Databricks on GCP - A practitioners guide on data exfiltration protection.
Learn details of how you could set up a secure Databricks on GCP architecture to protect data exfiltration
Refreshed: Jul 7, 2025
The Databricks Lakehouse Platform provides a unified set of tools for building, deploying, sharing, and maintaining enterprise-grade data solutions at scale. Databricks integrates with cloud storage and security in your cloud account, and manages and deploys cloud infrastructure on your behalf.
The overarching goal of this article is to mitigate the following risks:
- Data access from a browser on the internet or an unauthorized network using the Databricks web application.
- Data access from a client on the internet or an unauthorized network using the Databricks API.
- Data access from a client on the internet or an unauthorized network using the Cloud Storage (GCS) API.
- A compromised workload on the Databricks cluster writing data to an unauthorized storage resource on GCP or on the internet.
Databricks supports several GCP native tools and services that help protect data in transit and at rest. One such service is VPC Service Controls, which provides a way to define security perimeters around Google Cloud resources. Databricks also supports network security controls, such as firewall rules based on network or secure tags. Firewall rules allow you to control inbound and outbound traffic to your GCE virtual machines.
Encryption is another important component of data protection. Databricks supports several encryption options, including customer managed encryption keys, key rotation, encryption at rest and in transit. Databricks-managed encryption keys are used by default and enabled out of the box, customers can also bring their own encryption keys managed by Google Cloud Key Management Service (KMS).
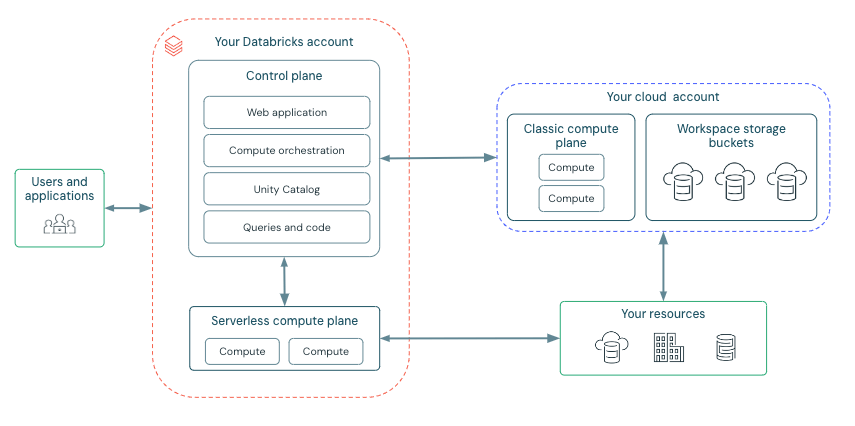
Before we begin, let’s have a quick look at the Databricks deployment architecture here:
Databricks is structured to enable secure cross-functional team collaboration while keeping a significant amount of backend services managed by Databricks so you can stay focused on your data science, data analytics, and data engineering tasks.
Databricks operates out of a control plane and a compute plane.
- The control plane includes the backend services that Databricks manages in its own Google Cloud account. Notebook commands and many other workspace configurations are stored in the control plane and encrypted at rest.
- The compute plane is where your data is processed. There are types of compute planes depending on the compute that you are using.
- For serverless compute, the serverless compute resources run in a serverless compute plane in your Databricks account.
- For classic Databricks compute, the compute resources are in your Google Cloud resources in what is called the classic compute plane. This refers to the network in your Google Cloud resources and its resources. To learn more about classic compute and serverless compute.
High-level Architecture
Network Communication Path
Let’s understand the communication path that we would like to secure. Databricks could be consumed by users and applications in numerous ways as shown below:
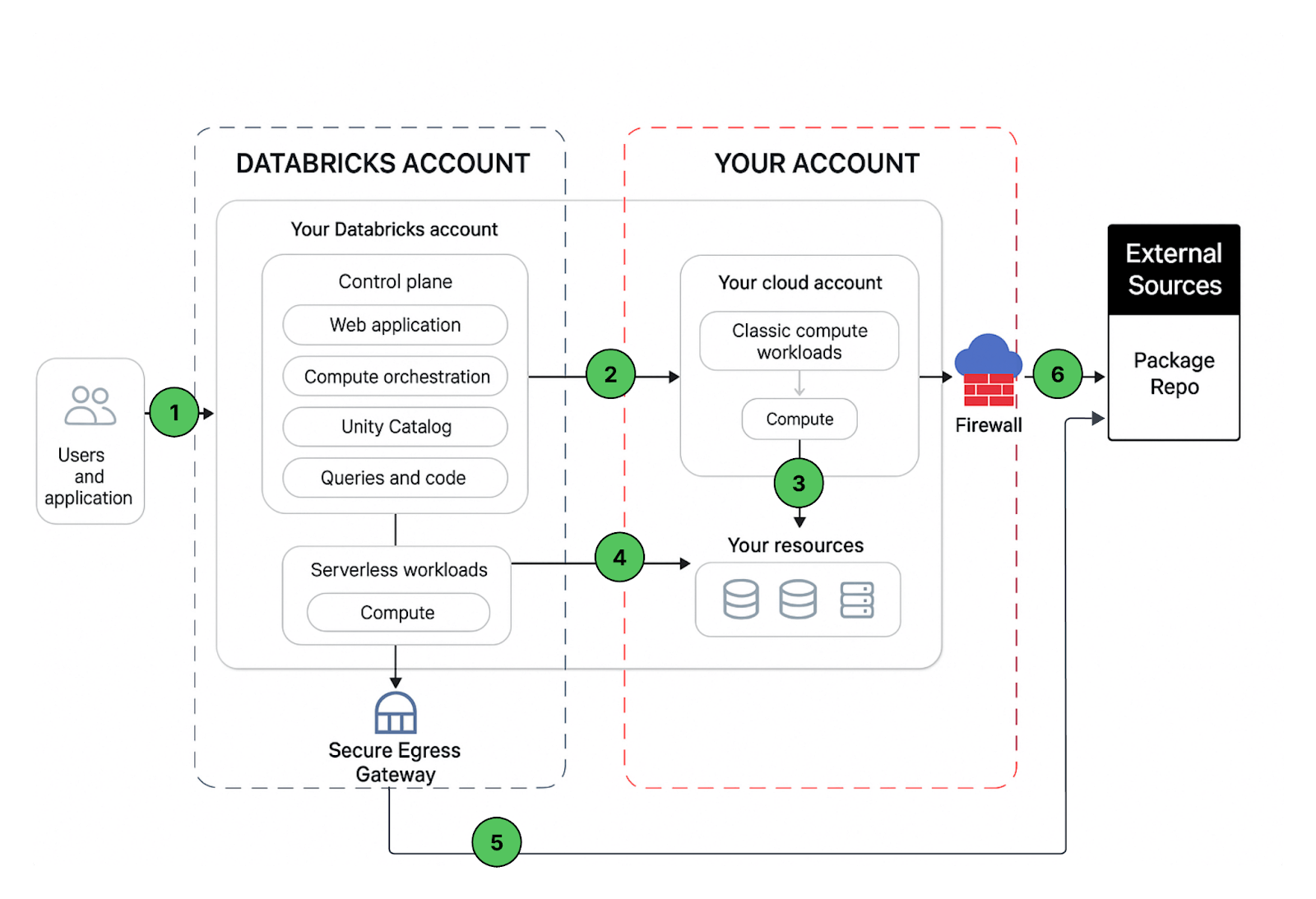
A Databricks workspace deployment includes the following network paths that you could secure
- User or Applications to Databricks web application aka workspace or Databricks REST APIs
- Databricks classic compute plane VPC network to the Databricks control plane service. This includes the secure cluster connectivity relay and the workspace connection for the REST API endpoints.
- Classic compute plane to your storage services (ex: GCS, BigQuery, PubSub)
- Serverless compute plane to to your storage services (ex: GCS, BigQuery, PubSub)
- Secure egress from serverless compute plane via network policies (egress firewall) to external data sources e.g. package repositories like pypi or maven
- Secure egress from classic compute plane via egress firewall to external data sources e.g. package repositories like pypi or maven
From end users perspective 1 requires ingress controls and 2,3,4,5,6 egress controls
In this article our focus area is to secure egress traffic from your databricks workloads, provide the reader with a prescriptive guidance on the proposed deployment architecture and while we are at it, we’ll share best practices to secure ingress (user/client into Databricks) traffic as well.
Proposed Deployment Architecture
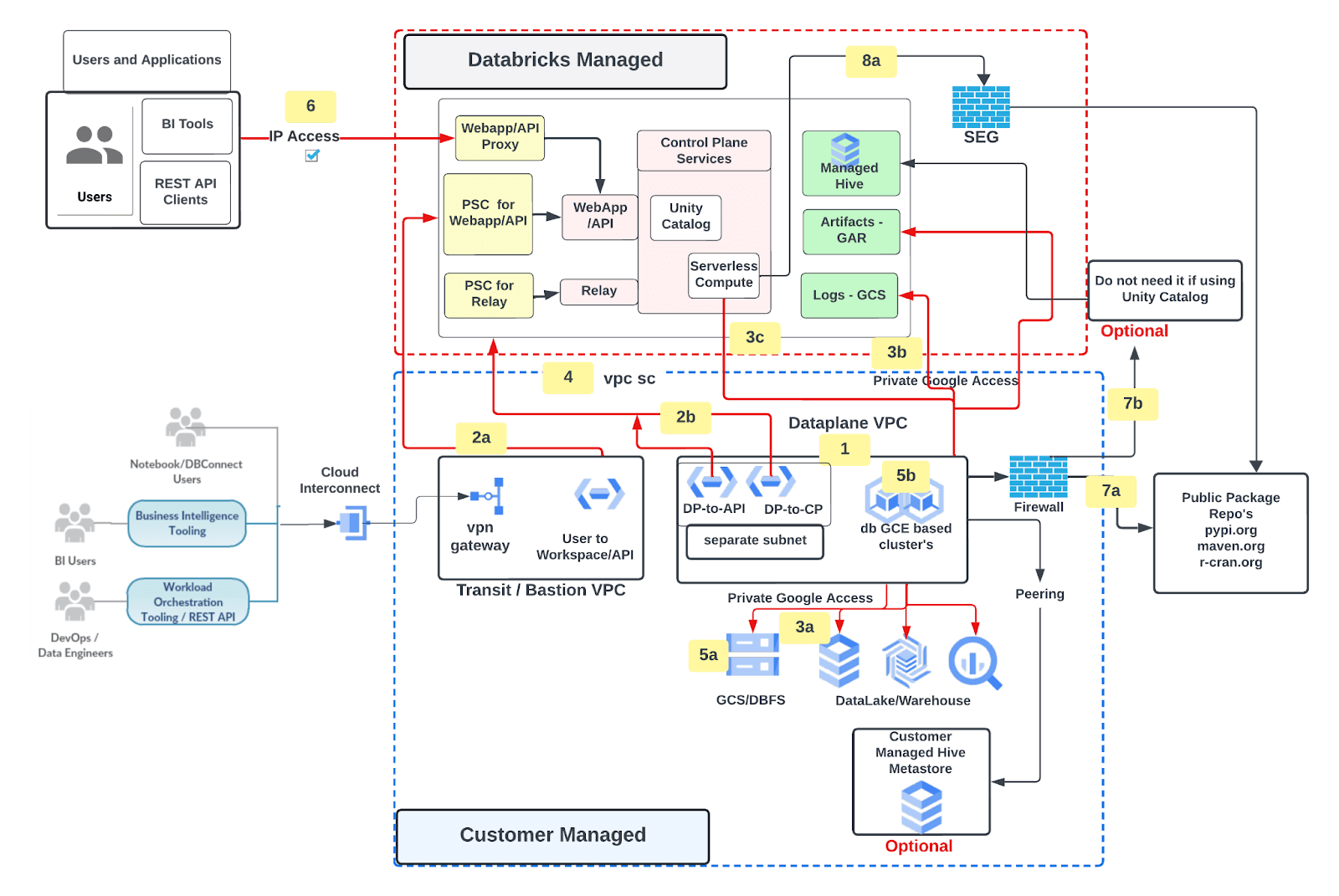
Create Databricks workspace with following features
- Customer managed GCP VPC for workspace deployment
- Private Service Connect (PSC) for Web application/APIs (frontend) and Control plane (backend) traffic
- User to Workspace UI / APIs
- Classic Compute plane(DP) to Control Plane(CP
- Traffic to Google Services over Private Google Access
- Classic compute plane to customer managed services (e.g. GCS, BQ)
- Databricks managed Google Cloud Storage (GCS) for logs (health telemetry and audit) and Artifact Repository (GAR) for Databricks runtime images
- Serverless compute plane to customer managed services (e.g. GCS, BQ)
- Databricks workspace GCP project (your GCP project) secured using VPC Service Controls (VPC SC)
- Customer Managed Encryption keys
- Databricks File System
- Databricks Cluster node boot and persistent disk
- Ingress control for Databricks workspace/APIs using IP Access list
- Traffic to external data sources filtered via VPC firewall [optional]
- Egress to public package repo
- Egress to Databricks managed hive
- Serverless compute plane egress traffic secured using secure egress network policies
Essential Reading
Before you begin, please make sure that you are familiar with these topics
- Key Databricks terminology
- What is Front and Backend Databricks Private Service Connect (PSC)?
- PSC enabled workspace requirements
- PSC deployment topology options available
- Ingress controller IP Access List
- Secure Cluster Connectivity
- Databricks Networking
- Unity Catalog
Prerequisites
- A Google Cloud account.
- A Google Cloud project in the account.
- A GCP VPC with 1 precreated primary subnet per workspace, see requirements here
- Use the Databricks Terraform provider 1.70.0 or higher. Always use the latest version of the provider.
- A Databricks on Google Cloud account in the project.
- A Google Account and a Google service account with the required permissions.
- In order to create a Databricks workspace the required roles are explained over here. As the GSA could provision additional resources beyond Databricks workspace ex private DNS zone, A records, PSC endpoints etc, it is better to have a project owner role to avoid any permission related issues.
- On your local development machine, you must have:
- The Terraform CLI: See Download Terraform on the Terraform website.
- Terraform Google Cloud Provider: There are several options available here to configure authentication for the Google Provider. Databricks doesn’t have any preference in how Google Provider authentication is configured.
Before you begin
- Both Shared VPC or standalone VPC are supported
- Google terraform provider supports OAUTH2 access token to authenticate GCP API calls and that's what we have used to configure authentication for the google terraform provider in this article.
- The access tokens are short lived (1 hour) and not auto refreshed
- Databricks terraform provider depends upon the Google terraform provider to provision GCP resources
- No changes, including resizing subnet IP address space or changing PSC endpoints configuration is allowed post workspace creation.
- If your Google Cloud organization policy has domain-restricted sharing enabled, please ensure that both the Google Cloud customer IDs for Databricks (C01p0oudw) and your own organization’s customer ID are in the policy’s allowed list. See the Google article Setting the organization policy. If you need help, contact your Databricks representative before provisioning workspace.
- Make sure that the service account used to create Databricks workspace has required roles and permissions.
- If you have VPC SC enabled on your GCP projects, then please update it as per ingress and egress rules listed here.
- Understand the IP address space requirements, a quick reference table is available over here
- Here’s a list of Gcloud commands that you may find useful
Deployment Guide
There are several ways to implement proposed deployment architecture
Irrespective of the approach you use, the resource creation flow would look like this:
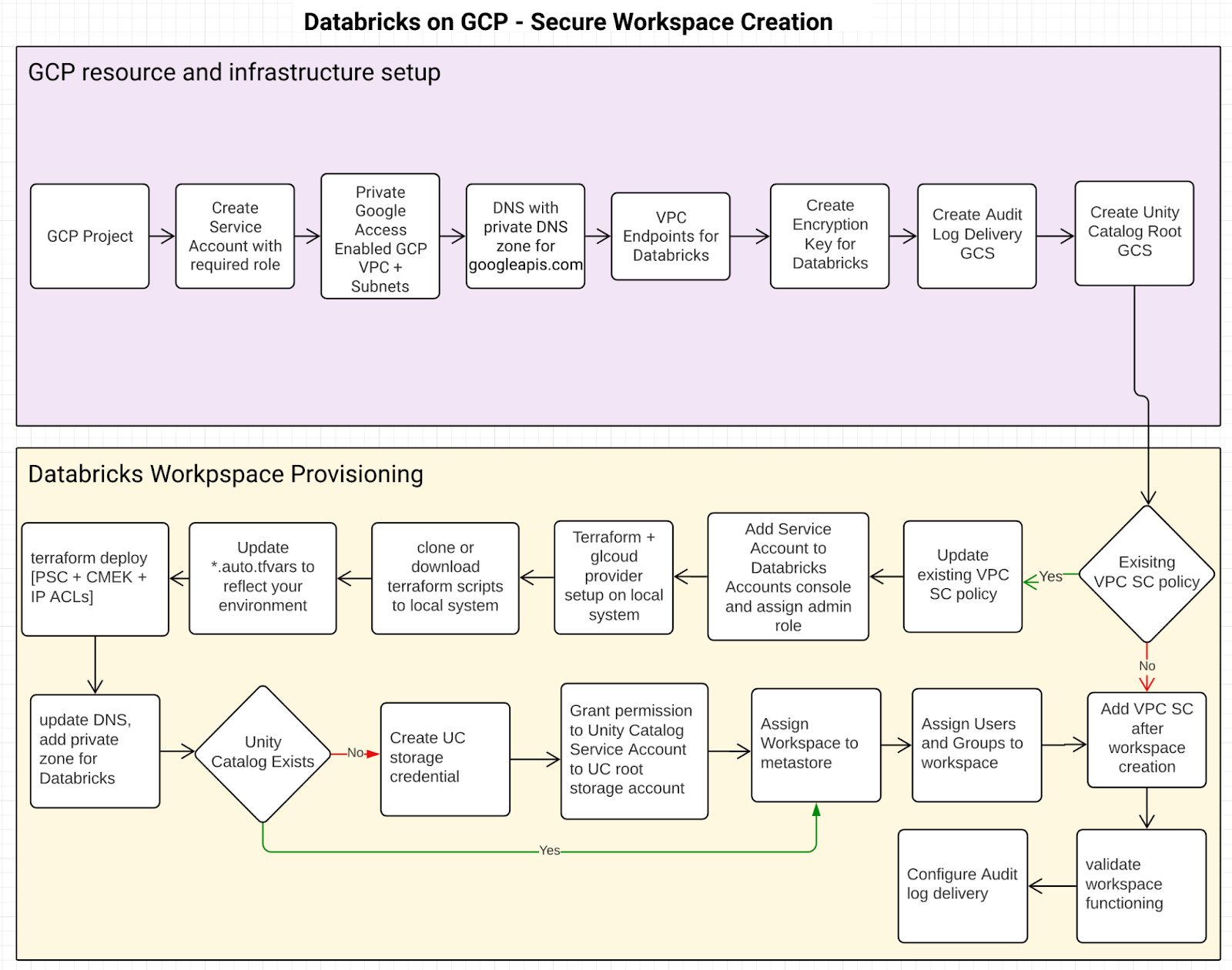
GCP resource and infrastructure setup
This is a prerequisite step. How the required infrastructure is provisioned, i.e. using Terraform or Gcloud or GCP cloud console, is out of the scope of this article. Here’s a list of GCP resources required:
| GCP Resource Type | Purpose | Details |
|---|---|---|
| Project | Create Databricks Workspace (ws) | Project requirements |
| Service Account | Used with Terraform to create workspace | Databricks Required Role and Permission. In addition to this you may also need additional permissions depending upon the GCP resources you are provisioning. |
| VPC + Subnets | One primary subnet per workspace | Network requirements |
| Private Google Access (PGA) | Keeps traffic between Databricks control plane VPC (ex: serverless compute plane) and your GCP resources private | Configure PGA |
| DNS for PGA | Private DNS zone for private api's | DNS Setup |
| Private Service Connect Endpoints | Makes Databricks control plane services available over private ip addresses. Private Endpoints need to reside in its own, separate subnet. |
Endpoint creation |
| Encryption Key | Customer-managed Encryption key used with Databricks | Cloud KMS-based key, supports auto key rotation. Key could be "software" or "HSM" aka hardware-backed keys. |
| Google Cloud Storage Account for Audit Log Delivery | Storage for Databricks audit log delivery | Configure log delivery |
| Google Cloud Storage (GCS) Account for Unity Catalog | Root storage for Unity Catalog | Configure Unity Catalog storage account |
| Add or update VPC SC policy | Add Databricks specific ingress and egress rules | Ingress & Egress yaml along with gcloud command to create a perimeter. Databricks projects numbers and PSC attachment URI's available over here |
| Add/Update Access Level using Access Context Manager | Add Databricks regional Control Plane NAT IP to your access policy so that ingress traffic is only allowed from an allow listed IP | List of Databricks regional control plane egress IP's available over here |
Create Workspace
- Clone Terraform scripts from here
- To keep things simple, grant project owner role to the GSA on the service and shared VPC project
- Update *.vars files as per your environment setup
| Variable | Details | |
|---|---|---|
| google_service_account_email | [NAME]@[PROJECT].iam.gserviceaccount.com | |
| google_project_name | PROJECT where dataplane will be created | |
| google_region | E.g. us-central1, supported regions | |
| databricks_account_id | Locate your account id | |
| databricks_account_console_url | https://accounts.gcp.databricks.com | |
| databricks_workspace_name | [ANY NAME] | |
| databricks_admin_user | Provide at least one user email id. This user will be made workspace admin upon creation. This is a required field. | |
| google_shared_vpc_project | PROJECT where VPC used by dataplane is located. If you are not using Shared VPC then enter the same value as google_project_name | |
| google_vpc_id | VPC ID | |
| node_subnet | NODE SUBNET name aka PRIMARY subnet | |
| cmek_resource_id | projects/[PROJECT]/locations/[LOCATION]/keyRings/[KEYRING]/cryptoKeys/[KEY] | |
| google_pe_subnet |
A dedicated subnet for private endpoints, recommended size /28. Please review network topology options available before proceeding. For this deployment we are using the “Host Databricks users (clients) and the Databricks dataplane on the same network” option. |
|
| workspace_pe | Unique name e.g. frontend-pe | |
| relay_pe | Unique name e.g. backend-pe | |
| relay_service_attachment | List of regional service attachment URI's | |
| workspace_service_attachment |
|
|
| private_zone_name | E.g. "databricks" | |
| dns_name | gcp.databricks.com. (. is required in the end) |
If you do not want to use IP access list and would like to completely lock down workspace access (UI and APIs) outside of your corporate network then you would need to:
- Comment out databricks_workspace_conf and databricks_ip_access_list resources in the workspace.tf
- Update databricks_mws_private_access_settings resource‘s public_access_enabled setting from true to false in the workspace.tf
- Please note that Public_access_enabled setting cannot be changed after the workspace is created
- Make sure that you have Interconnect Attachments aka vlanAttachments are created so that traffic from on premise networks can reach GCP VPC (where private endpoints exist) over dedicated interconnect connection.
Successful Deployment Check
Upon successful deployment, the Terraform output would look like this:
backend_end_psc_status = "Backend psc status: ACCEPTED"
front_end_psc_status = "Frontend psc status: ACCEPTED"
workspace_id = "workspace id: <UNIQUE-ID.N>"
ingress_firewall_enabled = "true"
ingress_firewall_ip_allowed = tolist([
"xx.xx.xx.xx",
"xx.xx.xx.xx/xx"
])
service_account = "Default SA attached to GKE nodes
databricks@<PROJECT>.iam.gserviceaccount.com"
workspace_url = "https://<UNIQUE-ID.N>.gcp.databricks.com"
Post Workspace Creation
- Validate that DNS records are created, follow this doc to understand required A records.
- Configure Unity Catalog (UC)
- Assign Workspace to UC
- Add users/groups to workspace via UC Identity Federation
- Auto provision users/groups from your Identity Providers
- Configure Audit Log Delivery
- If you are not using UC and would like to use Databricks managed hive then add an egress firewall rule to your VPC as explained here
Getting Started with Data Exfiltration Protection with Databricks on Google Cloud
We discussed utilizing cloud-native security control to implement data exfiltration protection for your Databricks on GCP deployments, all of which could be automated to enable data teams at scale. Some other things that you may want to consider and implement as part of this project are:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.