A Deep Dive into the Latest Performance Improvements of Stateful Pipelines in Apache Spark Structured Streaming
This post is the second part of our two-part series on the latest performance improvements of stateful pipelines. The first part of this series is covered in Performance Improvements for Stateful Pipelines in Apache Spark Structured Streaming - we recommend reading the first part before reading this post.
In the Project Lightspeed update blog, we provided a high-level overview of the various performance improvements we've added for stateful pipelines. In this section, we will dig deeper into the various issues we observed while analyzing performance and outline specific enhancements we have implemented to address those issues.
Improvements in the RocksDB State Store Provider
Memory Management
RocksDB primarily uses memory for memtables, the block cache, and other pinned blocks. Previously, all the updates within a micro-batch were buffered in memory using WriteBatchWithIndex. Additionally, users could only configure individual instance memory limits for write buffer and block cache usage. This allowed for unbounded memory use on a per-instance basis, compounding the problem when multiple state store instances were scheduled on a single worker node.
To address these problems, we now allow users to enforce bounded memory usage by leveraging the write buffer manager feature in RocksDB. This enables users to set a single global memory limit to control block cache, write buffer, and filter block memory use across state store instances on a single executor node. Moreover, we removed the reliance on WriteBatchWithIndex entirely so that updates are no longer buffered unbounded and instead written directly to the database.
Database Write/Flush Performance
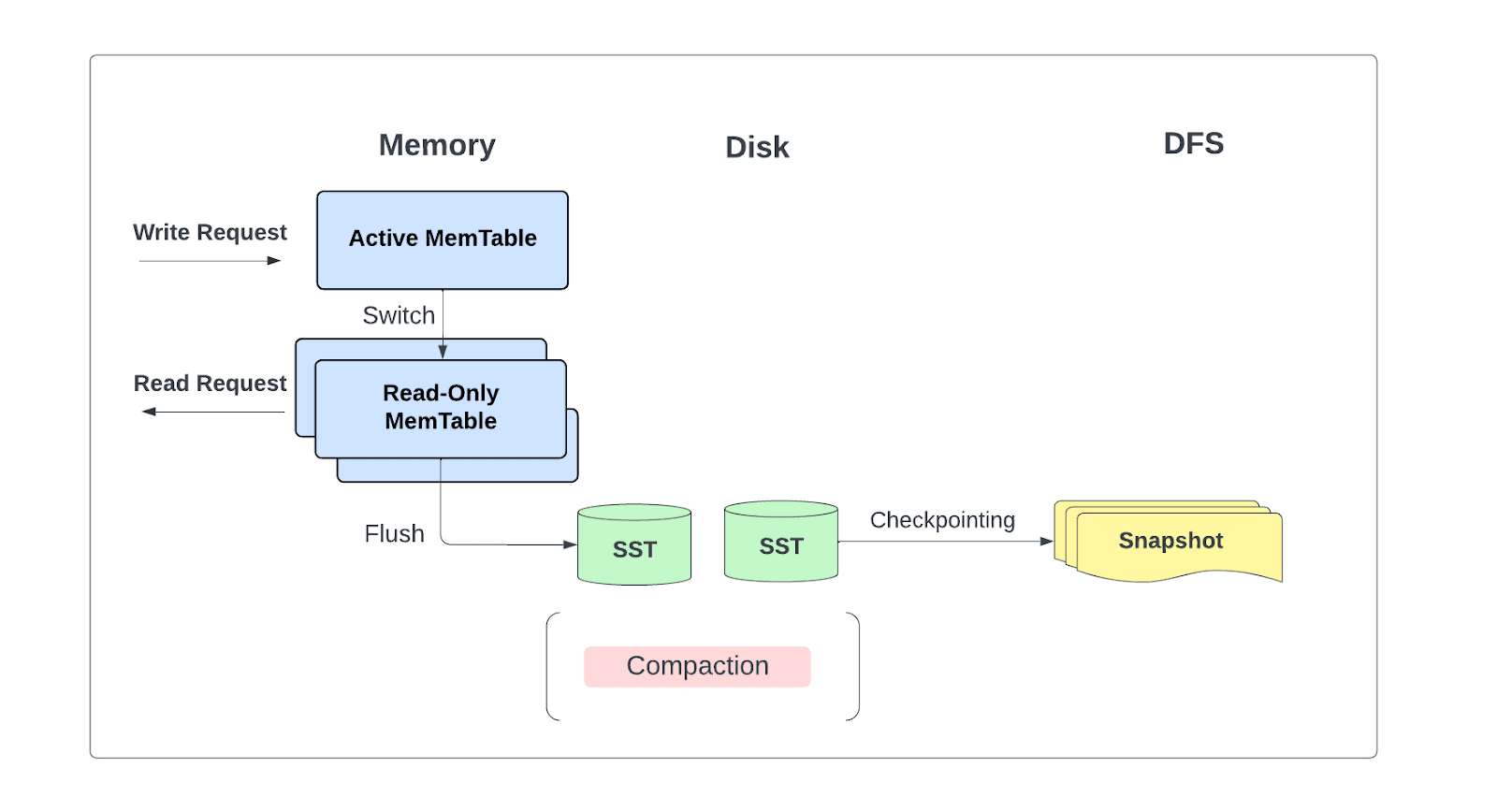
With the latest improvements, we no longer explicitly need the write ahead log (WAL) since all updates are safely written locally as SST files and subsequently backed to persistent storage as part of the checkpoint directory for each micro-batch.
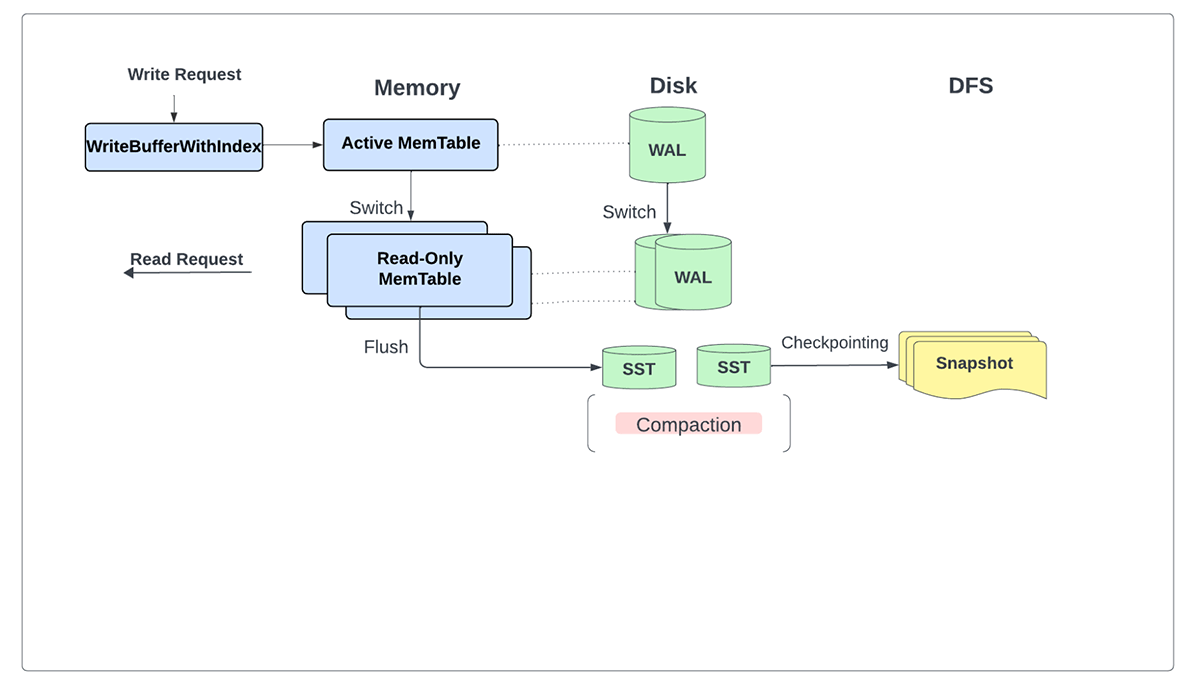
In addition to serving all reads and writes primarily from memory, this change allows us to flush writes to storage periodically when changelog checkpointing is enabled rather than on each micro-batch.
Changelog Checkpointing
We identified state checkpointing latency as one of the major performance bottlenecks for stateful streaming queries. This latency was rooted in the periodic pauses of RocksDB instances associated with background operations and the snapshot creation and upload process that was part of committing the batch.
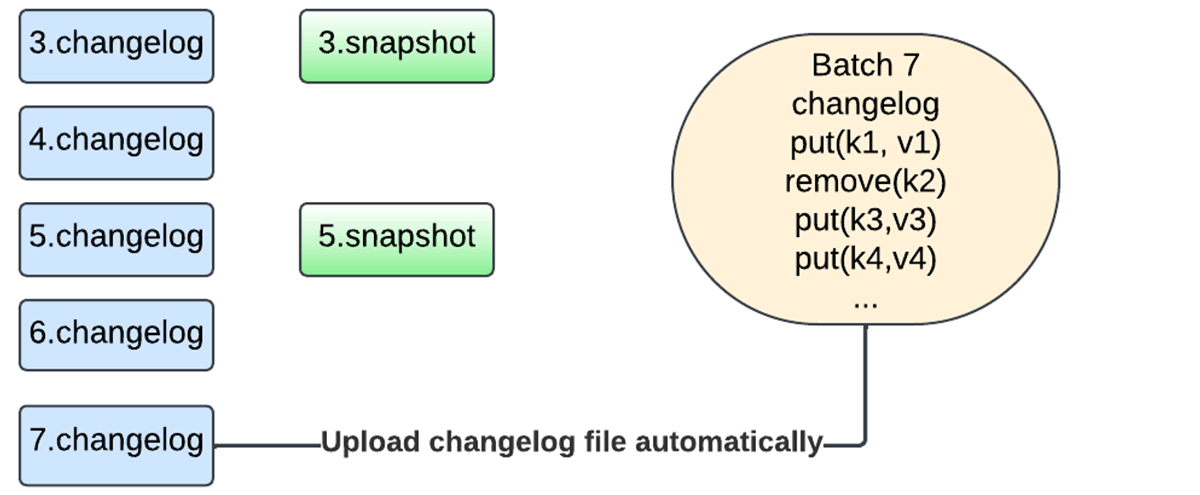
In the new design, we no longer need to snapshot the entire state to the checkpoint location. Instead, we are now leveraging changelog checkpointing, which makes the state of a micro-batch durable by storing just the changes since the last checkpoint on each micro-batch commit.
Moreover, the snapshotting process is now handled by the same database instance performing the updates, and the snapshots are uploaded asynchronously using the background maintenance task to avoid blocking task execution. The user now has the flexibility of configuring the snapshot interval to trade off between failure recovery and resource usage. Any version of the state can be reconstructed by picking a snapshot and replaying changelogs created after that snapshot. This allows for faster state checkpointing with the RocksDB state store provider.
The following sequence of figures captures how the new mechanism works.
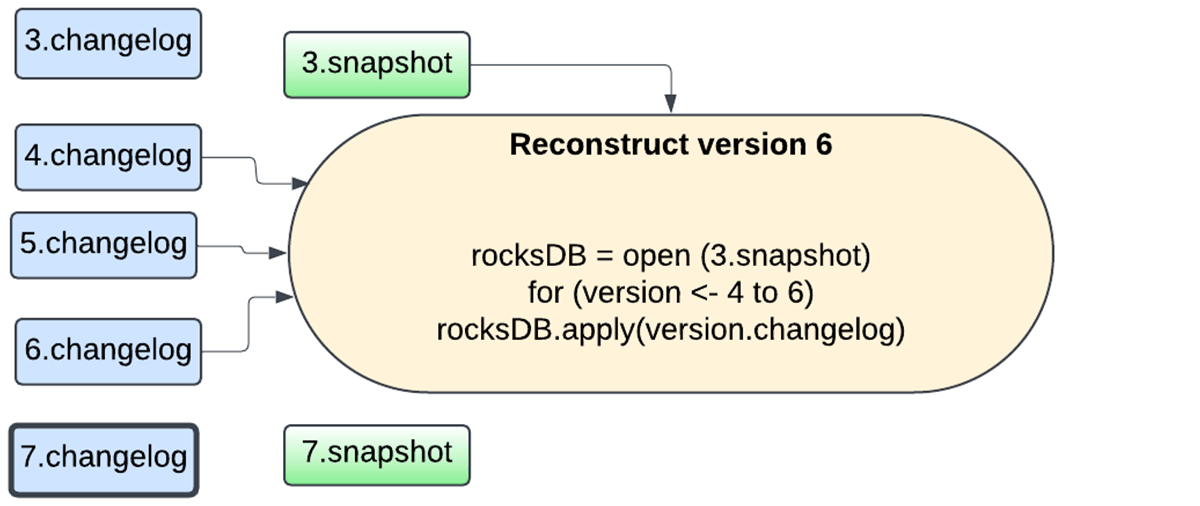
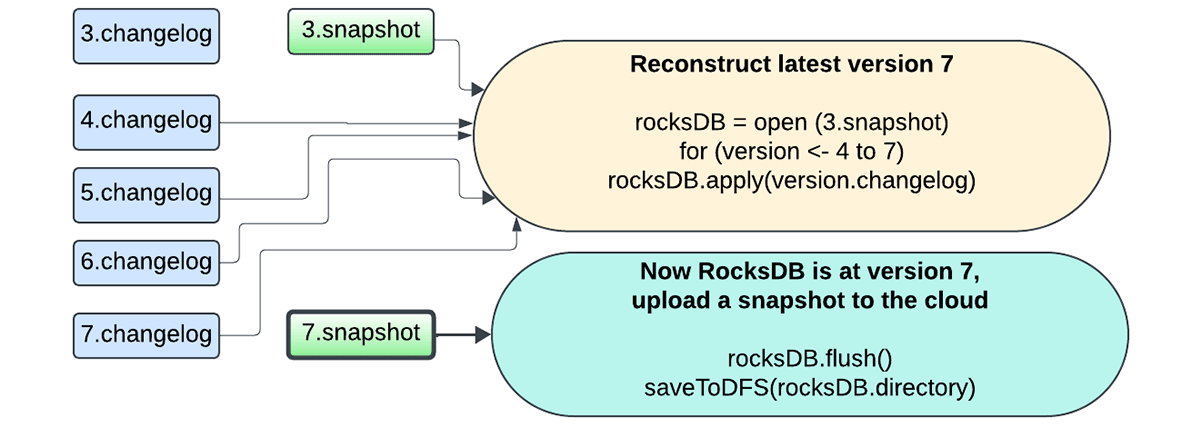
Sink-Specific Improvements
Once a stateful operation is complete, its state is saved to the state stores by calling commit. When the state has been saved successfully, the partition data (the executor's slice of the data) has to be written to the sink. The executor communicates with the output commit coordinator on the driver to ensure no other executor has committed results for that same slice of data. The commit can only go through after confirming that no other executors have committed to this partition; otherwise, the task will fail with an exception.
This implementation resulted in some undesired RPC delays, which we determined could be bypassed easily for sinks that only provide "at-least-once" semantics. In the new implementation, we have removed this synchronous step for all DataSource V2 (DSv2) sinks with at-least-once semantics, leading to improved latency. Note that end-to-end exactly-once pipelines use a combination of replayable sources and idempotent sinks, for which the semantic guarantees remain unchanged.
Operator-Specific and Maintenance Task Improvements
As part of Project Lightspeed, we also made improvements for specific types of operators, such as stream-stream join queries. For such queries, we now support parallel commits of state stores for all instances associated with a partition, thereby improving latency.
Another set of improvements we have made is related to the background maintenance task, primarily responsible for snapshotting and cleaning up the expired state. If this task fails to keep up, large numbers of delta/changelog files might accumulate, leading to slower replay. To avoid this, we now support performing the deletions of expired states in parallel and also running the maintenance task as part of a thread pool so that we are not bottlenecked on a single thread servicing all loaded state store instances on a single executor node.
Big Book of Data Engineering

Conclusion
We encourage our customers to try these latest improvements on their stateful Structured Streaming pipelines. As part of Project Lightspeed, we are focused on improving the throughput and latency of all streaming pipelines at lower TCO. Please stay tuned for more updates in this area in the near future!
Availability
All the features mentioned above are available from the DBR 13.3 LTS release.