How Verana Health Uses the Databricks Lakehouse to Democratize Data and Deploy AI for Medical Innovation

This blog post is in collaboration with Lawrence Whittle (Chief Commercial Officer) at Verana Health.
Across industries, data scientists spend up to 80% of their time trying to properly prepare and cleanse datasets for data mining and artificial intelligence (AI). For clinical researchers, life science analysts, and healthcare professionals, this challenge is amplified by the added regulatory burdens around healthcare data, requiring patient data to be anonymized while still providing demographic and population information necessary to correct for bias. The data challenge in healthcare is exacerbated by the fact that up to 80% of the data is unstructured.
This is why Verana Health came into existence. In partnership with three leading medical societies, we have built an exclusive, real-world data network of more than 20,000 healthcare clinicians, approximately 90 million de-identified patients and more than 500 million patient visits. By providing high-quality, curated datasets (Qdata®), ready for exploration by researchers and data scientists, we can help clinicians and life sciences companies accelerate medical innovation.
Our Verana Health customers and partners utilize these datasets to help identify trial patients, understand population-level impact of public health policy decisions, and monitor the safety and treatment patterns of patients receiving their drugs. When you consider that the average drug discovery process takes about a decade and costs about $1-2 billion per drug, accelerating the process by even a single month could translate into tens of millions of dollars in savings or accelerated revenue. The real difference between Verana Health's Qdata offerings, compared to the general data market, is quality. Quality is defined across multiple dimensions such as cohort size, longitudinal nature (~10 years of data), and most importantly, depth of variables that are a direct result of our approach to harvest previously untapped variables from unstructured data that has historically been locked in clinical notes and images.
So, how do we turn all of that data into insights? We use the Databricks Lakehouse to ingest, process, and organize our petabyte-scale data warehouse of health information.
Verana Health runs on Databricks Lakehouse
The Databricks and Verana Health collaboration is a critical element for the provision of high-quality datasets to the life sciences and clinician marketplace. The integrated solutions normalize and curate petabytes of health information across three therapeutic areas of neurology, ophthalmology and urology. This enables Verana Health to leverage the data for clinical trial optimization, real-world evidence studies, population health analytics, and publication of Merit-based Incentive Payment System quality measures for Centers for Medicare and Medicaid Services (CMS) reporting.
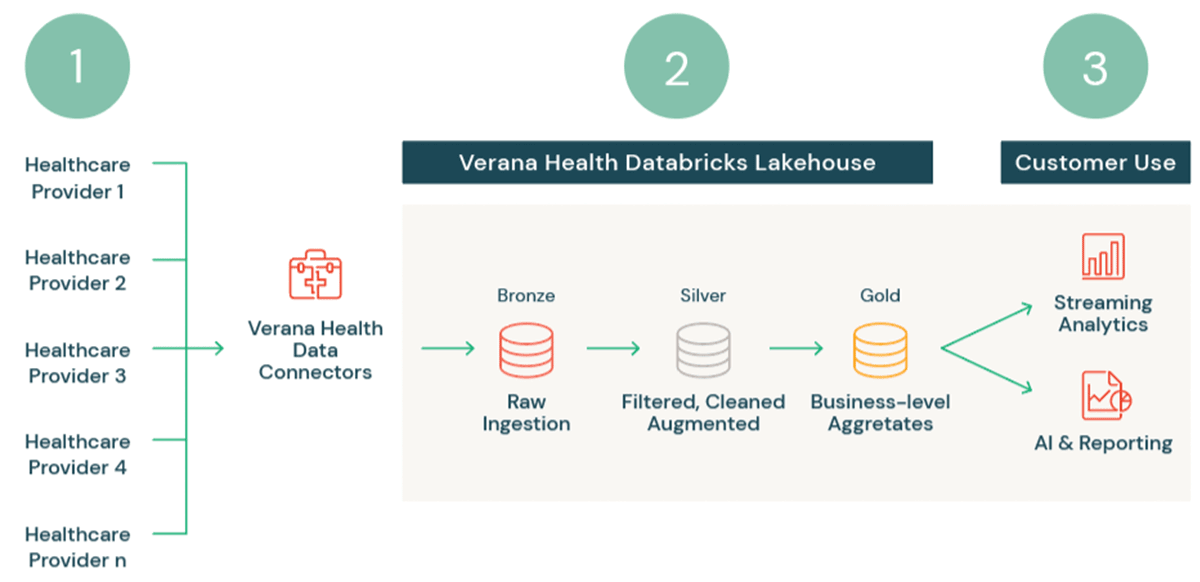
To start, we pull the data into the Lakehouse from our exclusive network of specialty medical society partners using purpose-built data connectors to ensure patient confidentiality (1). We then leverage Delta Lake's multi-hop architecture (bronze, silver, gold) to progressively cleanse, prepare, and organize the data for downstream usage (2).
- Raw data is ingested as bronze tables.
- Each source clinician might use different formats or schema for their electronic health records, so data is normalized, cleansed, and organized in silver. Further transformations, such as de-identification, are applied for the gold tables (2). Natural language processing can also be applied at this stage to, for example, convert free-form clinician notes into usable variables.
- These gold tables are now ready to be shared with our customers as fully cleansed and prepped data products for use in analytics and AI (3).
With the Databricks Unity Catalog, we are able to centralize access control, auditing, lineage, and data discovery across Databricks workspaces. Specifically, we can define and control access down to the table, column, and row level — ensuring the right data is shared with a researcher without requiring him/her to filter through large chunks of unnecessary data. This has saved enormous amounts of time and compute costs.
Helping scientists collaborate better and faster
Our Verana Health data scientists utilize Databricks notebooks for interactive exploration as well as code development. An easy-to-use web interface allows them to work in preferred languages such as SQL, Python, and R (even within the same notebook). Results can be placed directly into dashboards and in-line visualizations, as well as exported to external tools such as Tableau and Google Docs. Notebooks and code are easily managed with source control (git), separate from data and results.
Complex analyses can be created leveraging workflows, which allows our Verana Health data scientists to orchestrate complex calculations by connecting individual analyses and code. Workflows can then be run manually, automatically triggered by arrival of new data, or on a schedule. Complete results, execution time metrics, and messages are accessible during and after runs. This saves scientists significant time, compared to running complex calculations interactively.
Behind the scenes, Databricks provides rich features for performance tuning and cost optimization. These include a natively compiled Apache Spark implementation (Photon acceleration), which allows analyses to run up to 20% faster; and non-interactive job clusters, which can be used within workflows for additional 20% performance gain. Other key features include Delta tables, which allow our data scientists to assemble very large datasets incrementally–and extract versions by date or tag. This supports fully reproducible results without the cost and complexity of managing multiple copies.
Maximizing real-world data for unprecedented healthcare insights
Verana Health is at the forefront of digital health, leveraging its extensive real-world data network and strategic collaborations to revolutionize healthcare. With Databricks, Verana Health is able to maximize the value of its vast amounts of data, enabling the delivery of high-quality datasets and empowering researchers, analysts, and clinicians.
Through Databricks' advanced capabilities, Verana Health can efficiently analyze and explore complex health information, collaborate seamlessly, and generate valuable insights. The integration of Databricks, with Verana Health's platform, enhances our ability to optimize clinical trials, conduct real-world evidence studies, drive population health analytics, and support CMS reporting. By combining cutting-edge technology with deep expertise, Verana Health and Databricks are driving innovation and propelling the healthcare industry forward.
Never miss a Databricks post
What's next?

Healthcare & Life Sciences
November 14, 2024/2 min read
Providence Health: Scaling ML/AI Projects with Databricks Mosaic AI

Product
November 27, 2024/6 min read