
Large language models are improving rapidly; to date, this improvement has largely been measured via academic benchmarks. These benchmarks, such as MMLU and BIG-Bench, have been adopted by researchers in an attempt to compare models across various dimensions of capability related to general intelligence. However enterprises care about the quality of AI systems in specific domains, which we call domain intelligence. Domain intelligence involves data and tasks that deal with the inner workings of business processes: details, jargon, history, internal practices and workflows, and the like.
Therefore, enterprise practitioners deploying AI in real-world settings need evaluations that directly measure domain intelligence. Without domain-specific evaluations, organizations may overlook models that would excel at their specialized tasks in favor of those that score well on possibly misaligned general benchmarks. We developed the Domain Intelligence Benchmark Suite (DIBS) to help Databricks customers build better AI systems for their specific use cases, and to advance our research on models that can leverage domain intelligence. DIBS measures performance on datasets curated to reflect specialized domain knowledge and common enterprise use cases that traditional academic benchmarks often overlook.
In the remainder of this blog post, we will discuss how current models perform on DIBS in comparison to comparable academic benchmarks. Our key takeaways include:
- Models’ rankings across academic benchmarks do not necessarily map to their rankings across industry tasks. We find discrepancies in performance between academic and enterprise rankings, emphasizing the need for domain-specific testing.
- There is room for improvement in core capabilities. Some enterprise needs like structured data extraction show clear paths for improvement, while more complex domain-specific tasks require more sophisticated reasoning capabilities.
- Developers should choose models based on specific needs. There is no single best model or paradigm. From open-source options to retrieval strategies, different solutions excel in different scenarios.
This underscores the need for developers to test models on their actual use cases and avoid limiting themselves to any single model option.
Introducing our Domain Intelligence Benchmark Suite (DIBS)
DIBS focuses on three of the most common enterprise use cases surfaced by Databricks customers:
- Data Extraction: Text to JSON
- Converting unstructured text (like emails, reports, or contracts) into structured JSON formats that can be easily processed downstream.
- Tool Use: Function Calling
- Enabling LLMs to interact with external tools and APIs by generating properly formatted function calls.
- Agent Workflows: Retrieval Augmented Generation (RAG)
- Enhancing LLM responses by first retrieving relevant information from a company's knowledge base or documents.
We evaluated fourteen popular models across DIBS and three academic benchmarks, spanning enterprise domains in finance, software, and manufacturing. We are expanding our evaluation scope to include legal, data analysis and other verticals, and welcome collaboration opportunities to assess additional industry domains and tasks.
In Table 1, we briefly provide an overview of each task, the benchmark we have been using internally, and academic counterparts if available. Later, in Benchmark Overviews, we discuss these in more detail.
| Task Category | Dataset Name | Enterprise or Academic | Domain | Task Description |
|---|---|---|---|---|
|
Data Extraction: Text to JSON |
Text2JSON | Enterprise | Misc. Information | Given a prompt containing a schema and a few Wikipedia-style paragraphs, extract relevant information into the schema. |
| Tool Use: Function Calling | BFCL-Full Universe | Enterprise | Function calling | Modification of BFCL where, for each query, the model has to select the correct function from the full set of functions present in the BFCL universe. |
| Tool Use: Function Calling | BFCL-Retrieval | Enterprise | Function calling | Modification of BFCL where, for each query, we use text-embedding-3-large to select 10 candidate functions from the full set of functions present in the BFCL universe. The task then becomes to choose the correct function from that set. |
| Tool Use: Function Calling | Nexus | Academic | APIs | Single turn function calling evaluation across 7 APIs of varying difficulty |
| Tool Use: Function Calling |
Berkeley Function Calling Leaderboard (BFCL) |
Academic | Function calling | See original BFCL blog. |
|
Agent Workflows: RAG |
DocsQA | Enterprise | Software - Databricks Documentation with Code | Answer real user questions based on public Databricks documentation web pages. |
|
Agent Workflows: RAG |
ManufactQA | Enterprise |
Manufacturing - Semiconductors -Customer FAQs |
Given a technical customer query about debugging or product issues, retrieve the most relevant page from a corpus of hundreds of product manuals and datasheets, and construct an answer like a customer support agent. |
|
Agent Workflows: RAG |
FinanceBench | Enterprise | Finance - SEC Filings | Perform financial analysis on SEC filings, from Patronus AI |
|
Agent Workflows: RAG |
Natural Questions | Academic | Wikipedia | Extractive QA over Wikipedia articles |
Table 1. We evaluate the set of models across 9 tasks spanning 3 enterprise task categories: data extraction, tool use, and agent workflows. The three categories we discuss were selected due to their relative frequency in enterprise workloads. Beyond these categories, we are continuing to expand to a broader set of evaluation tasks in collaboration with our customers.
What We Learned Evaluating LLMs on Enterprise Tasks
Academic Benchmarks Obscure Enterprise Performance Gaps
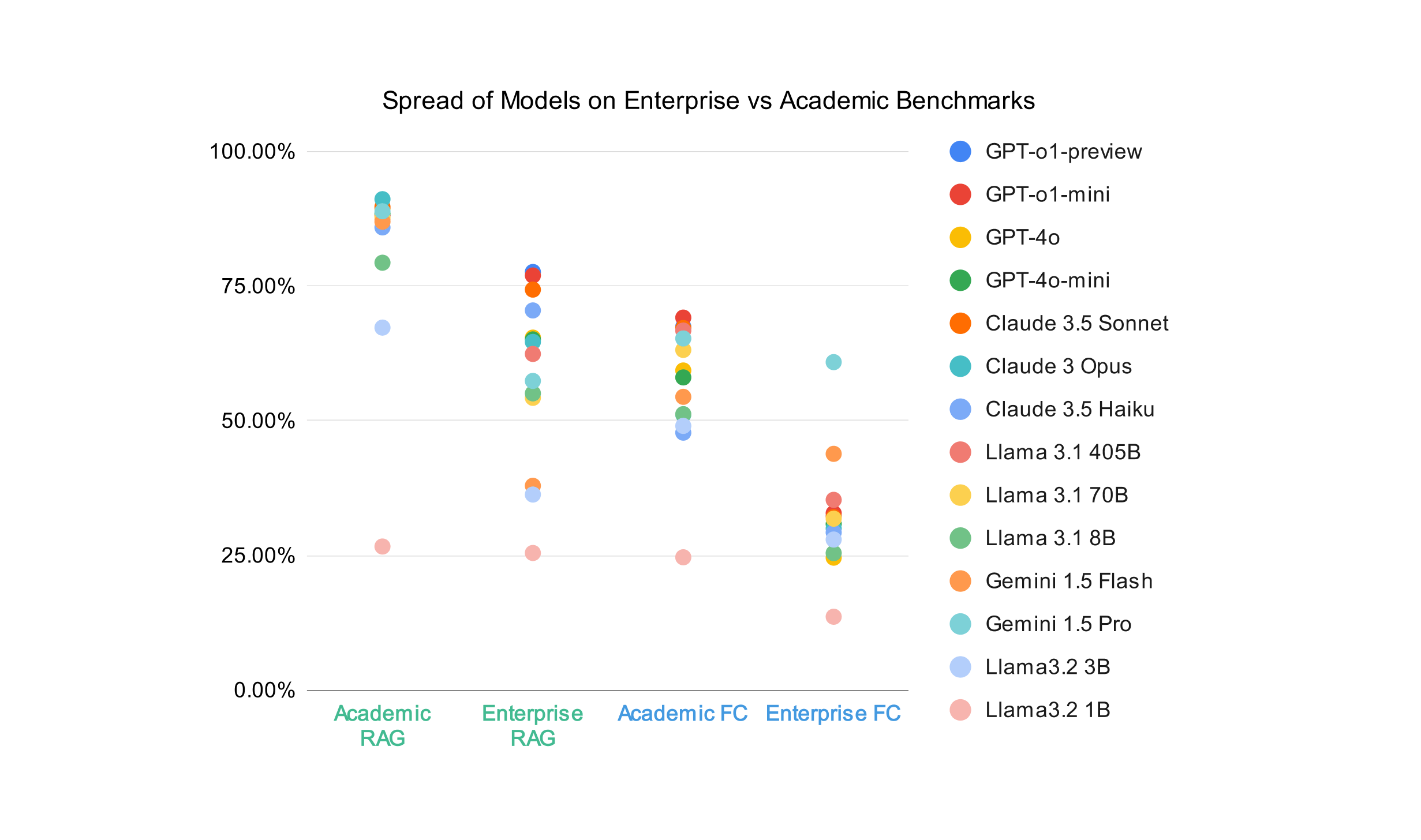
In Figure 1, we show a comparison of RAG and function calling (FC) capabilities between the enterprise and academic benchmarks, with average scores plotted for all fourteen models. While the academic RAG average has a larger range (91.14% at the top, and 26.65% at the bottom), we can see that the vast majority of models score between 85% and 90%. The enterprise RAG set of scores has a narrower range, because it has a lower ceiling – this reveals that there is more room to improve in RAG settings than a benchmark like NQ might suggest.
Figure 1 visually reveals wider performance gaps in enterprise RAG scores, shown by the more dispersed distribution of data points, in contrast to the tighter clustering seen in the academic RAG column. This is most likely because academic benchmarks are based on general domains like Wikipedia, are public, and are several years old - therefore, there is a high probability that retrieval models and LLM providers have already trained on the data. For a customer with private, domain specific data though, the capabilities of the retrieval and LLM models are more accurately measured with a benchmark tailored to their data and use case. A similar effect can be observed, though it is less pronounced, in the function calling setting.
Structured Extraction (Text2JSON) presents an achievable target
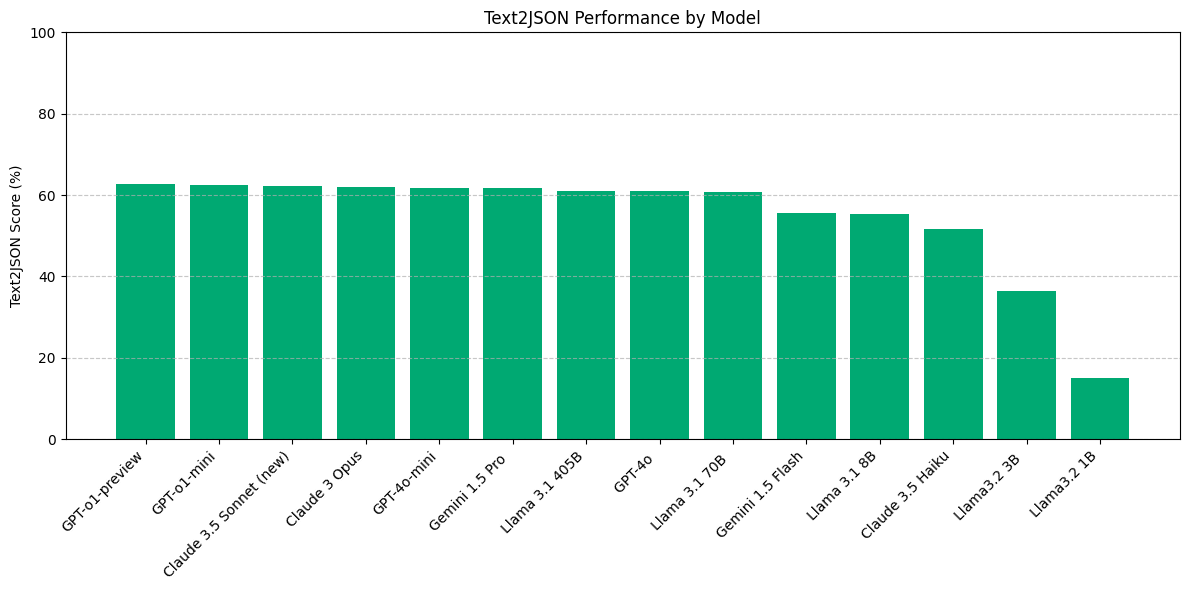
At a high level, we see that most models have significant room for improvement in prompt-based Text2JSON; we did not evaluate model performance when using structured generation.
Figure 2 shows that on this task, there are three distinct tiers of model performance:
- Most closed-source models as well as Llama 3.1 405B and 70B score around just 60%
- Claude 3.5 Haiku, Llama 3.1 8B and Gemini 1.5 Flash bring up the middle of the pack with scores between 50% and 55%.
- The smaller Llama 3.2 models are much worse performers.
Taken together, this suggests that prompt-based Text2JSON may not be adequate for production use off-the-shelf even from leading model providers. While structured generation options are available, they may impose restrictions on viable JSON schemas and be subject to different data usage stipulations. Fortunately, we have had success fine-tuning models to improve at this capability.
Other tasks may require more sophisticated capabilities
We also found FinanceBench and Function Calling with Retrieval to be challenging tasks for most models. This is likely because the former requires a model to be proficient with numerical complexity, and the latter requires an ability to ignore distractor information.
No Single Model Dominates all Tasks
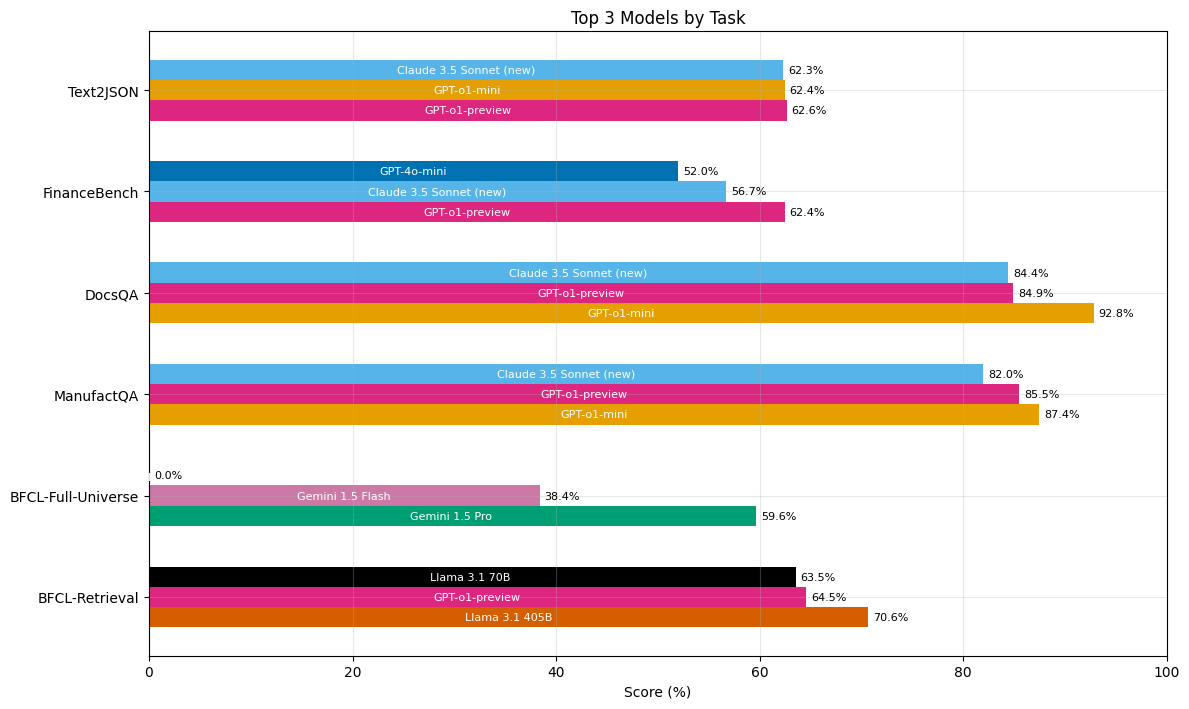
Our evaluation results do not support the claim that any one model is strictly superior to the rest. Figure 3 demonstrates that the most consistently high-performing models were o1-preview, Claude Sonnet 3.5 (New), and o1-mini, achieving top scores in 5, 4, and 3 out of the 6 enterprise benchmark tasks respectively. These same three models were overall the best performers for data extraction and RAG tasks. However, only Gemini models currently have the context length necessary to perform the function calling task over all possible functions. Meanwhile, Llama 3.1 405B outperformed all other models on the function calling as retrieval task.
Small models were surprisingly strong performers: they mostly performed similarly to their larger counterparts, and sometimes significantly outperformed them. The only notable degradation was between o1-preview and o1-mini on the FinanceBench task. This is interesting given that, as we can see in Figure 3, o1-mini outperforms o1-preview on the other two enterprise RAG tasks. This underscores the task-dependent nature of model selection.
Open Source vs. Closed Source Models
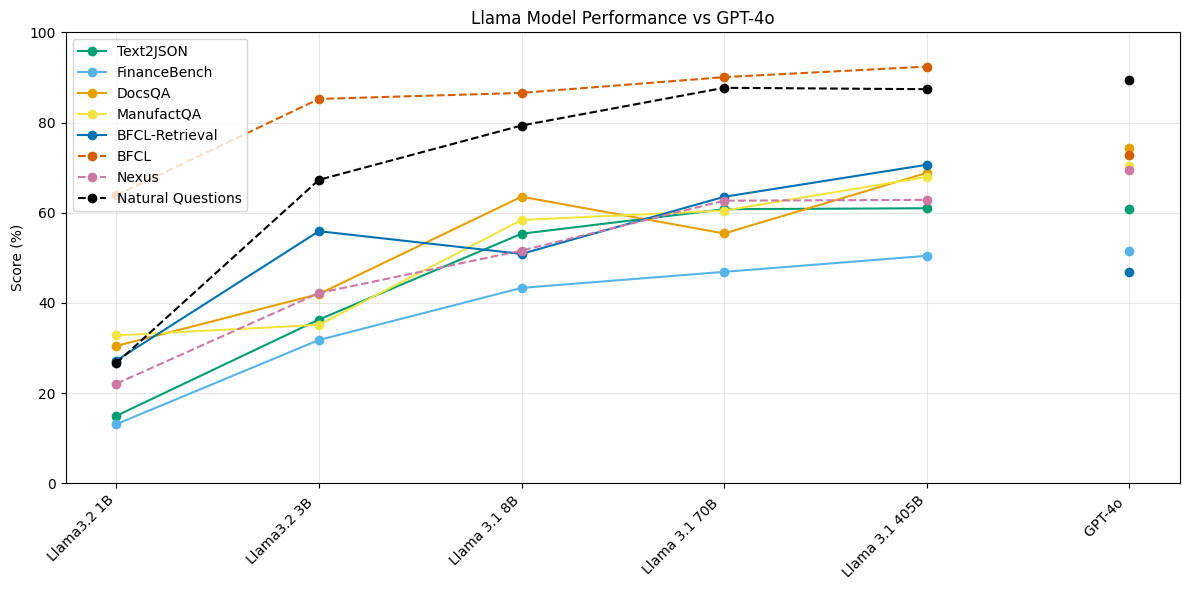
We evaluated five different Llama models, each at a different size. In Figure 4, we plot the scores of each of these models on each of our benchmarks against GPT-4o’s scores for comparison. We find that Llama 3.1 405B and Llama 3.1 70B perform extremely competitively on Text2JSON and Function Calling tasks as compared to closed-source models, surpassing or performing similarly to GPT 4o. However, the gap between these model classes is more pronounced on RAG tasks.
Additionally, we note that Llama 3.1 and 3.2 series of models show diminishing returns regarding model scale and performance. The performance gap between Llama 3.1 405B and Llama 3.1 70B is negligible on the Text2JSON task, and significantly smaller on every other task than Llama 3.1 8B. However, we observe that Llama 3.2 3B outperforms Llama 3.1 8B on the function calling with retrieval task (BFCL-Retrieval in Figure 4).
This implies two things. First, open-source models are off-the-shelf viable for at least two high-frequency enterprise use cases. Second, there is room to improve these models’ ability to leverage retrieved information.
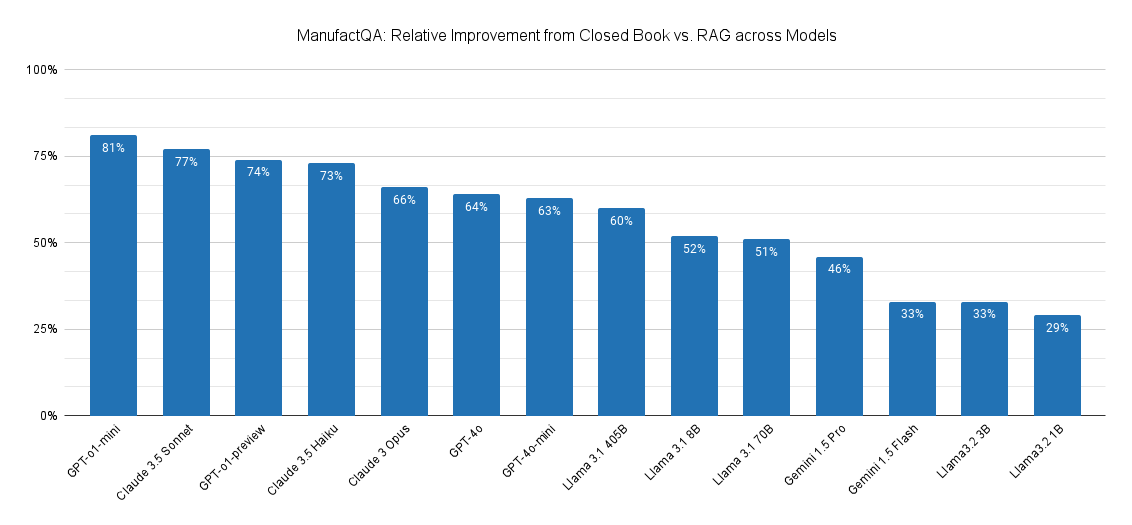
To further investigate this, we compared how much better each model would perform on ManufactQA under a closed book setting vs. a default RAG setting. In a closed book setting, models are asked to answer the queries without any given context - which measures a model’s pretrained knowledge. In the default RAG setting, the LLM is provided with the top 10 documents retrieved by OpenAI’s text-embedding-3-large, which had a recall@10 of 81.97%. This represents the most realistic configuration in a RAG system. We then calculated the relative error reduction between the rag and closed book settings.
Based on Figure 5, we observe that the GPT-o1-mini (surprisingly!) and Claude-3.5 Sonnet are able to leverage retrieved context the most, followed by GPT-o1-preview and Claude 3.5 Haiku. The open source Llama models and Gemini models all trail behind, suggesting that these models have more room to improve in leveraging domain specific context for RAG.
For function calling at scale, high quality retrieval may be more valuable than larger context windows.
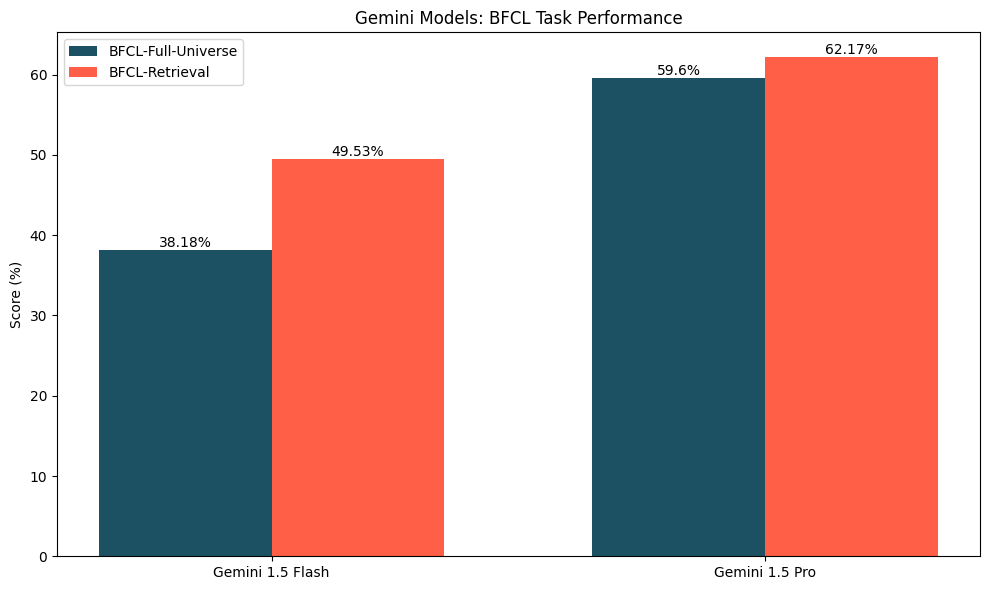
Our function calling evaluations show something interesting: just because a model can fit an entire set of functions into its context window does not mean that it should. The only models capable of doing this at this time are Gemini 1.5 Flash and Gemini 1.5 Pro; as Figure 6 displays, those models perform better on the function calling with retrieval variant, where a retriever selects a subset of the full set of functions relevant to the query. The improvement in performance was more remarkable for Gemini 1.5 Flash (~11% improvement) than for Gemini 1.5 Pro (~2.5%). This improvement likely stems from the reality that a well-tuned retriever can increase the likelihood that the correct function is in the context while vastly reducing the number of distractor functions present. Furthermore, we have previously seen that models may struggle with long-context tasks for a variety of reasons.
Benchmark Overviews
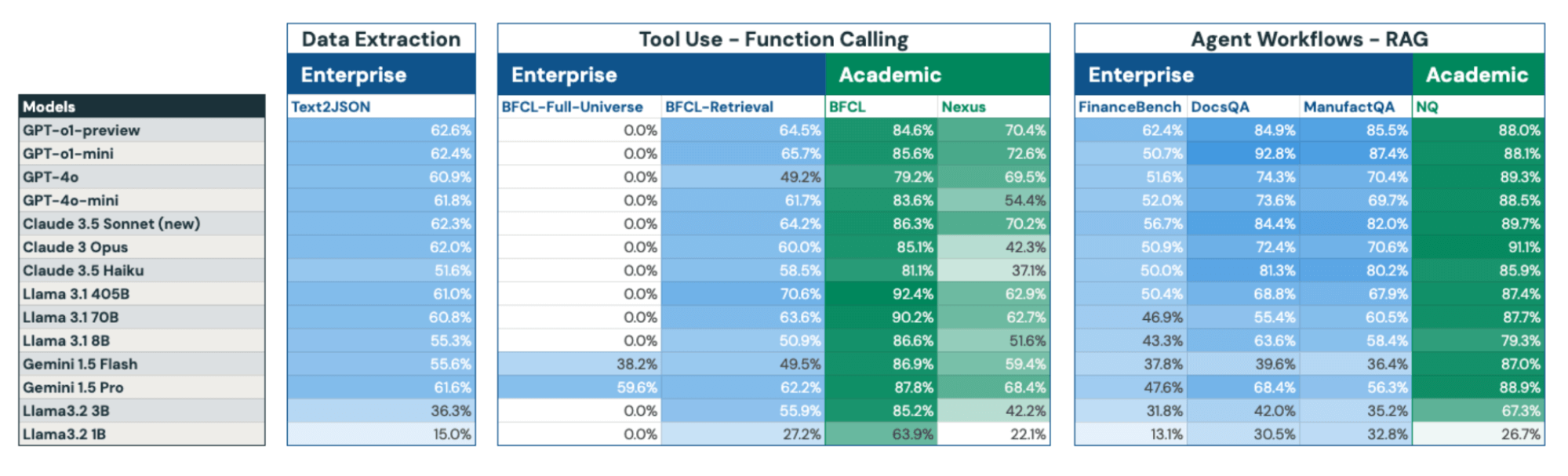
Having outlined DIBS's structure and key findings, we present a comprehensive summary of fourteen open and closed-source models’ performance across our enterprise and academic benchmarks in Figure 7. Below, we provide detailed descriptions of each benchmark in the remainder of this section.
Data Extraction: Text to JSON
In today's data-driven landscape, the ability to transform vast amounts of unstructured data into actionable information has become increasingly valuable. A key challenge many enterprises face is building unstructured data to structured data pipelines, either as standalone pipelines or as part of a larger system.
One common variant we have seen in the field is converting unstructured text – often a large corpus of documents – to JSON. While this task shares similarities with traditional entity extraction and named entity recognition, it goes further – often requiring a sophisticated blend of open-ended extraction, summarization, and synthesis capabilities.
No open-source academic benchmark sufficiently captures this complexity; we therefore procured human-written examples and created a custom Text2JSON benchmark. The examples we procured involve extracting and summarizing information from passages into a specified JSON schema. We also evaluate multi-turn capabilities, e.g. editing existing JSON outputs to incorporate additional fields and information. To ensure our benchmark reflects actual business needs and provides a relevant assessment of extraction capabilities, we used the same evaluation strategies as our customers.
Tool Use: Function Calling
Tool use capabilities enable LLMs to act as part of a larger compound AI system. We have seen sustained enterprise interest in function calling as a tool, and we previously wrote about how to effectively evaluate function calling capabilities.
Recently, organizations have taken to tool calling at a much larger scale. While academic evaluations typically test models with small function sets—often ten or fewer options—real-world applications frequently involve hundreds or thousands of available functions. In practice, this means enterprise function calling is similar to needle-in-a-haystack test, with many distractor functions present during any given query.
To better reflect these enterprise scenarios, we've adapted the established BFCL academic benchmark to evaluate both function calling capabilities and the role of retrieval at scale. In its original version, the BFCL benchmark requires a model to choose one or fewer functions from a predefined set of four functions. We built on top of our previous modification of the benchmark to create two variants: one which requires the model to choose from the full set of functions that exist in BFCL for each query, and one which leverages a retriever to identify ten functions that are the most likely to be relevant.
Agent Workflows: Retrieval-Augmented Generation
RAG makes it possible for LLMs to interact with proprietary documents, augmenting existing LLMs with domain intelligence. In our experience, RAG is one of the most popular ways to customize LLMs in practice. RAG systems are also critical for enterprise agents, because any such agent must learn to operate within the context of the particular organization in which it is being deployed.
While the differences between industry and academic datasets are nuanced, their implications for RAG system design are substantial. Design choices that appear optimal based on academic benchmarks may prove suboptimal when applied to real-world industry data. This means that architects of industrial RAG systems must carefully validate their design decisions against their specific use case, rather than relying solely on academic performance metrics.
Natural Questions remains a popular academic benchmark even as others, such as HotpotQA have fallen out of favor. Both of these datasets deal with Wikipedia-based question answering. In practice, LLMs have indexed much of this information already. For more realistic enterprise settings, we use FinanceBench and DocsQA – as discussed in our earlier explorations on long context RAG – as well as ManufactQA, a synthetic RAG dataset simulating technical customer support interactions with product manuals, designed for manufacturing companies' use cases.
Conclusion
To determine whether academic benchmarks could sufficiently inform tasks relating to domain intelligence, we evaluated a total of fourteen models across nine tasks. We developed a domain intelligence benchmark suite comprising six enterprise benchmarks that represent: data extraction (text to JSON), tool use (function calling), and agentic workflows (RAG). We selected models to evaluate based on customer interest in using them for their AI/ML needs; we additionally evaluated the Llama 3.2 models for more datapoints on the effects of model size.
Our findings show that relying on academic benchmarks to make decisions about enterprise tasks may be insufficient. These benchmarks are overly saturated – hiding true model capabilities – and somewhat misaligned with enterprise needs. Furthermore, the field of models is muddied: there are several models that are generally strong performers, and models that are unexpectedly capable at specific tasks. Finally, academic benchmark performance may lead one to believe that models are sufficiently capable; in reality, there may still be room for improvement towards being production-workload ready.
At Databricks, we are continuing to help our customers by investing resources into more comprehensive enterprise benchmarking systems, and towards developing sophisticated approaches to domain expertise. As part of this, we are actively working with companies to ensure we capture a broad spectrum of enterprise-relevant needs, and welcome collaborations. If you are a company looking to create domain-specific agentic evaluations, please take a look at our Agent Evaluation Framework. If you are a researcher interested in these efforts, consider applying to work with us.