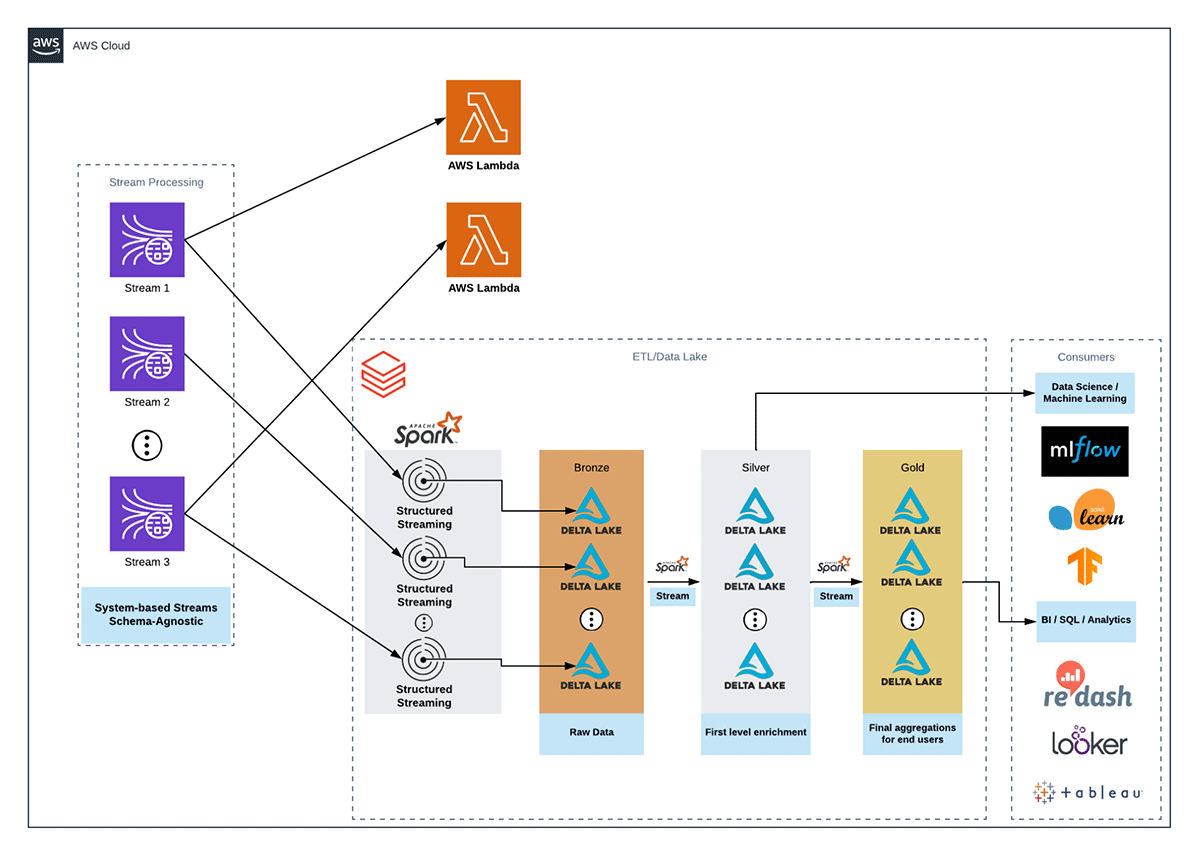
This reference architecture shows how many of our customers currently utilize Kinesis within their data ecosystem. They have both Spark-based consumers like Structured Streaming applications for ETL and non-Spark consumers like Lambda functions for operational use cases.
If we take an example of a streaming video service, it emits a number of events, whether produced by the user (watch events like pause, play, exit, etc.) or the application itself (dropped frames, video stream buffering, etc.). If we separate use cases based on operational vs. ETL, consumers of the same data may look something like this:
- Operational: the SRE team may have health checks in place that utilize watch events that occur from a given user and other telemetry from the application, which may require immediate action if they fail. These use cases are typically machine-to-machine and may also include real-time dashboarding, so the latency sensitivity is high. These data aren't typically persisted for very long due to the expense of reduced latency
- ETL: there might be analytics / ML teams who want to utilize the same watch events and application telemetry to run descriptive analyses for reporting or predictive analyses for things like anomaly detection and churn. Their latency sensitivity is much lower, but they need the data to go back much farther historically and they need it to be durable
For the ETL use cases, our customers write the data out with as few transformations as possible into a bronze Delta Lake table. These are typically stateless or map-only jobs, which read the data from a Kinesis data stream, deserialize it, then write out to Delta Lake. This pattern holds, irrespective of whether the Kinesis data stream is in shared throughput mode or EFO mode. Notice that with EFO mode, the architecture is simpler because users will no longer have to duplicate streams to sidestep the lack of EFO support in the Databricks Kinesis connector. The subsequent jobs read from the bronze Delta Lake table as a streaming source and incrementally transform new records into silver and gold tables for consumption.
Why Delta Lake? Its canonical use case was streaming ETL and analytics – the ACID properties combined with Structured Streaming's fault tolerance make recovery painless and a simple API to compact files asynchronously after writes alleviates the small files problem for downstream readers. It's a simple-to-use open storage format that provides users a way to reliably process large volumes of data for a wide variety of use cases.
Conclusion
Support for EFO gives Kinesis users on Databricks a way to simplify their infrastructure by having both Spark and non-Spark workloads consume from the same streams without competing for throughput capacity. As companies continue to develop operational capabilities that rely on streaming data sources, infrastructure simplicity is one of the keys to scalability. One fewer duplicated stream is one fewer item to manage and one fewer point of failure. As we expand our connector ecosystem and simplify stream processing as part of Project Lightspeed, please keep an eye out for new features that will make your lives easier!

