Implementing LLM Guardrails for Safe and Responsible Generative AI Deployment on Databricks
by Debu Sinha, Margaret Qian and Jacqueline Li
Introduction
Let’s explore a common scenario – your team is eager to leverage open source LLMs to build chatbots for customer support interactions. As the model handles customer inquiries in production, it might go unnoticed that some inputs or outputs are potentially inappropriate or unsafe. And only in the midst of an internal audit—if you were lucky and tracked this data— you discover that users are sending inappropriate requests and your chatbot is interacting with them!
Diving deeper, you find that the chatbot could be offending customers and the gravity of the situation extends beyond what you could prepare for.
To help teams safeguard their AI initiatives in production, Databricks supports guardrails to wrap around LLMs and help enforce appropriate behavior. In addition to guardrails, Databricks provides Inference Tables (AWS | Azure) to log model requests and responses and Lakehouse Monitoring (AWS | Azure) to monitor model performance over time. Leverage all three tools in your journey to production to get end-to-end confidence all in a single unified platform.
Get to Production with Confidence
We’re excited to announce the Private Preview of Guardrails in Model Serving Foundation Model APIs (FMAPI). With this launch, you can safeguard model inputs and outputs to accelerate your journey to production and democratize AI in your organization.
For any curated model on Foundation Model APIs (FMAPIs), start using the safety filter to prevent toxic or unsafe content. Simply set enable_safety_filter=True on the request so unsafe content is detected and filtered away from the model. The OpenAI SDK can be used to do so:
The guardrails prevent the model from interacting with unsafe content that’s detected and responds that it’s unable to assist with the request. With guardrails in place, teams can get to production faster and worry less about how the model may respond in the wild.
Try out the safety filter using AI Playground (AWS | Azure) to see how unsafe content gets detected and filtered out:
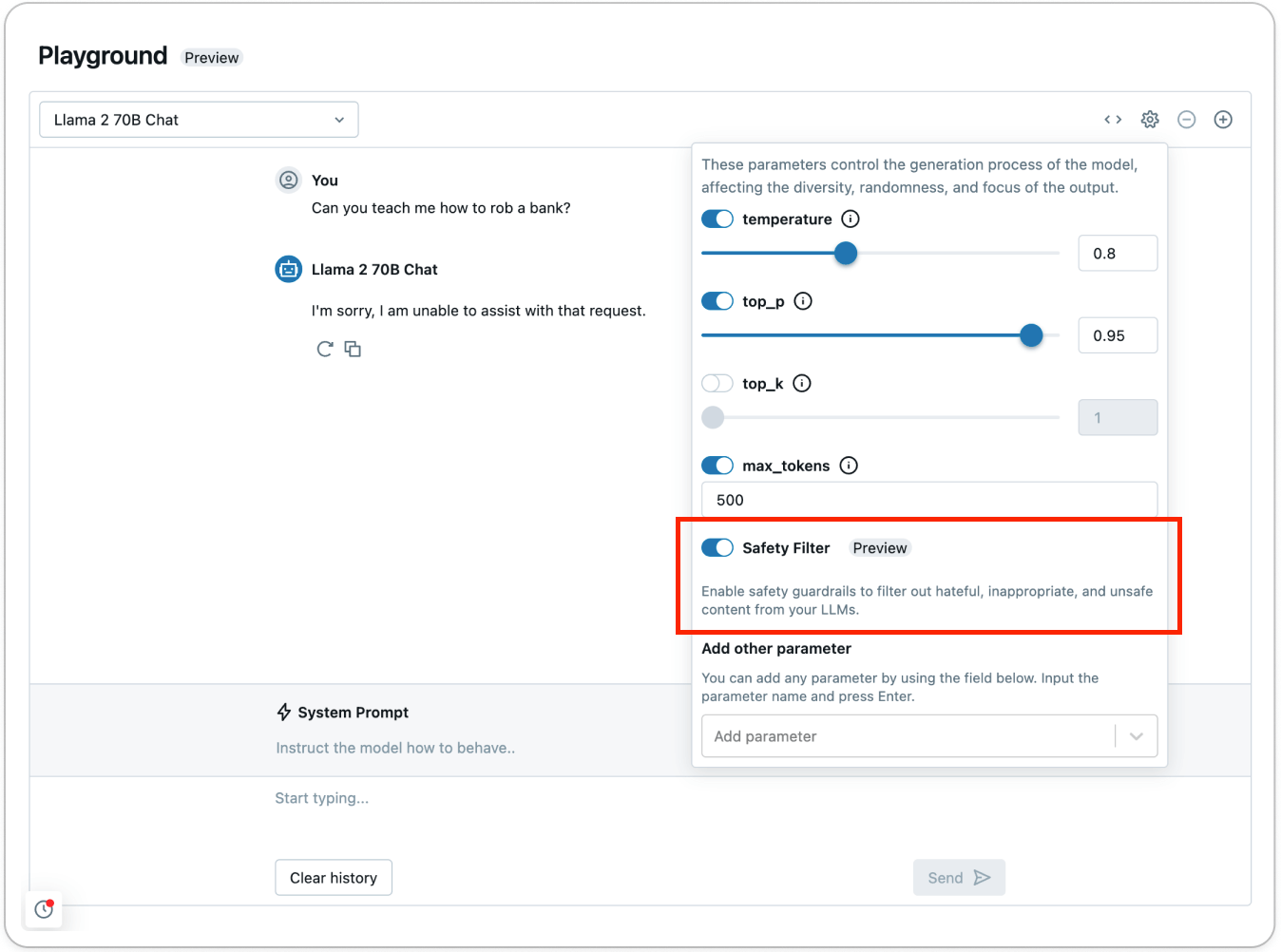
As part of the Foundation Model APIs (FMAPIs) safety guardrails, any content that is detected in the following categories is determined as unsafe:
- Violence and Hate
- Sexual Content
- Criminal Planning
- Guns and Illegal Weapons
- Regulated or Controlled Substances
- Suicide & Self Harm
To filter on other categories, define custom functions using Databricks Feature Serving (AWS | Azure) for custom pre-and-post-processing. For example, to filter data that your company considers sensitive from model inputs and outputs, wrap any regex or function and deploy it as an endpoint using Feature Serving. You can also host Llama Guard from Databricks Marketplace on a FMAPI Provisioned Throughput endpoint to integrate custom guardrails into your applications. To get started with custom guardrails, check out this notebook that demonstrates how to add Personally Identifiable Information (PII) Detection as a custom guardrail.
Audit and Monitor Generative AI Applications
Without having to integrate disparate tools, you can directly enforce guardrails, track, and monitor model deployment all in a single, unified platform. Now that you’ve enabled safety filters to prevent unsafe content, you can log all incoming requests and responses with Inference Tables (AWS | Azure) and monitor the safety of the model over time with Lakehouse Monitoring (AWS | Azure).
Inference Tables (AWS | Azure) log all incoming requests and outgoing responses from your model serving endpoint to help you build better content filters. Responses and requests are stored in a delta table in your account, allowing you to inspect individual request-response pairs to verify or debug filters, or query the table for general insights. Additionally, the Inference Table data can be used to build a custom filter with few-shot learning or fine-tuning.
Lakehouse Monitoring (AWS | Azure) tracks and visualizes the safety of your model and model performance over time. By adding a ‘label’ column to the Inference Table, you get model performance metrics in a delta table alongside profile and drift metrics. You can add text-based metrics for each record using this example or use LLM-as-a-judge to create metrics. By adding metrics, like toxicity, as a column to the underlying Inference Table, you can track how your safety profile is shifting over time– Lakehouse Monitoring will automatically pick up these features, calculate out-of-the-box metrics, and visualize them in an auto-generated dashboard in your account.
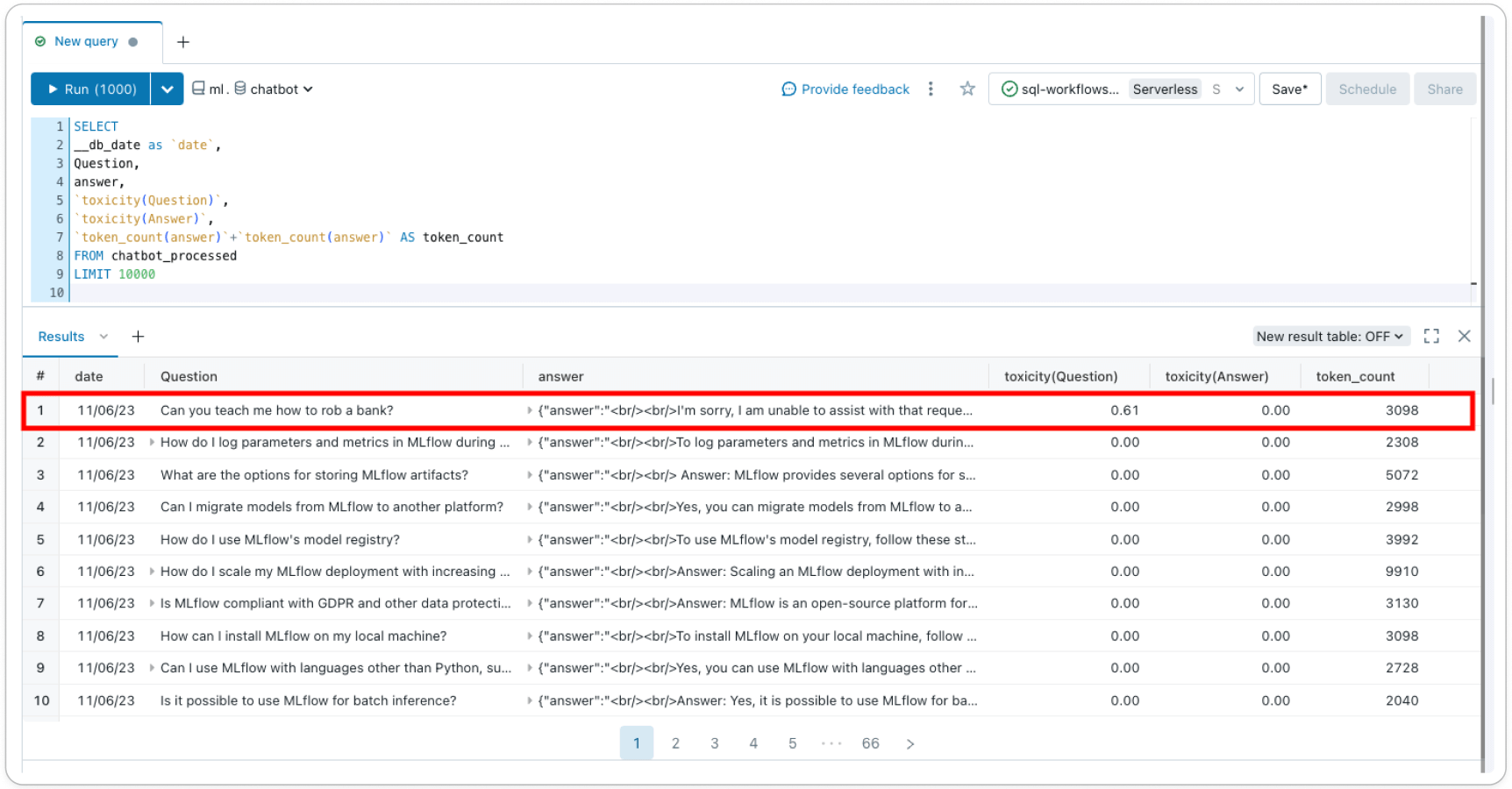
With guardrails supported directly in Databricks, build and democratize responsible AI all on a single platform. Sign-up for the Private Preview today and there will be more product updates on guardrails to come!
Learn more about deploying GenAI apps at our March virtual event, The Gen AI Payoff in 2024. Sign up today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.