Curating High-Quality Customer Identities with Databricks and Amperity
by Jenny Zhu, Caleb Benningfield and Bryan Smith
- Identity Resolution (IDR) is essential for customer insights – It helps unify fragmented customer interactions (online, in-store, email, ads) into a single identity, enabling accurate predictions for churn, personalization, and fraud detection.
- Databricks + Amperity integration simplifies IDR – Using Delta Sharing, AI automation, and 45+ matching algorithms, the Amperity Identity Resolution engine merges customer records into a unified identity graph, accessible in Databricks.
- Business impact of IDR – Unified customer data improves personalized marketing, product assortment, store placement, fraud detection, and even HR insights, leading to better decision-making and customer engagement.
When we think of use cases like product recommendations, churn predictions, advertising attribution and fraud detection, a common denominator is they all require us to consistently identify our customers across various interactions. Failing to recognize that the same person is browsing online, purchasing in-store, opening a marketing email and clicking on an advertisement, leaves us with an incomplete view of the customer, limiting our ability to recognize their needs, preferences and predict their future behavior.
Despite its importance, accurately identifying the customer across these interactions is incredibly difficult. People often interact with us without providing explicit identifying details, and when they do, those details aren’t always consistent. For example, if a customer makes a purchase using a credit card under the name Jennifer, signs up for the loyalty program as Jenny with a personal email, and clicks an online ad linked to her work email, these interactions might appear as three separate customers even though they all belong to the same person (Figure 1).
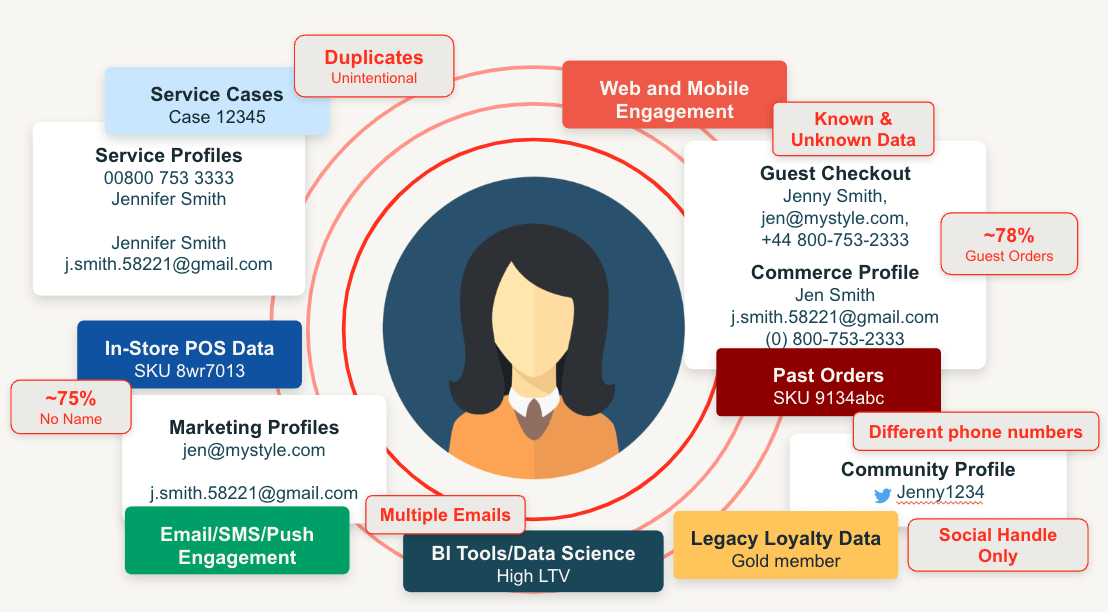
While solving this for a single customer is challenging, the real complexity lies in addressing it for hundreds of thousands, or even millions, of unique customers that retailers continuously engage with. Additionally, customer details are not static – as new behaviors, identifiers and household relationships emerge, our understanding of who the customer is must continue to evolve as well.
Identity resolution (IDR) is the term we use to describe the techniques used to stitch together all these details to arrive at a unified view of each customer. Effective IDR is critical as it enables and affects all our processes centered around customers, like personalized marketing for example.
Understanding the Identity Resolution Process
In many scenarios, customer identity is established through data we refer to as personally identifiable information (PII). First names, last names, mailing addresses, email addresses, phone numbers, account numbers, etc. are all common bits of PII collected through our customer interactions.
Using overlapping bits of PII, we might try to match and merge a few different records for an individual, however there are different degrees of uncertainty allowed depending on the type of PII. For example we might use normalization techniques for incorrectly typed email addresses or phone numbers, and fuzzy-matching techniques for name variations (e.g. Jennifer vs Jenny vs Jen) (Figure 2).

However, there are often situations where we don’t have overlapping PII. For example, a customer may have provided her name and mailing address with one record, her name and email address with another, and a phone number and that same email address in a third record. Through association, we might deduce that these are all the same person, depending on our tolerance for uncertainty (Figure 3).
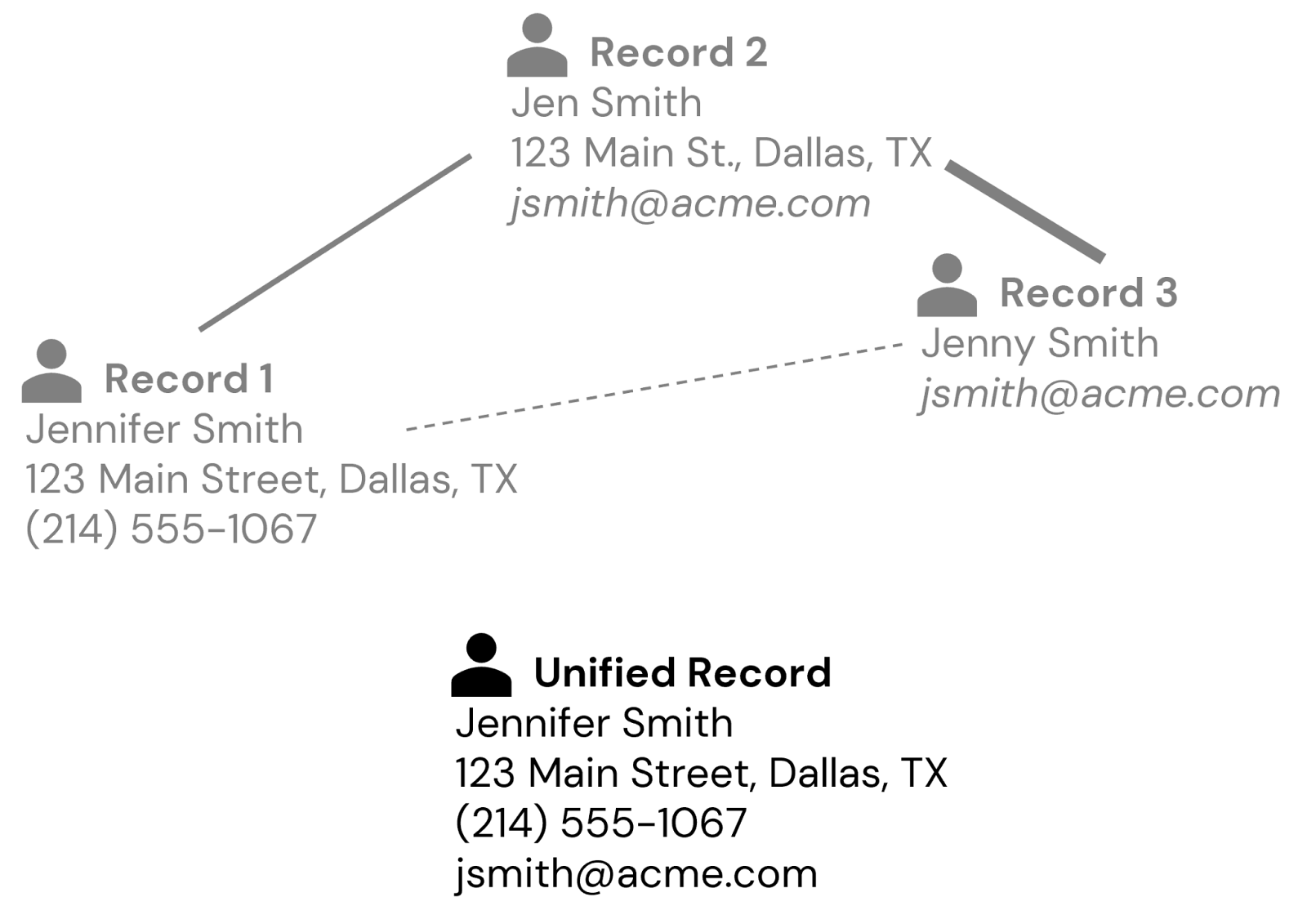
The core of the IDR process lies in linking records by combining exact match rules and fuzzy matching techniques, tailored to different data elements, to establish a unified customer identity. The result is a probabilistic understanding of who your customers are that evolves as new details are collected and woven into the identity graph.
Building the Identity Graph
The challenge of building and maintaining a customer identity graph is made easier through Databricks’ integration with the Amperity Identity Resolution engine. Widely recognized as the world’s premier, first-party IDR solution, Amperity leverages 45+ algorithms to match and merge customer records. The out-of-the-box integration allows Databricks customers to seamlessly share their data with Amperity and gain detailed insights back on how a collection of customer records resolve to unified identities. (Figure 4).
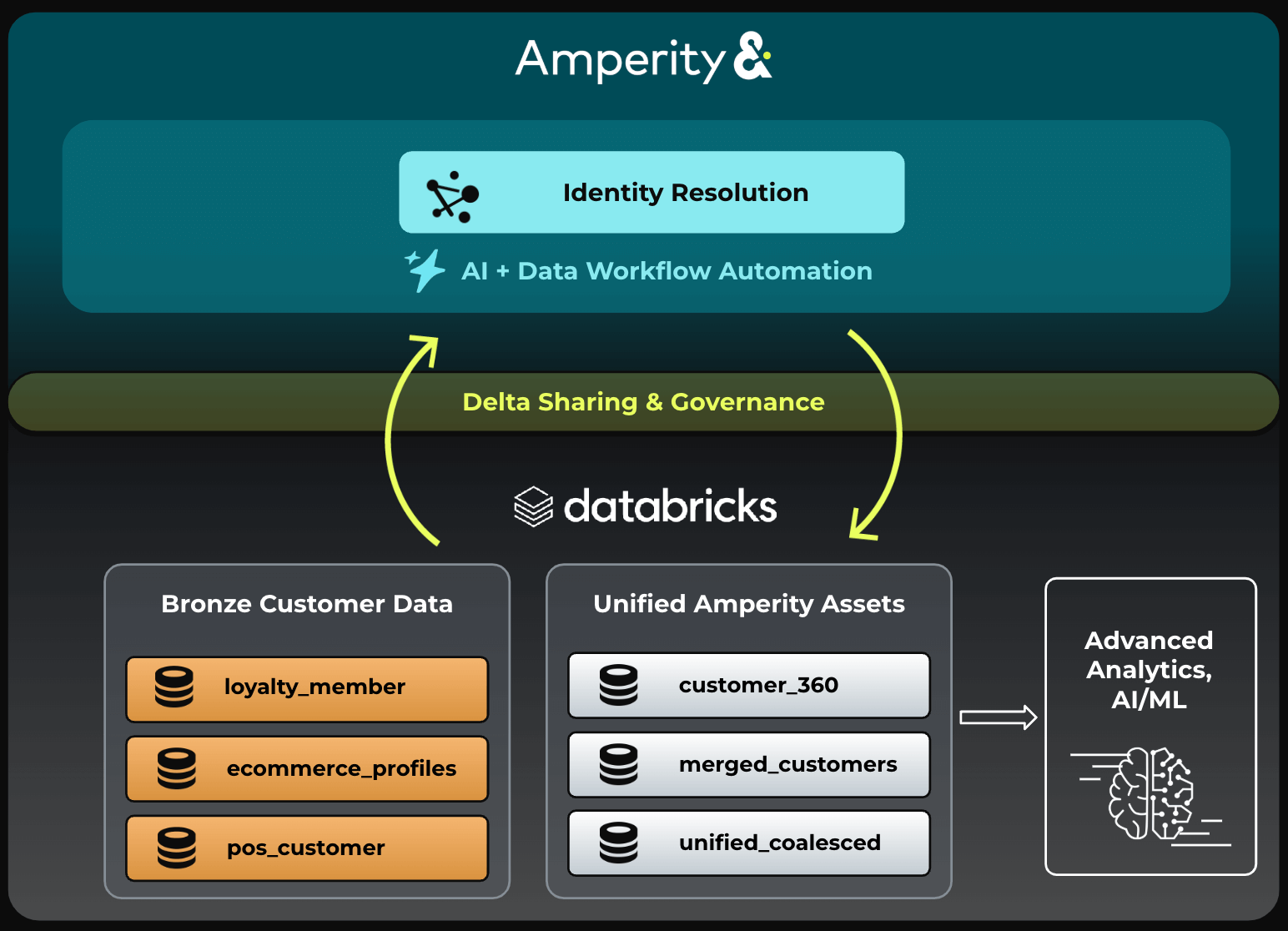
The process of setting up this integration and running IDR in Amperity is very straightforward:
- Setup a Delta Sharing connection with Databricks via the Amperity Bridge
- Use the AI automation to tag various PII elements in the shared data
- Run the Amperity Stitch algorithm to assemble the IDR graph
- Map the resulting output to a Databricks catalog
- Refresh the graph as needed
A detailed guide to these steps can be found in the Amperity Identity Resolution Quickstart Guide, and a video walkthrough of the process can be viewed here:
Employing the Identity Graph
The end result of the integration is a set of related tables that include unified customer elements and suggestions for preferred identity information for each customer (Figure 5).
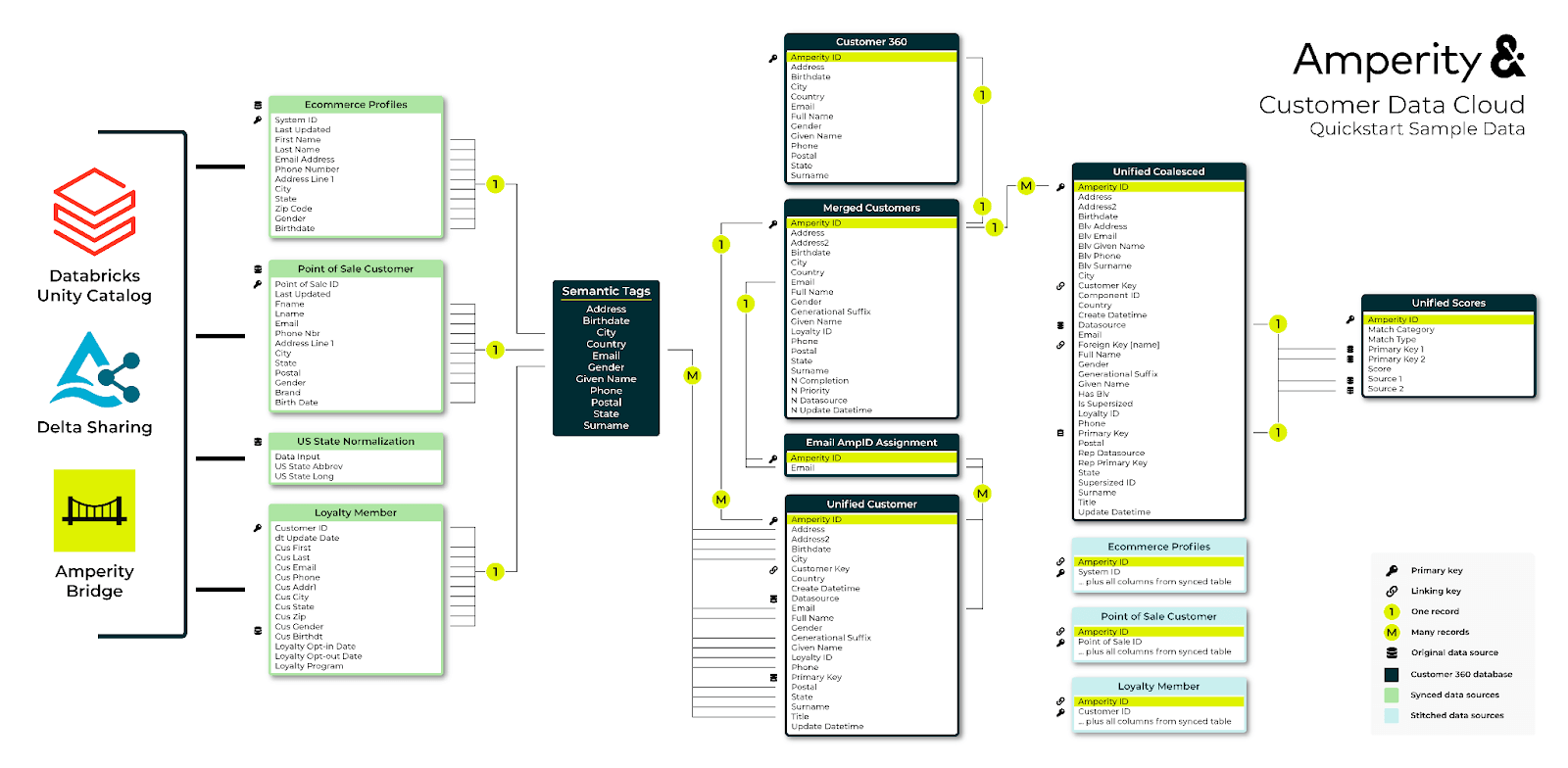
Data engineers, data scientists, application developers can leverage the resulting data in Databricks to build a wide range of solutions to tackle common enterprise needs and use cases:
- Customer Insights: Being able to link customer data records, both internal and external, organizations can develop deeper, more accurate insights into customer behaviors and preferences.
- Personalized Marketing & Experiences: Using those insights and being better able to identify customers as they engage various platforms, organizations can deliver more targeted messages and offers, creating a more personalized experience.
- Product Assortment: With a more accurate picture of who is buying what, organizations can better profile the demographics of their customers in specific locations and build product assortments more likely to resonate with the population being served.
- Store Placement: Those same demographic insights can help organizations assess the potential of new store locations, identifying areas where customers like those they have successfully engaged in other regions reside.
- Fraud Detection: By developing a clearer picture of how individuals identify themselves, organizations can better spot bad actors attempting to game promotional offers, skirt blocked party lists or use credentials that don’t belong to them.
- HR Scenarios & Employee Insights: And just like with customers, organizations can develop a more comprehensive view of existing or potential employees to better manage recruitment, hiring and retention practices.
Getting Started with Unifying Customer Identities
If your organization is wrestling with customer identity resolution, you can get started with the Amperity’s Identity Resolution by signing up for a free, 30-day trial. Before doing this, it’s recommended to ensure you have access to customer data assets and the ability to set up Delta Sharing in your Databricks environment. We also recommend you follow the steps in the quick start guide using the sample data Amperity provides to familiarize yourself with the overall process. Lastly, you can always reach out to your Databricks and Amperity representatives to get more details on the solution and how it could be leveraged for your specific needs.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.