How to execute your operating model for Data and AI
Teams and Roles

In Part 1 of this blog series, we discussed how Databricks enables organizations to develop, manage and operate processes that extract value from their data and AI. This time, we'll focus on team structure, team dynamics and responsibilities. To successfully execute your target operating model (TOM), different parts and teams within your organization need to be able to collaborate.
Prior to joining Databricks, I worked in consulting and delivered AI projects across industries and in a wide variety of technology stacks, from cloud native to open source. While the underlying technologies differed, the roles involved in developing and running these applications were roughly the same. Notice that I speak of roles and not of individuals; one person within a team can take on multiple roles depending on the size and complexity of the work at hand.
Having a platform that allows different teams or people with different roles like engineering, data science and analysts to work together using the same tools, to speak the same technical language and that facilitates the integration of work products is essential to achieve a positive Return on Data Assets (RODA).
When building the right team to execute on your operating model for AI, it is key to take into account the following elements:
- Maturity of your data foundation: Whether your data is still in silos, stuck in proprietary formats or difficult to access in a unified way will have big implications on the amount of data engineering work and data platform expertise that is required.
- Infrastructure and platform administration: Whether you need to maintain or leverage 'as-a-service' offerings can greatly impact your overall team composition. Moreover, suppose your data platform is made up of multiple services and components. In that case, the administrative burden of governing and securing data and users and keeping all parts working together can be overwhelming, especially at enterprise scale.
- MLOps: To make the most of AI, you need to apply it to impact your business. Hiring a full data science team without the right ML engineering expertise or tools to package, test, deploy and monitor is extremely wasteful. Several steps go into running effective end-to-end AI applications, and your operating model should reflect that in the roles involved and in the way model lifecycle management is executed – from use case identification to development to deployment to (perhaps most importantly) utilization.
These three attributes inform your focus and the roles that should be part of your development team. Over time, the prevalence of certain roles might shift as your organization matures along these dimensions and on your platform decisions.
Because the development of data and AI applications is a highly iterative process, it's critical that accompanying processes enable teams to work closely together and reduce friction when handovers are made. The diagram below illustrates the end-to-end flow of what your operating model may look like and the roles and responsibilities of the various teams.
Gartner®: Databricks Cloud Database Leader

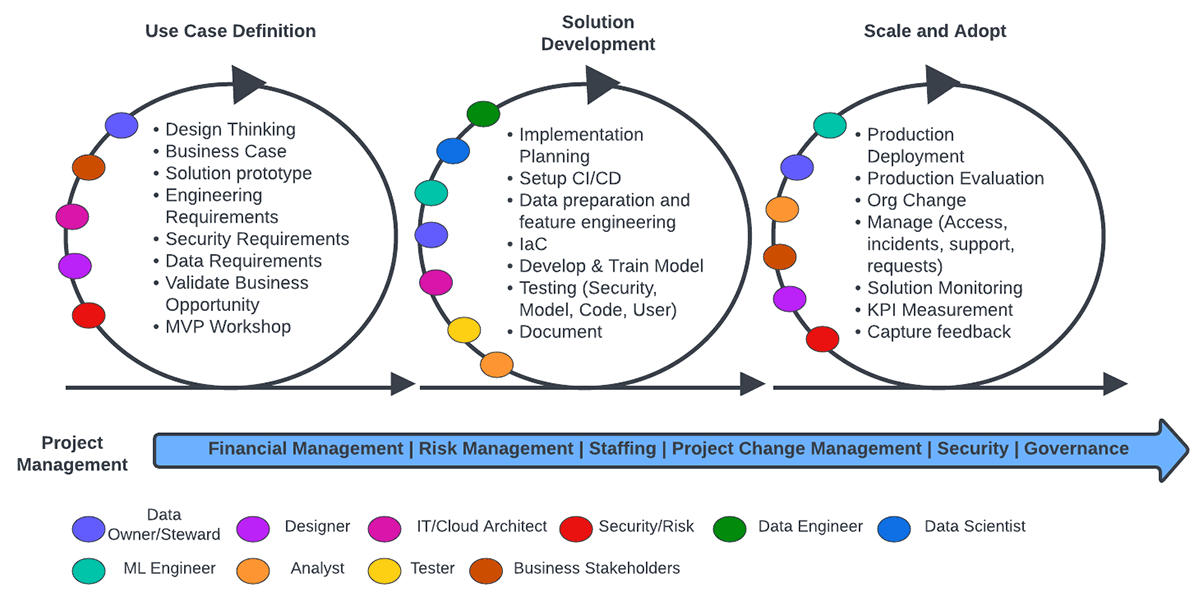
Above, we see three core stages that are part of an iterative end-to-end operating pipeline both within and across loops. Each benefit from a combination of roles to extract the most value from them. Furthermore, there is an ongoing project management function that enacts the operational motion and ensures that the right resources and processes are available for each team to execute across the three stages. Let's walk through each of these stages.
- Use Case Definition: When defining your project's use case, it is important to work with business stakeholders to align data and technical capabilities to business objectives. A crucial step here is identifying the data requirements, thus, having data owners participate is critical to inform the feasibility of the use case, as is understanding whether the data platform can support it, something that platform owners/architects need to validate. The other elements that are highlighted at this stage are geared towards ensuring the usability of the desired solution both in terms of security and user experience.
- Solution Development: This stage focuses primarily on technical development. Here is where the core ML/AI development cycle, driven by the data engineering, data science and ML engineering teams takes place, along with all the ancillary steps and elements needed to test, validate and package the solution. This stage represents the inner loop of MLOps where the onus is on experimentation. Data owners and architects remain critical at this stage to enable the core development team with the right source materials and tools.
- Scale and Adopt: In a business context, an ML/AI application is only useful if it can be used to affect the business positively, therefore, business stakeholders need to be intimately involved. The main objective at this stage is to develop and operate the right mechanisms and processes to enable end-users to consume and utilize the application outputs. And because business is not static, continuous monitoring of performance and KPIs and the implementation of feedback loops back to the development and data teams are fundamental at this stage.
This operating process is just one example; specific implementations will depend on the structure of your organization. Various configurations – from centralized to CoE to federated – are certainly possible, but the principles described by the flow above will remain applicable regarding roles and responsibilities.
Conclusion
Developing data and AI projects and applications requires a diverse team and roles. Moreover, new organizational paradigms centered around data exacerbate the need for an AI operating model that can support the new roles within a data-forward organization effectively.
Finally, it is worthwhile to highlight once more that a (multi-cloud) platform that can help simplify and consolidate the whole gamut of infrastructure, data and tooling requirements, as well as support the required business processes that must run on top of it while at the same time facilitating clear reporting, monitoring and KPI tracking, is a huge asset. This allows diverse, cross-functional teams to work together more effectively, accelerating time to production and fostering innovation.
If you want to learn more about the principles and how to design your operating model for Data and AI you can check out Part 1 of this blog series