
At Databricks, we’re committed to building the most efficient and performant training tools for large-scale AI models. With the recent release of DBRX, we’ve highlighted the power of Mixture-of-Experts (MoE) models, which provide a substantial improvement in training and inference efficiency. Today, we’re excited to announce that MegaBlocks, the open-source library used to train DBRX, is becoming an official Databricks project. We are also releasing our MegaBlocks integration into our open source training stack, LLMFoundry. Along with these open source releases, we’re onboarding customers to our optimized internal versions who are ready to get peak performance at scale.
What is a Mixture of Experts Model?
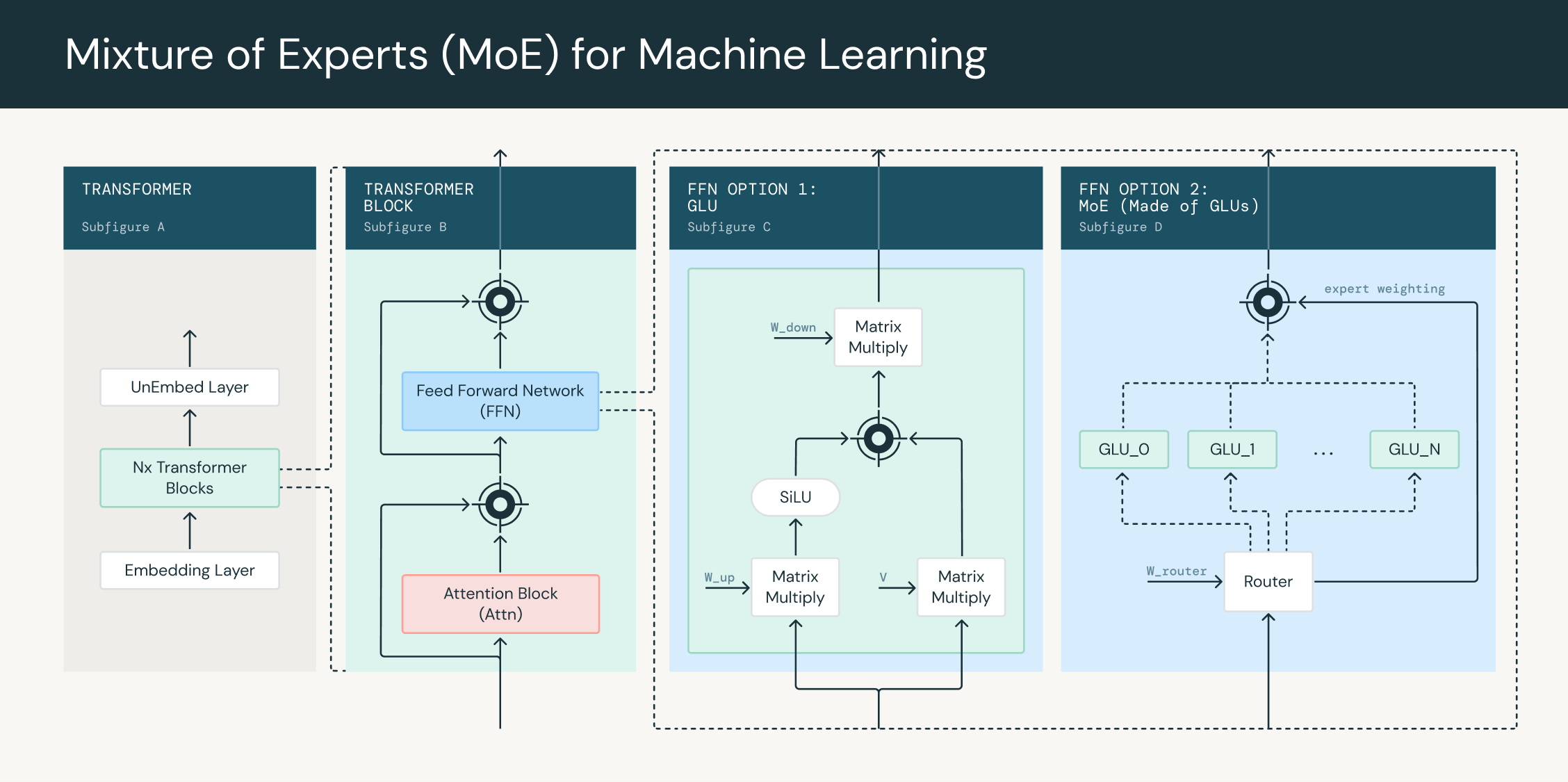
A Mixture of Experts (MoE) model is a machine learning model that combines the outputs of multiple expert networks, or "experts," to make a prediction. Each expert specializes in a specific region of the input space, and a gating network determines how to combine the experts' outputs for a given input.
In the context of transformer networks, each feed-forward block can be replaced with an MoE layer. This layer consists of multiple expert networks, each with its own set of parameters, and a gating network that determines how to weight the outputs of the experts for each input token. The gating network is typically a linear layer feed-forward network that takes in each token as input and produces a set of weights as output. A token assignment algorithm uses these weights to choose which tokens are routed to which experts. During training, the gating network learns to assign inputs to the experts, allowing the model to specialize and improve its performance.
MoE layers can be used to increase the parameter counts of transformer networks without increasing the number of operations used to process each token. This is because the gating network sends tokens to a fraction F < 1 of the total expert set. An MoE network is an N parameter network, but only has to do the computation of an N * F parameter network. For example, DBRX is a 132B parameter model but only has to do as much computation as a 36B parameter model.
Taking Ownership of MegaBlocks
MegaBlocks is an efficient MoE implementation originally created by Trevor Gale as part of his research into sparse training. MegaBlocks introduces the idea of using sparse matrix multiplication to compute all experts in parallel even when a different number of tokens is assigned to each expert. As the project has gained popularity, it has become a core component of numerous stacks, including HuggingFace’s Nanotron, EleutherAI’s GPT-NeoX, Mistral’s reference implementation of Mixtral 8x7B, and of course, our implementation of DBRX.
Databricks is excited to take ownership of this project and provide long term support for the open source community building around it. Trevor will continue to serve as a co-maintainer and actively be involved in the roadmap. We’ve transferred the repository to its new home at databricks/megablocks on GitHub, where we will continue to grow and support the project. Our immediate roadmap focuses on upgrading the project to be production grade, including committing Databricks GPUs for CI/CD and establishing regular release cadences, and ensuring an extensible design to further enable sparsity research. If you’re interested in getting involved, we’d love to hear feature requests on the issues page!
Open Sourcing LLMFoundry Integration
While MegaBlocks provides an implementation of MoE layers, it requires a larger framework around it to implement an entire Transformer, provide a parallelism strategy, and train performantly at scale. We’re excited to open source our integration of MegaBlocks into LLMFoundry, our open source training stack for large AI models. LLMFoundry provides an extensible and configurable implementation of a transformer integrated with PyTorch FSDP, enabling large-scale MoE training. This integration served as a core component to training DBRX, enabling scaling to 130B+ parameter models.
Existing YAMLs can easily be tweaked to include MoE layers:
Optimized Training at Databricks
Along with MegaBlocks, we’ve built a wide variety of methods dedicated to optimizing performance on thousands of GPUs. Our premium offering includes custom kernels, 8-bit support, and linear scaling to achieve far superior performance, especially for large models at scale. We’re incredibly excited to start onboarding customers onto our next generation MoE platform. Contact us today to get started!