Data Vault Best practice & Implementation on the Lakehouse

In the previous article Prescriptive Guidance for Implementing a Data Vault Model on the Databricks Lakehouse Platform, we explained core concepts of data vault and provided guidance of using it on Databricks. We have many customers in the field looking for examples and easy implementation of data vault on Lakehouse.
In this article, we aim to dive deeper on how to implement a Data Vault on Databricks' Lakehouse Platform and provide a live example to load an EDW Data Vault model in real-time using Delta Live Tables.
Here are the high-level topics we will cover in this blog:
- Why Data Vault
- Data Vault in Lakehouse
- Implementing a Data Vault Model in Databricks Lakehouse
- Conclusion
1. Why Data Vault
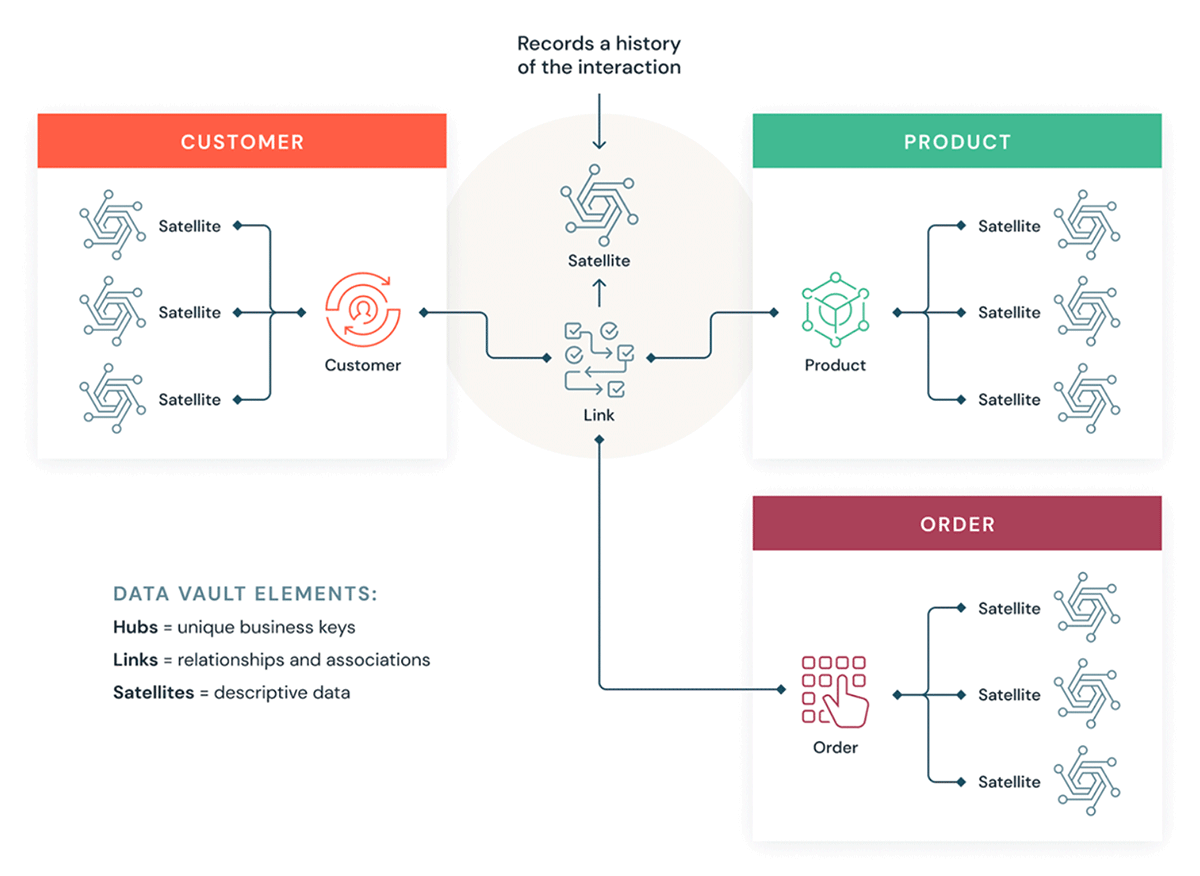
The main goal for Data Vault is to build a scalable modern data warehouse in today's world. At its core, it uses hubs, satellites and links to model the business world, which enables a stable (Hubs) yet flexible (Satellites) data model and architecture that are resilient to environmental changes. Hubs contain business keys that are unlikely to change unless core business changes and associations between the hubs make the skeleton of the Data Vault Model, while satellites contain contextual attributes of a hub that could be created and extended very easily.
Please refer to below for a high-level design of the Data Vault Model, with 3 key benefits by design:
- Enables efficient parallel loading for the enterprise data warehouse as there is less dependency between the tables of the model, as we could see below, hubs or satellites for the customer, product, order could all be loaded in parallel.
- Preserve a single version of the facts in the raw vault as it recommends insert only and keep the source metadata in the table.
- New Hubs or Satellites could be easily added to the model incrementally, enabling fast to market for data asset delivery.
2. Data Vault in Lakehouse
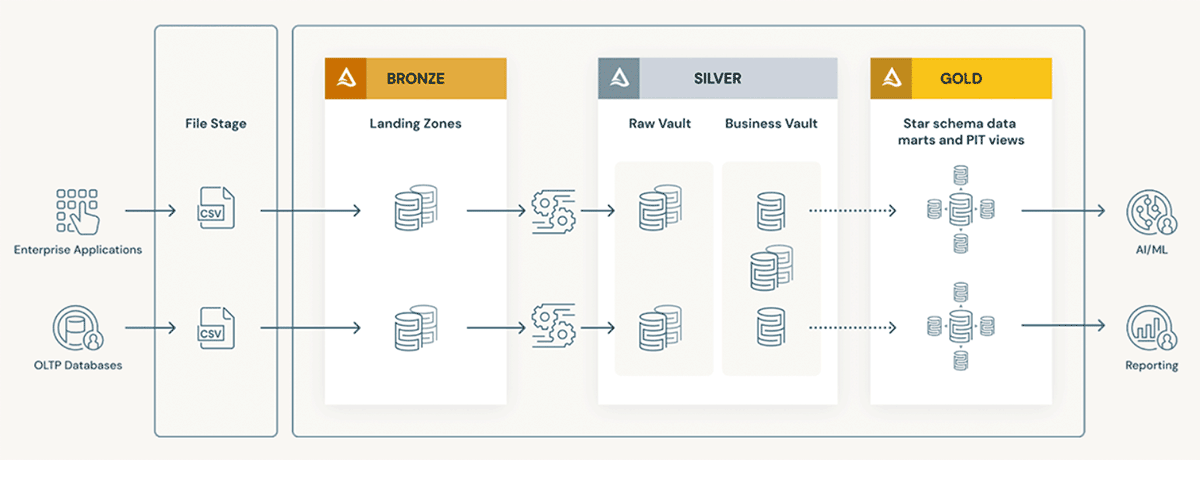
The Databricks Lakehouse Platform supports Data Vault Model very well, please refer to below for high level architecture of Data Vault Model on Lakehouse. The robust and scalable Delta Lake storage format enables customers to build a raw vault where unmodified data is stored, and a business vault where business rules and transformation are applied if required. Both will align to the design earlier hence get the benefits of a Data Vault Model.
Gartner®: Databricks Cloud Database Leader

3. Implementing a Data Vault Model in Databricks Lakehouse
Based on the design in the previous section, loading the hubs, satellites and links tables are straightforward. All ETL loads could happen in parallel as they don't depend on each other, for example, customer and product hub tables could be loaded as they both have their only business keys. And customer_product_link table, customer satellite and product satellite could be loaded in parallel as well since they have all the required attributes from the source.
Overall Data Flow
Please refer to the high level data flow demonstrated in Delta Live Table pipeline below. For our example we use the TPCH data that are commonly used for decision support benchmarks. The data are loaded into the bronze layer first and stored in Delta format, then they are used to populate the Raw Vault for each object (e.g. hub or satellites of customer and orders, etc.). Business Vault are built on the objects from Raw Vault, and Data mart objects (e.g. dim_customer, dim_orders, fact_customer_order ) for reporting and analytics consumptions.
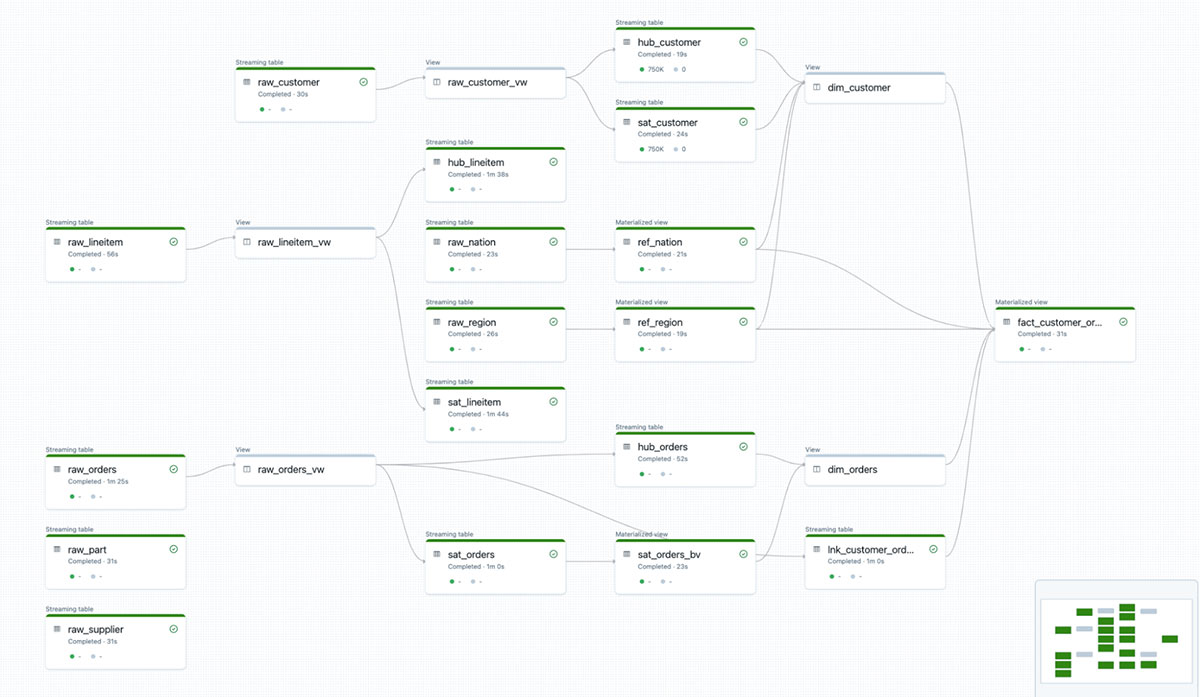
Raw Vault
Raw Vault is where we store Hubs, Satellites and Links tables which contain the raw data and maintain a single version of truth. As we could see from below, we create a view raw_customer_vw based on raw_customer and use hash function sha1(UPPER(TRIM(c_custkey))) to create hash columns for checking existence or comparison if required.
Once the raw customer view is created, we use it to create hub customer and satellite customers respectively with the code example below. In Delta Live Table, you could also easily set up data quality expectation (e.g. CONSTRAINT valid_sha1_hub_custkey EXPECT (sha1_hub_custkey IS NOT NULL) ON VIOLATION DROP ROW) and use that define how the pipeline will handle data quality issues defined by the expectation. Here we drop all the rows if it does not have a valid business key.
Hubs and Satellites of other objects are loaded in the similar way. For Link tables, here is an example to populate lnk_customer_orders based on the raw_orders_vw.
Business Vault
Once the hubs, satellites and links are populated in the Raw Vault, Business Vault objects could be built based on them. This is to apply additional business rules or transformation rules on the data objects and prepare for easier consumption at a later stage. Here is an example of building sat_orders_bv, with which order_priority_tier is added as enrichment information of the orders object in the Business Vault.
Data Mart
Finally, we see customers loading Data Vault Point-in-Time Views and Data marts for easy consumption in the last layer. Here the main focus is ease of use and good performance on read. For most simple tables, it will suffice with creating views on top of the Hubs or Satellites or you can even load a proper star-schema like Dimensional Model in the final layer. Here is an example that creates a customer dimension as a view dim_customer, and the view could be used by others to simplify their queries.
One of the common issues with data vault is that sometimes it ends up with too many joins especially when you have a complex query or fact that requires attributes from many tables. The recommendation from Databricks is to pre-join the tables and stored calculated metrics if required so they don't have to be rebuilt many times on the fly. Here is an example of creating a fact table fact_customer_order based on multiple joins and storing it as a table for repeatable queries from the business users.
Delta Live Table Pipeline Setup
All the code of above could be found here. Customers could easily orchestrate the whole data flow based on the Delta Live Table pipeline setup, the configuration below is how I set up the pipeline in my environment, click DLT Configuration for more details on how to set up a Delta Live Table Pipeline your workflow if required.
4. Conclusion
In this blog, we learned about core Data Vault modeling concepts, and how to implement them using Delta Live Tables. The Databricks Lakehouse Platform supports various modeling methods in a reliable, efficient and scalable way, while Databricks SQL - our serverless data warehouse - allows you to run all your BI and SQL applications on the Lakehouse. To see all of the above examples in a complete workflow, please look at this example.
Please also check out our related blogs:
- Five Simple Steps for Implementing a Star Schema in Databricks With Delta Lake
- Data Modeling Best Practices & Implementation on a Modern Lakehouse
- What's a Dimensional Model and How to Implement It on the Databricks Lakehouse Platform