Care Cost Compass: An Agent System Using Agent Bricks Custom Agents
In this article, we will discuss in detail how to develop a production-ready Agent System (performing a complex task through coordination of multiple different AI and GenAI models) application on Databricks Data Intelligence Platform using platform capabilities like Vector Search, Model Serving, AI Gateway, Online Tables, and Unity Catalog. We will also demonstrate the usage of the Evaluation-Driven Development methodology to rapidly build agentic applications and iteratively improve model quality.
Opportunities and Obstacles in Developing Reliable Generative AI for Enterprises
Generative AI offers transformative benefits in enterprise application development by providing advanced natural language capabilities in the hands of Software Engineers. It can automate complex tasks such as content generation, data analysis, and code suggestions, significantly reducing development time and operational costs. By leveraging advanced models, enterprises can create more personalized user experiences, improve decision-making through intelligent data insights, and streamline processes like customer support with AI-driven chatbots.
Despite its many advantages, using generative AI in enterprise application development presents significant challenges.
Accuracy: One major issue is the accuracy and reliability of AI outputs, as generative models can sometimes produce inaccurate or biased results.
Safety: Ensuring the safety and ethical use of AI is also a concern, especially when dealing with sensitive data or applications in regulated industries. Regulatory compliance and addressing security vulnerabilities remain critical concerns when deploying AI at scale.
Cost: Additionally, scaling AI systems to be enterprise-ready requires robust infrastructure and expertise, which can be resource-intensive. Integrating generative AI into existing systems may also pose compatibility challenges while maintaining transparency and accountability in AI-driven processes is crucial but difficult to achieve.
Agent Bricks Custom Agents and Databricks Data Intelligence Platform
Agent Bricks Custom Agents offers a comprehensive suite of tools for building, deploying, evaluating, and managing cutting-edge generative AI applications. Powered by the Databricks Data Intelligence Platform, Mosaic AI allows organizations to securely and cost-efficiently develop production-ready, complex AI systems that are seamlessly integrated with their enterprise data.

Healthcare Agent for Out-of-Pocket Cost Calculation
Payers in the healthcare industry are organizations — such as health plan providers, Medicare, and Medicaid — that set service rates, collect payments, process claims, and pay provider claims. When an individual needs a service or care, most call the customer service representative of their payer on the phone and explain their situation to get an estimate of the cost of their treatment, service, or procedure.
This calculation is pretty standard and can be done deterministically once we have enough information from the user. Creating an agentic application that is capable of identifying the relevant information from user input and then retrieving the right cost accurately can free up customer service agents to attend more important phone calls.
In this article, we will build an Agent GenAI System using Mosaic AI capabilities like Vector Search, Model Serving, AI Gateway, Online Tables, and Unity Catalog. We will also demonstrate the use of the Evaluation-Driven Development methodology to rapidly build agentic applications and iteratively improve model quality.
Application Overview
The scenario we are discussing here is when a customer logs on to a Payer portal and uses the chatbot feature to inquire about the cost of a medical procedure. The agentic application that we create here is deployed as a REST api using Databricks Model Serving.
Once the agent receives a question, a typical workflow for procedure cost estimation is as below:
- Understand the client_id of the customer who is asking the question.
- Retrieve the appropriate negotiated benefit related to the question.
- Retrieve the procedure code related to the question.
- Retrieve current member deductibles for the current plan year.
- Retrieve the negotiated procedure cost for the procedure code.
- With the benefit details, procedure cost, and current deductibles, calculate the in-network and out-of-network cost for the procedure for the member.
- Summarize the cost calculation in a professional way and send it to the user.
In reality, the data points for this application will be outcomes of multiple complex data engineering workflows and calculations, but we will make a few simplifying assumptions to keep the scope of this work limited to the design, development, and deployment of the agentic application.
- Chunking logic for the Summary of Benefits document assumes the structure is nearly the same for most documents. We also assume that the final Summary of Benefits for each product for all the clients is available in a Unity Catalog Volume.
- The schema of most tables is simplified to just a few required fields.
- It is assumed that the negotiated Price for each procedure is available in a Delta Table in Unity Catalog.
- The calculation for determining the out-of-pocket cost is simplified just to show the techniques used to capture notes.
- It is also assumed that the client application includes the member ID in the request and that the client ID can be looked up from a Delta Table.
The notebooks for this Solution Accelerator are available here.
Architecture
We will use the Agent Bricks Custom Agents on Databricks Data Intelligence Platform to build this solution. A high level architecture diagram is given below.
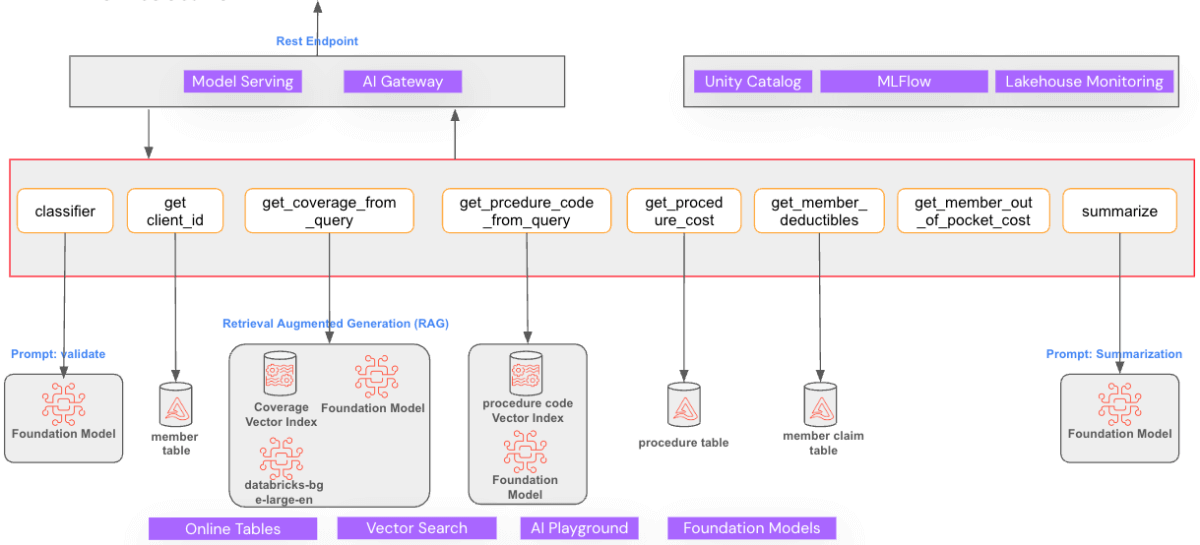
We will be building the solution in multiple steps, starting with data preparation.
Data Preparation
In the next few sections we will talk about preparing the data for our Agent application.
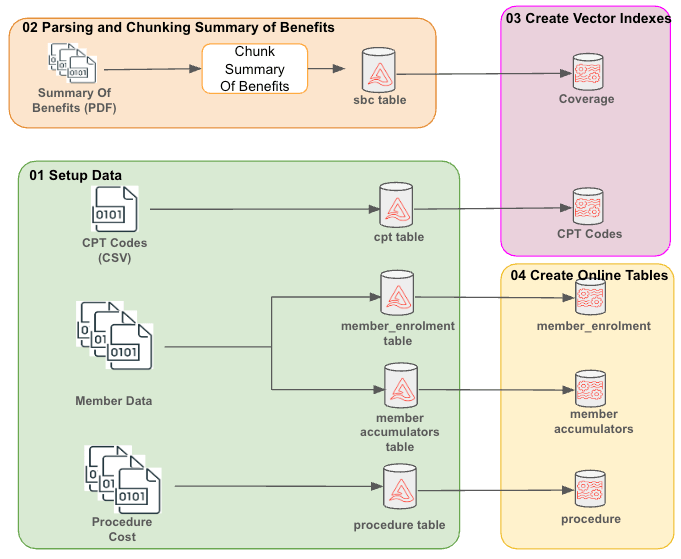
The below Delta Tables will contain the synthetic data that's needed for this Agent.
member_enrolment: Table containing member enrolment information like client and plan_id
member_accumulators: Table containing member accumulators like deductibles and out-of-pocket spent
cpt_codes: Table containing CPT codes and descriptions
procedure_cost: Table containing the negotiated cost of each procedure
sbc_details: Table containing chunks derived from the Summary of Benefits pdf
You can refer to this notebook for implementation details.
Parsing and Chunking Summary of Benefits Documents
In order to retrieve the appropriate contract related to the question, we need to first parse the Summary of Benefits document for each client into a delta table. This parsed data will then be used to create a Vector Index so that we can run semantic searches on this data using the customer's question.
We are assuming that the Summary of Benefits document has the below structure.
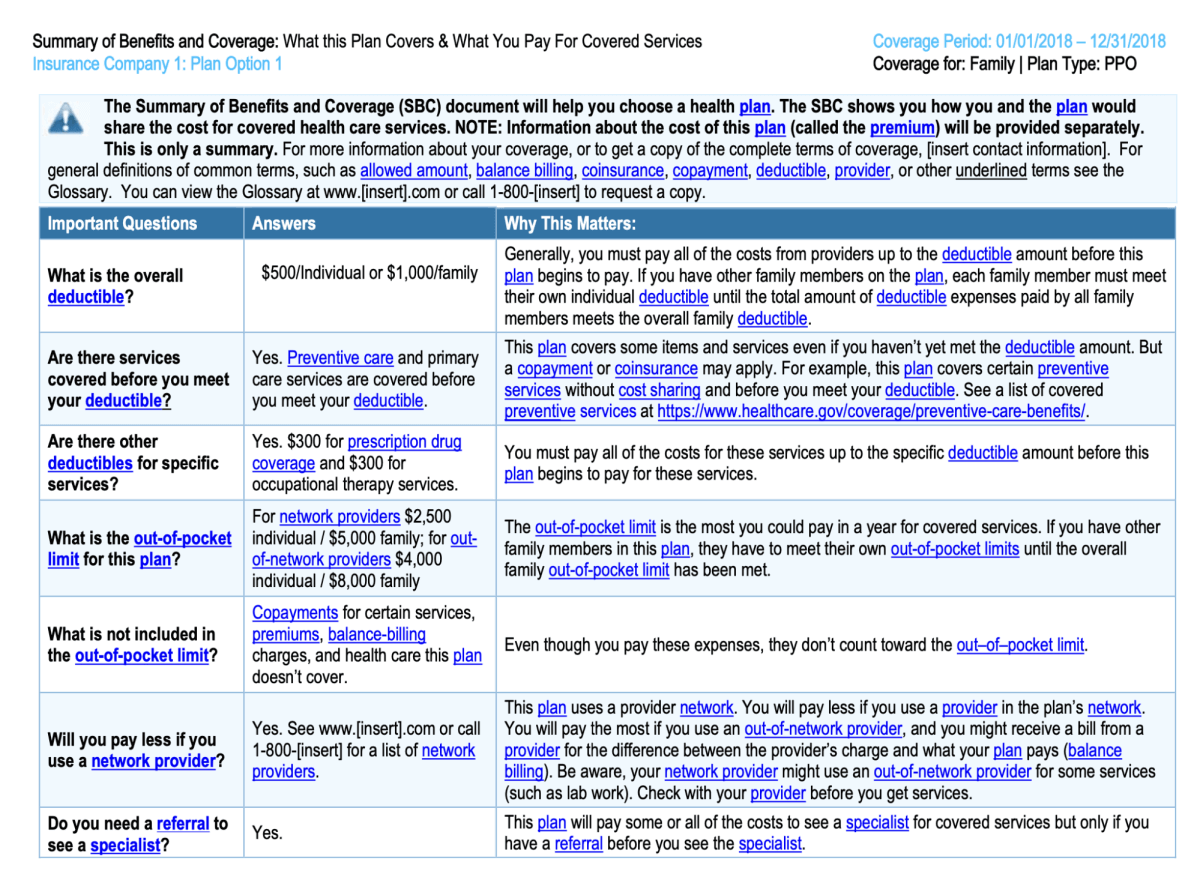
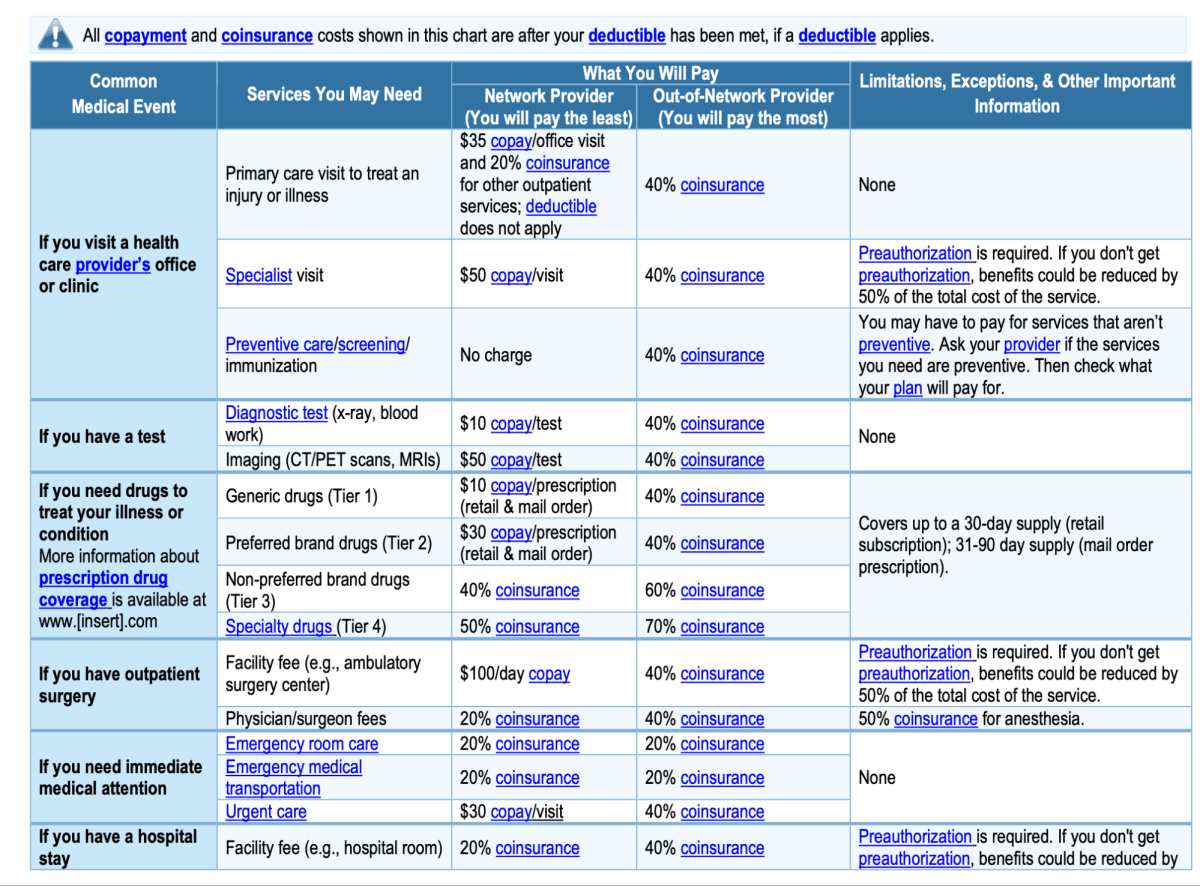
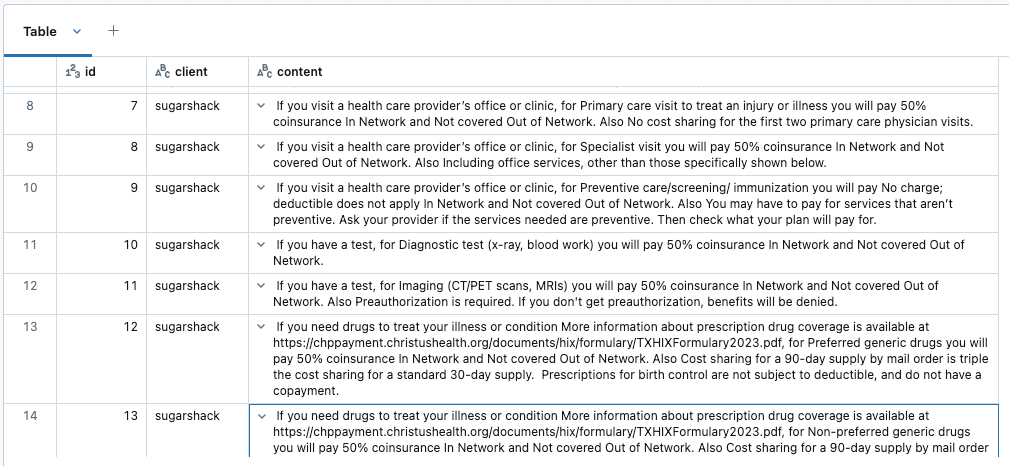
Our aim is to extract this tabular data from PDF and create a full-text summary of each line item so that it captures the details appropriately. Below is an example
For the line item below, we want to generate two paragraphs as below

If you have a test, for Diagnostic test (x-ray, blood work) you will pay $10 copay/test In Network and 40% coinsurance Out of Network.
and
If you have a test, for Imaging (CT/PET scans, MRIs) you will pay $50 copay/test In Network and 40% coinsurance Out of Network.
NOTE: If the Summary of Benefits document has different formats, we have to create more pipelines and parsing logic for each format. This notebook details the chunking process.
The result of this process is a Delta Table that contains each line item of the Summary of Benefits document as a separate row. The client_id has been captured as metadata of the benefit paragraph. If needed we can capture more metadata, like product_id, but for the scope of this work, we will keep it simple.
Refer to the code in this notebook for implementation details.
Creating Vector Indexes
Databricks AI Search is a vector database built into the Databricks Data Intelligence Platform and integrated with its governance and productivity tools. A vector database is optimized to store and retrieve embeddings, which are mathematical representations of the semantic content of data, typically text or image data.
For this application, we will be creating two vector indexes.
- Vector Index for the parsed Summary of Benefits and Coverage chunks
- Vector Index for CPT codes and descriptions
Creating Vector Indexes in Mosaic AI is a two-step process.
- Create a Vector Search Endpoint: The Vector Search Endpoint serves the Vector Search index. You can query and update the endpoint using the REST API or the SDK. Endpoints scale automatically to support the size of the index or the number of concurrent requests.
- Create Vector Indexes: The Vector Search index is created from a Delta table and is optimized to provide real-time approximate nearest neighbor searches. The goal of the search is to identify documents that are similar to the query. Vector Search indexes appear in and are governed by the Unity Catalog.
This notebook details the process and contains the reference code.
Online Tables
An online table is a read-only copy of a Delta Table that is stored in a row-oriented format optimized for online access. Online tables are fully serverless tables that auto-scale throughput capacity with the request load and provide low latency and high throughput access to data of any scale. Online tables are designed to work with Databricks Model Serving, Feature Serving, and agentic applications which are used for fast data lookups.
We will need online tables for our member_enrolment, member_accumulators, and procedure_cost tables.
This notebook details the process and contains the necessary code.
Building Agent Application
Now that we have all the necessary data, we can start building our Agent Application. We will follow the Evaluation Driven Development methodology to rapidly develop a prototype and iteratively improve its quality.
Evaluation Driven Development
The Evaluation Driven Workflow is based on the Databricks AI Research team’s recommended best practices for building and evaluating high-quality RAG applications.
Databricks recommends the following evaluation-driven workflow:
- Define the requirements
- Collect stakeholder feedback on a rapid proof of concept (POC)
- Evaluate the POC’s quality
- Iteratively diagnose and fix quality issues
- Deploy to production
- Monitor in production
Read more about Evaluation Driven Development in the Databricks AI Cookbook.
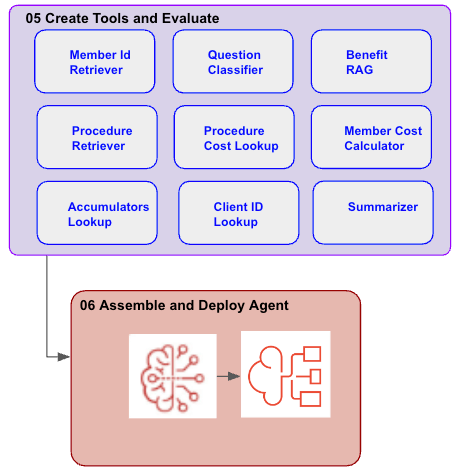
Building Tools and Evaluating
While constructing Agents, we might be leveraging many functions to perform specific actions. In our application, we have the below functions that we need to implement
- Retrieve member_id from context
- Classifier to categorize the question
- A lookup function to get client_id from member_id from the member enrolment table
- A RAG module to look up Benefits from the Summary of Benefits index for the client_id
- A semantic search module to look up appropriate procedure code for the question
- A lookup function to get procedure cost for the retrieved procedure_code from the procedure cost table
- A lookup function to get member accumulators for the member_id from the member accumulators table
- A Python function to calculate out-of-pocket cost given the information from the previous steps
- A summarizer to summarize the calculation in a professional manner and send it to the user
While developing Agentic Applications, it's a general practice to develop reusable functions as Tools so that the Agent can use them to process the user request. These Tools can be used with either autonomous or strict agent execution.
In this notebook, we will develop these functions as LangChain tools so that we can potentially use them in a LangChain agent or as a strict custom PyFunc model.
NOTE: In a real-life scenario, many of these tools could be complex functions or REST API calls to other services. The scope of this notebook is to illustrate the feature and can be extended in any way possible.
One of the aspects of evaluation-driven development methodology is to:
- Define quality metrics for each component in the application
- Evaluate each component individually against the metrics with different parameters
- Pick the parameters that gave the best result for each component
This is very similar to the hyperparameter tuning exercise in classical ML development.
We will do just that with our tools, too. We will evaluate each tool individually and pick the parameters that give the best results for each tool. This notebook explains the evaluation process and provides the code. Again, the evaluation provided in the notebook is just a guideline and can be expanded to include any number of necessary parameters.
Assembling the Agent
Now that we have all the tools defined, it's time to combine everything into an Agent System.
Since we made our components as LangChain Tools, we can use an AgentExecutor to run the process.
But since it's a very straightforward process, to reduce response latency and improve accuracy, we can use a custom PyFunc model to build our Agent application and deploy it on Databricks Model Serving.
MLflow Python Function
MLflow’s Python function, pyfunc, provides flexibility to deploy any piece of Python code or any Python model. The following are example scenarios where you might want to use this.
- Your model requires preprocessing before inputs can be passed to the model’s
predictfunction. - Your model framework is not natively supported by MLflow.
- Your application requires the model’s raw outputs to be post-processed for consumption.
- The model itself has per-request branching logic.
- You are looking to deploy fully custom code as a model.
You can read more about deploying Python code with Model Serving here
CareCostCompassAgent
CareCostCompassAgent is our Python Function that will implement the logic necessary for our Agent. Refer to this notebook for complete implementation.
There are two required functions that we need to implement:
load_context- anything that needs to be loaded just one time for the model to operate should be defined in this function. This is critical so that the system minimizes the number of artifacts loaded during the predict function, which speeds up inference. We will be instantiating all the tools in this methodpredict- this function houses all the logic that runs every time an input request is made. We will implement the application logic here.
Model Input and Output
Our model is being built as a Chat Agent and that dictates the model signature that we are going to use. So, the request will be ChatCompletionRequest
The data input to a pyfunc model can be a Pandas DataFrame, Pandas Series, Numpy Array, List, or a Dictionary. For our implementation, we will be expecting a Pandas DataFrame as input. Since it's a Chat agent, it will have the schema of mlflow.models.rag_signatures.Message.
Our response will be just a mlflow.models.rag_signatures.StringResponse
Workflow
We will implement the below workflow in the predict method of pyfunc model. The below three flows can be run parallelly to improve the latency of our responses.
- get client_id using member id and then retrieve the appropriate benefit clause
- get the member accumulators using the member_id
- get the procedure code and lookup the procedure code
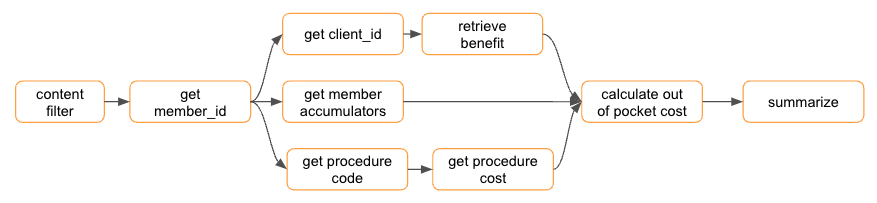
We will use the asyncio library for the parallel IO operations. The code is available in this notebook.
Agent Evaluation
Now that our agent application has been developed as an MLflow-compatible Python class, we can test and evaluate the model as a black box system. Even though we have evaluated the tools individually, it's important to evaluate the agent as a whole to make sure it's producing the desired output. The approach to evaluating the model is pretty much the same as we did for individual tools.
- Define an evaluation data frame
- Define the quality metrics we are going to use to measure the model quality
- Use the MLflow evaluation using databricks-agents to perform the evaluation
- Study the evaluation metrics to assess the model quality
- Examine the traces and evaluation results to identify improvement opportunities
This notebook shows the steps we just covered.
Now, we have some preliminary metrics of model performance that can become the benchmark for future iterations. We will stick to the Evaluation Driven Development workflow and deploy this model so that we can open it to a select set of business stakeholders and collect curated feedback so that we can use that information in our next iteration.
Register Model and Deploy
On the Databricks Data Intelligence platform, you can manage the full lifecycle of models in Unity Catalog. Databricks provides a hosted version of MLflow Model Registry in the Unity Catalog. Learn more here.
A quick recap of what we have done so far:
- Built tools that will be used by our Agent application
- Evaluated the tools and picked the parameters that work best for individual tools
- Created a custom Python function model that implemented the logic
- Evaluated the Agent application to obtain a preliminary benchmark
- Tracked all the above runs in MLflow Experiments
Now it’s time we register the model into Unity Catalog and create the first version of the model.
Unity Catalog provides a unified governance solution for all data and AI assets on Databricks. Learn more about Unit Catalog here. Models in Unity Catalog extend the benefits of Unity Catalog to ML models, including centralized access control, auditing, lineage, and model discovery across workspaces. Models in Unity Catalog are compatible with the open-source MLflow Python client.
When we log a model into Unity Catalog, we need to make sure to include all the necessary information to package the model and run it in a stand-alone environment. We will provide all the below details:
- model_config: Model Configuration—This will contain all the parameters, endpoint names, and vector search index information required by the tools and the model. By using a model configuration to specify the parameters, we also ensure that the parameters are automatically captured in MLflow every time we log the model and create a new version.
- python_model: Model Source Code Path - We will log our model using MLFlow's Models from Code feature instead of the legacy serialization technique. In the legacy approach, serialization is done on the model object using either cloudpickle (custom pyfunc and LangChain) or a custom serializer that has incomplete coverage (in the case of LlamaIndex) of all functionality within the underlying package. In models from code, for the model types that are supported, a simple script is saved with the definition of either the custom pyfunc or the flavor’s interface (i.e., in the case of LangChain, we can define and mark an LCEL chain directly as a model within a script). This is much cleaner and removes all the serialization errors that once would encounter for dependent libraries.
- artifacts: Any dependent artifacts - We don't have any in our model
- pip_requirements: Dependent libraries from PyPi - We can also specify all our pip dependencies here. This will make sure these dependencies can be read during deployment and added to the container built for deploying the model.
- input_example: A sample request - We can also provide a sample input as guidance to the users using this model
- signature: Model Signature
- registered_model_name: A unique name for the model in the three-level namespace of Unity Catalog
- resources: List of other endpoints being accessed from this model. This information will be used at deployment time to create authentication tokens for accessing those endpoints.
We will now use the mlflow.pyfunc.log_model method to log and register the model to Unity Catalog. Refer to this notebook to see the code.
Once the model is logged to MLflow, we can deploy it to Databricks Model Serving. Since the Agent implementation is a simple Python Function that calls other endpoints for executing LLM calls, we can deploy this application on a CPU endpoint. We will use the Agent Bricks Custom Agents to
- deploy the model by creating a CPU model serving endpoint
- setup inference tables to track model inputs and responses and traces generated by the agent
- create and set authentication credentials for all resources used by the agent
- creates a feedback model and deploys a Review Application on the same serving endpoint
Read more about deploying agent applications using Databricks agents api here
Once the deployment is complete, you will see two URLs available: one for the model inference and the second for the review app, which you can now share with your business stakeholders.

Collecting Human Feedback
The evaluation dataframe we used for the first evaluation of the model was put together by the development team as a best effort to measure the preliminary model quality and establish a benchmark. To ensure the model performs as per the business requirements, it will be a great idea to get feedback from business stakeholders prior to the next iteration of the inner dev loop. We can use the Review App to do that.
The feedback collected via Review App is saved in a delta table along with the Inference Table. You can read more here.
Inner Loop with Improved Evaluation Data
Now, we have critical information about the agent's performance that we can use to iterate quickly and improve the model quality rapidly.
- Quality feedback from business stakeholders with appropriate questions, expected answers, and detailed feedback on how the agent performed.
- Insights into the internal working of the model from the MLflow Traces captured.
- Insights from previous evaluation performed on the agent with feedback from Databricks LLM judges and metrics on generation and retrieval quality.
We can also create a new evaluation dataframe from the Review App outputs for our next iteration. You can see an example implementation in this notebook.
We saw that Agent Systems tackle AI tasks by combining multiple interacting components. These components can include multiple calls to models, retrievers or external tools. Building AI applications as Agent Systems have several benefits:
- Build with reusability: A reusable component can be developed as a Tool that can be managed in Unity Catalog and can be used in multiple agentic applications. Tools can then be easily supplied into autonomous reasoning systems which make decisions on what tools to use when and uses them accordingly.
- Dynamic and flexible systems: As the functionality of the agent is broken into multiple sub systems, it's easy to develop, test, deploy, maintain and optimize these components easily.
- Better control: It's easy to control the quality of response and security parameters for each component individually instead of having a large system with all access.
- More cost/quality options: Combinations of smaller tuned models/components provide better results at a lower cost than larger models built for broad application.
Agent Systems are still an evolving category of GenAI applications and introduce several challenges to develop and productionize such applications, such as:
- Optimizing multiple components with several hyperparameters
- Defining appropriate metrics and objectively measuring and tracking them
- Rapidly iterate to improve the quality and performance of the system
- Cost Effective deployment with ability to scale as needed
- Governance and lineage of data and other assets
- Guardrails for model behavior
- Monitoring cost, quality and safety of model responses
Agent Bricks Custom Agents provides a suite of tools designed to help developers build and deploy high-quality Agent applications that are consistently measured and evaluated to be accurate, safe, and governed. Agent Bricks Custom Agents makes it easy for developers to evaluate the quality of their RAG application, iterate quickly with the ability to test their hypothesis, redeploy their application easily, and have the appropriate governance and guardrails to ensure quality continuously.
Agent Bricks Custom Agents is seamlessly integrated with the rest of the Databricks Data Intelligence Platform. This means you have everything you need to deploy end-to-end agentic GenAI systems, from security and governance to data integration, vector databases, quality evaluation and one-click optimized deployment. With governance and guardrails in place, you prevent toxic responses and ensure your application follows your organization’s policies.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.