Skip to main content![Nicolas Poggi]()
![Announcing GA of Predictive I/O for Updates: Faster DML Queries, Right Out of the Box]()
![db-165-intel-xeon-og]()
![Meltdown and Spectre's Performance Impact on Big Data Workloads in the Cloud]()
![Company Blog]()

Nicolas Poggi
Nicolas Poggi's posts
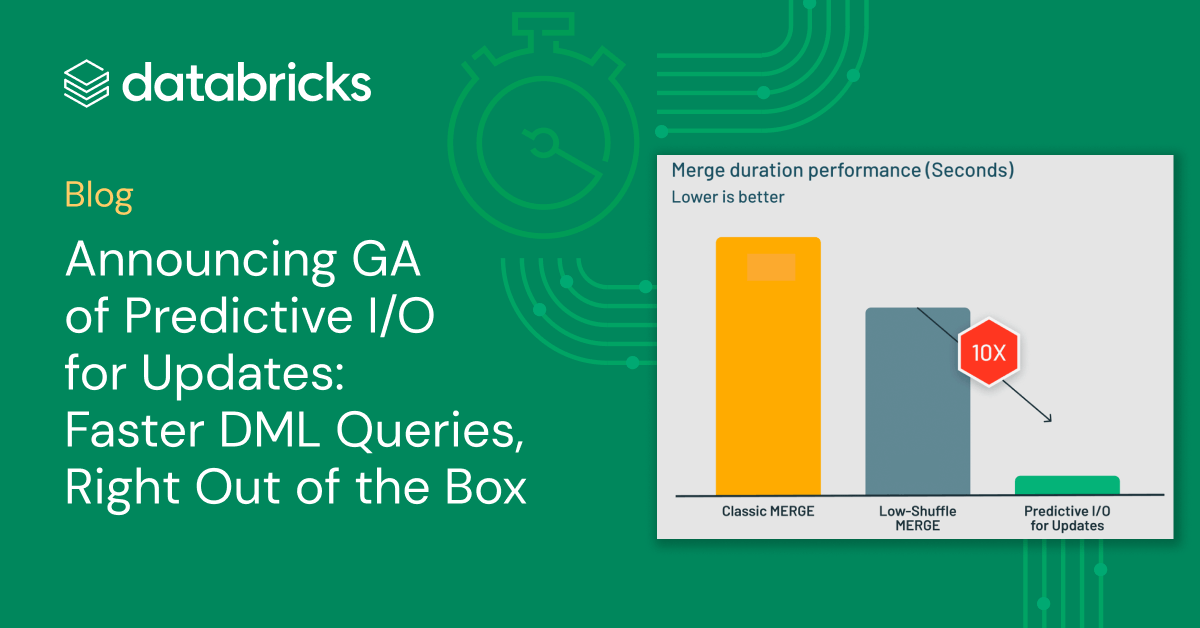
Platform & Products & Announcements
November 2, 2023/4 min read
Announcing GA of Predictive I/O for Updates: Faster DML Queries, Right Out of the Box

Product
May 17, 2022/4 min read
Reduce Time to Decision With the Databricks Lakehouse Platform and Latest Intel 3rd Gen Xeon Scalable Processors


Open Source
January 13, 2018/7 min read
Meltdown and Spectre's Performance Impact on Big Data Workloads in the Cloud

Events
September 20, 2017/Less than a minute