Skip to main content![Michael Carbin]()
![Reranking in Vector Search]()
![Header graphic for long context RAG part 2]()
![Databricks announces significant improvements to the built-in LLM judges in Agent Evaluation]()

Michael Carbin
Michael Carbin's posts

Platform
August 18, 2025/5 min read
Reranking in Mosaic AI Vector Search for Faster, Smarter Retrieval in RAG Agents


AI Research
October 8, 2024/10 min read
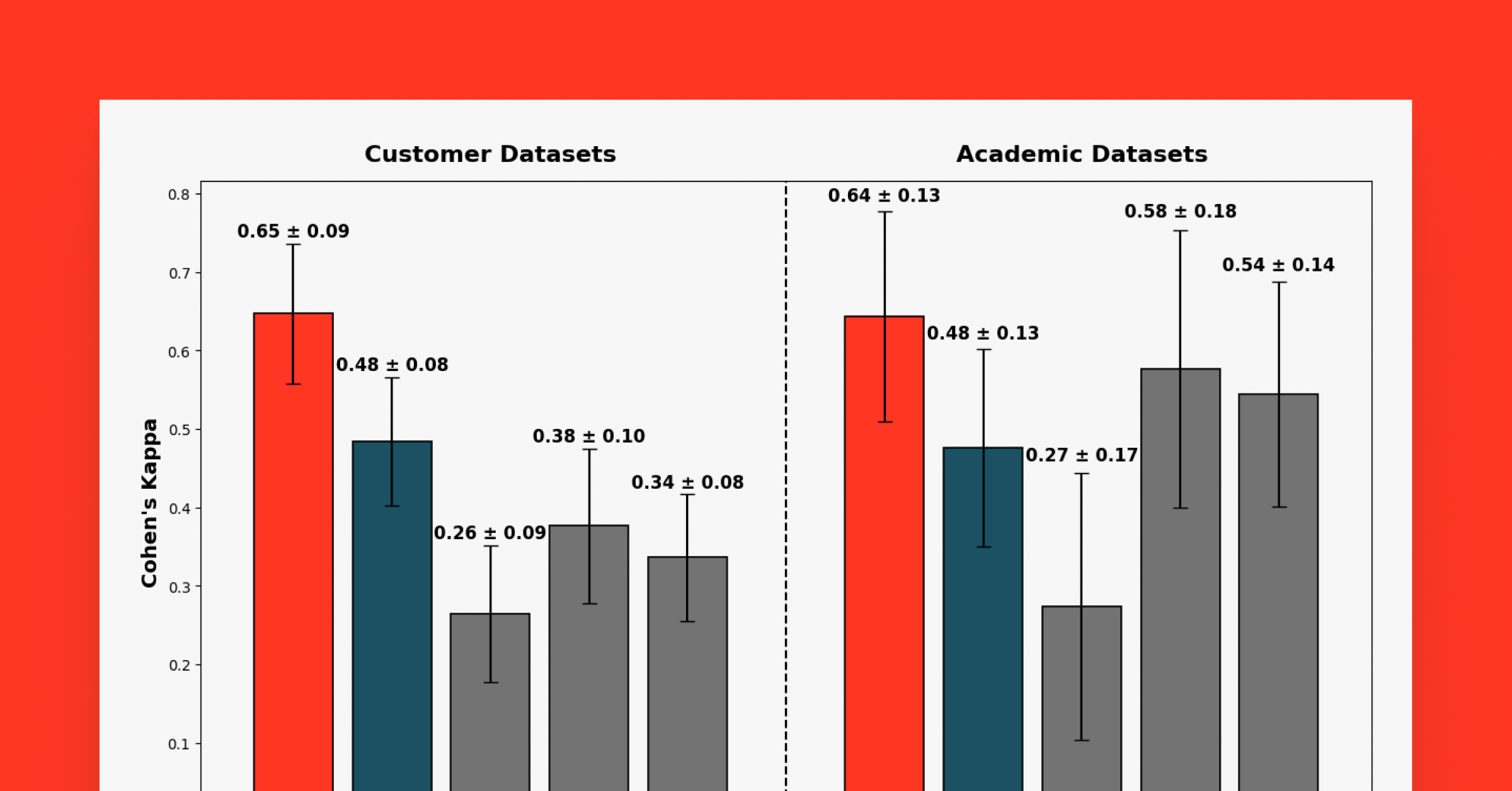
The Long Context RAG Capabilities of OpenAI o1 and Google Gemini
Data Science and ML
September 5, 2024/8 min read


