Announcing GA of Predictive I/O for Updates: Faster DML Queries, Right Out of the Box
Over 15 trillion unnecessary row writes prevented, and we’re just getting started.
We’re excited to announce the General Availability of Predictive I/O for updates.
This capability harnesses Photon and Lakehouse AI in order to significantly speed up Data Manipulation Language (DML) operations like MERGE, UPDATE and DELETE, with no performance changes to read queries.
Predictive I/O for updates accomplishes this through an AI model that intelligently applies Deletion Vectors, a Delta Lake capability, which allows for the tracking of deleted rows through hyper-optimized bitmap files. The net result is significantly faster queries with significantly less overhead for data engineering teams.
Shortly following GA, we will enable Predictive I/O for updates by default on new tables. To immediately opt-in, refer to our documentation or the steps at the very end of this post.
Traditional approaches: pick your poison
Traditionally, there have been two approaches to processing DML queries, each of which had different strengths and weaknesses.
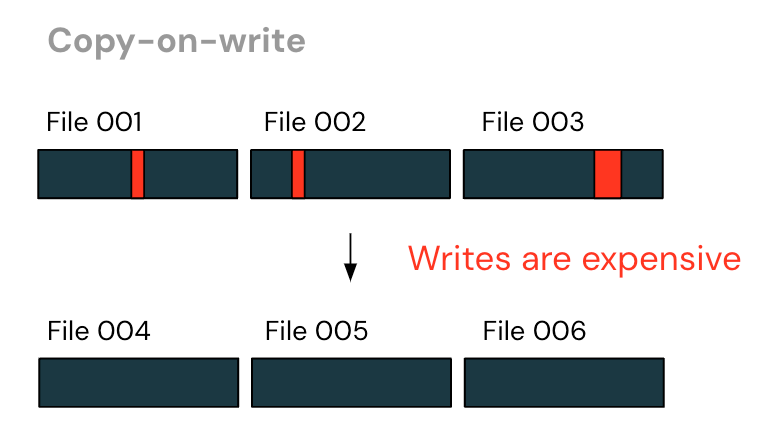
The first, most common approach is “copy-on-write”. Query engines would identify the files that contain the rows needing modification, and then rewrite all unmodified rows to a new file - filtering out the deleted rows and adding updated ones.
Under this approach, writes can be very expensive. It is common that with DML queries, only a few rows are modified. With copy-on-write, this results in a rewrite of nearly the entire file - even though very little has changed!
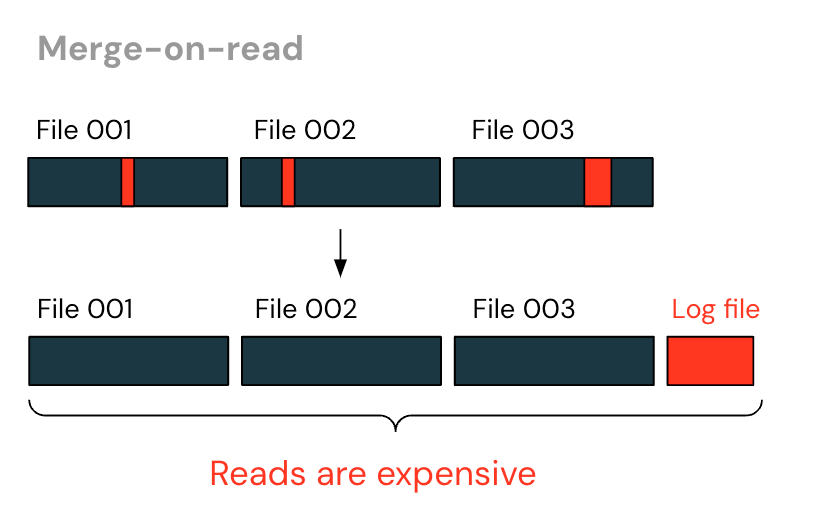
An alternative approach is “merge-on-read”. Instead of rewriting the entire file, log files are written that track rows that were deleted. The reader then pieces together the table by reading both the data files and the additional log files.
With merge-on-reads, writes are much faster - no more rewriting unchanged files. However, reads become increasingly expensive over time as larger log files are generated, all of which the reader must piece together. The end user also has to determine when to “purge” those log files - rewriting the log files and data files into a new data file - in order to return to maintain reasonable read performance.
The end result: the traditional approaches both have their own strengths and weaknesses, forcing you to “pick your poison”. For each table, you need to ask: is copy-on-write or merge-on-read better for this use case? And if you went with the latter, how often should you purge your log files?
Introducing Predictive I/O for updates - AI provides the best of all worlds
Predictive I/O for updates delivers the best of all worlds - lightning-fast DML operations and great read performance, all without the need for users to decide when to “purge” the log files. This is achieved using an AI model to automatically determine when to apply and purge Delta Lake Deletion Vectors.
The agentic AI playbook for the enterprise

The tables written by Predictive I/O for updates remain in the open Delta Lake format, readable by the Delta Lake ecosystem of connectors, including Trino and Spark running OSS Delta 2.3.0 and above.
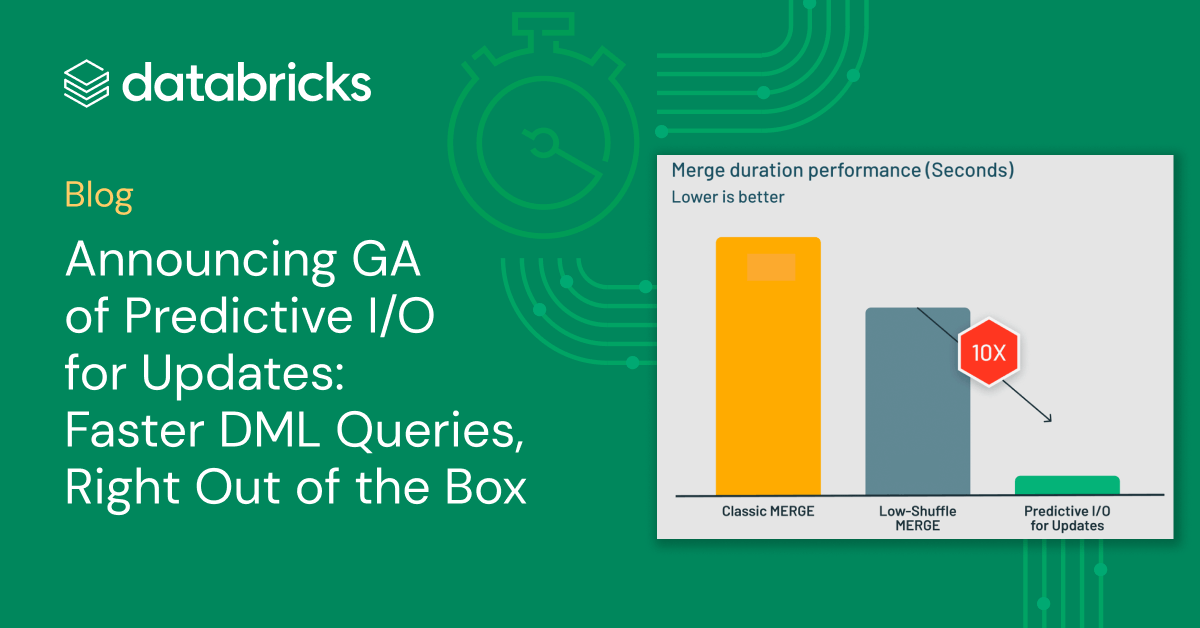
In benchmarks of typical Data Warehousing MERGE workloads, Predictive I/O for updates delivers 10x performance improvements over the Low-Shuffle Merge technique used by Photon before.
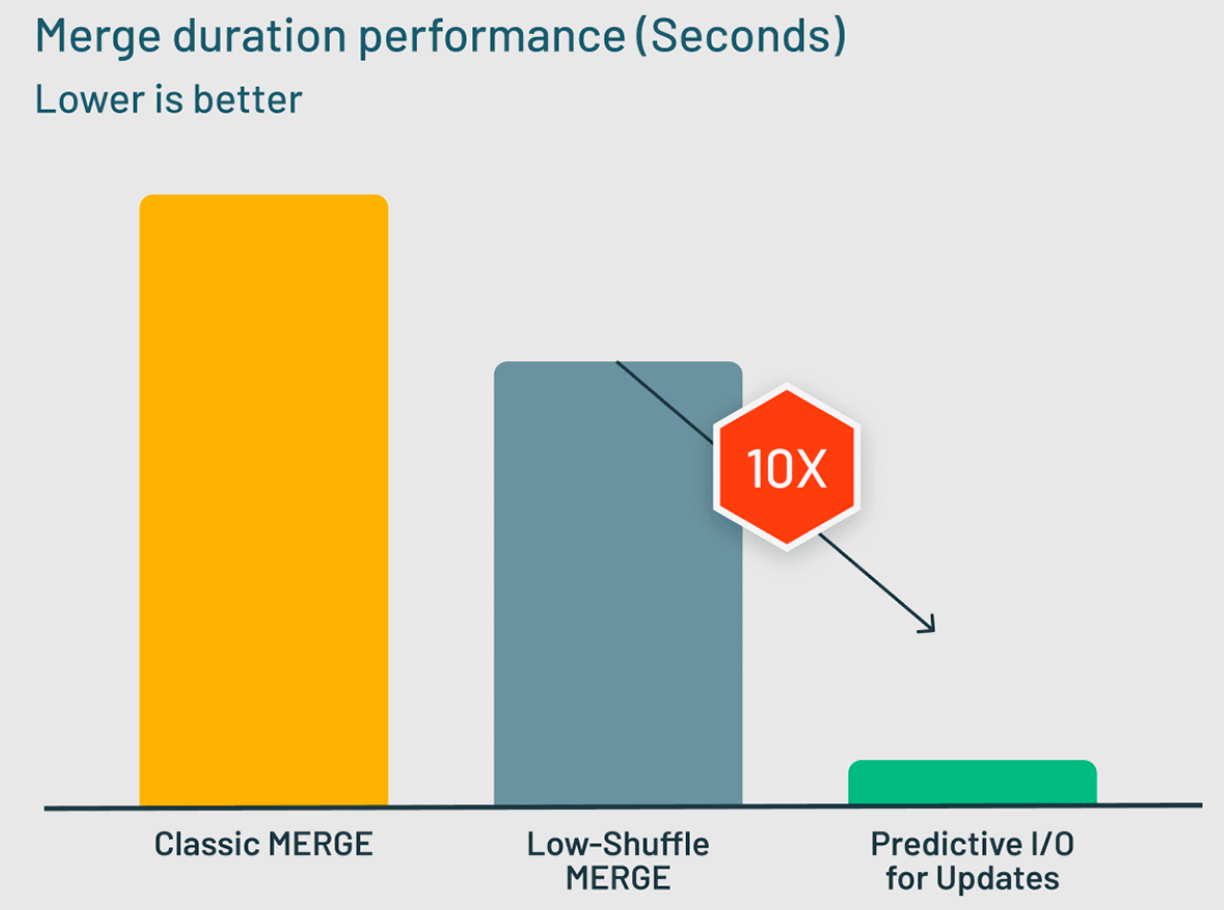
Since the Public Preview of Predictive I/O for updates was announced in April, we’ve worked with hundreds of customers who have successfully used the capability to get massive performance gains on their DML queries.
During that time, Predictive I/O for updates has written many billions of Deletion Vectors, and we’ve used that data to further refine the AI models which are used to determine when best to apply Deletion Vectors. We’ve found that in total, Deletion Vectors have prevented the needless rewrites of over 15 trillion rows, which would’ve otherwise been written under copy-on-write approaches. It is no wonder that customers reported significant speedups on their DML workloads:
"Predictive I/O for updates has helped us significantly speed up our DML operations, reducing compute costs and accelerating time-to-insight. We’re happy that this capability has been set-and-forget, freeing up our time to focus on getting business value from our data." -- Antonio del Rio, Data Engineering, Avoristech
Coming soon: Predictive I/O for updates enabled right out of the box for newly created tables
The promising results from Public Preview have given us the confidence not only to take the capability to General Availability but also to begin enabling Predictive I/O by default for newly created tables. These changes will also apply to enabling Deletion Vectors even for clusters without Photon enabled - which should still see a performance boost (though smaller in magnitude than Predictive I/O for updates).
This improvement will help you get performance improvements right out of the box without needing to remember to set the associated table properties.
You can enable Predictive I/O for updates across your workloads through a new workspace setting. This setting is available now on Azure and AWS, and will be available in GCP coming soon. To access it:
- As a workspace admin, go to Admin Settings for the workspace
- Select the Workspace settings tab
- Go to the setting titled Auto-Enable Deletion Vectors
This setting takes effect for all Databricks SQL Warehouses and clusters with Databricks runtime 14.0+.
Alternatively, this same setting can be used to opt out of enablement by default, by simply setting the setting to Disabled.
Enable Predictive I/O today to bring the power of AI to supercharge your DML queries! And look out for more AI-powered Databricks capabilities soon to come.