Ingest data from SQL Server, Salesforce, and Workday with Lakeflow Connect
Simple and efficient ingestion connectors are now in Public Preview

We’re excited to announce the Public Preview of Lakeflow Connect for SQL Server, Salesforce, and Workday. These ingestion connectors enable simple and efficient ingestion from databases and enterprise apps—powered by incremental data processing and smart optimizations under the hood. Lakeflow Connect is also native to the Data Intelligence Platform, so it offers both serverless compute and Unity Catalog governance. Ultimately, this means organizations can spend less time moving their data and more time getting value from it.
More broadly, this is a key step towards realizing the future of data engineering on Databricks with Lakeflow: the unified solution for ingestion, transformation and orchestration that we announced at Data + AI Summit. Lakeflow Connect will work seamlessly with Lakeflow Pipelines for transformation and Lakeflow Jobs for orchestration. Together, these will enable customers to deliver fresher and higher-quality data to their businesses.
Challenges in data ingestion
Organizations have a wide range of data sources: enterprise apps, databases, message buses, cloud storage, and more. To address the nuances of each source, they often build and maintain custom ingestion pipelines, which introduces several challenges.
- Complex configuration and maintenance: It’s difficult to connect to databases, especially without impacting the source system. It’s also hard to learn and keep up with ever-changing application APIs. Therefore, custom pipelines require a lot of effort to build, optimize, and maintain—which can, in turn, limit performance and increase costs.
- Dependencies on specialized teams: Given this complexity, ingestion pipelines often require highly skilled data engineers. This means that data consumers (e.g., HR analysts, and financial planners) depend on specialized engineering teams, thus limiting productivity and innovation.
- Patchwork solutions with limited governance: With a patchwork of pipelines, it’s hard to build governance, access control, observability, and lineage. This opens the door to security risks and compliance challenges, as well as difficulties in troubleshooting any issues.
Lakeflow Connect: simple and efficient ingestion for every team
Lakeflow Connect addresses these challenges so that any practitioner can easily build incremental data pipelines at scale.
Lakeflow Connect is simple to configure and maintain
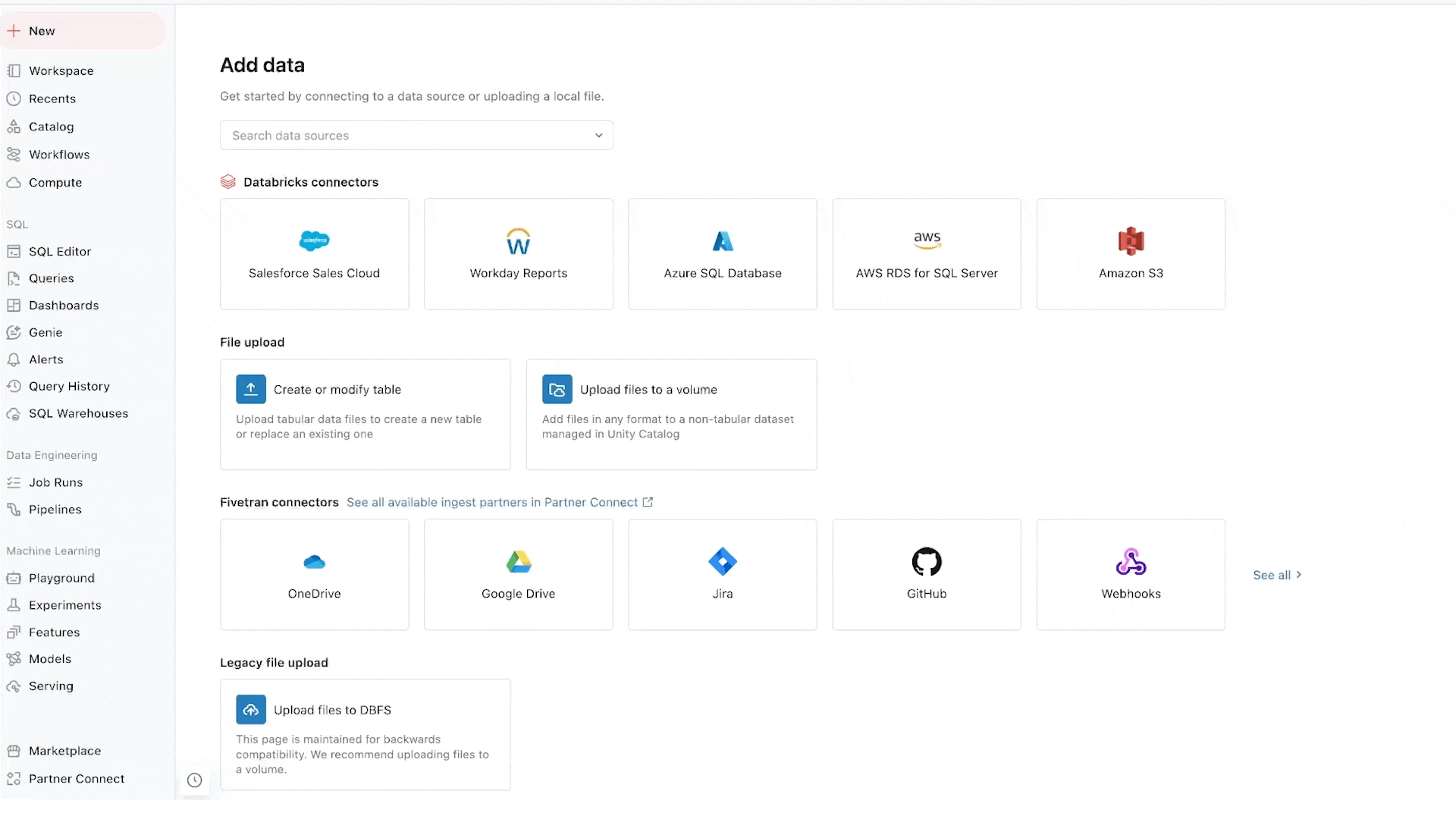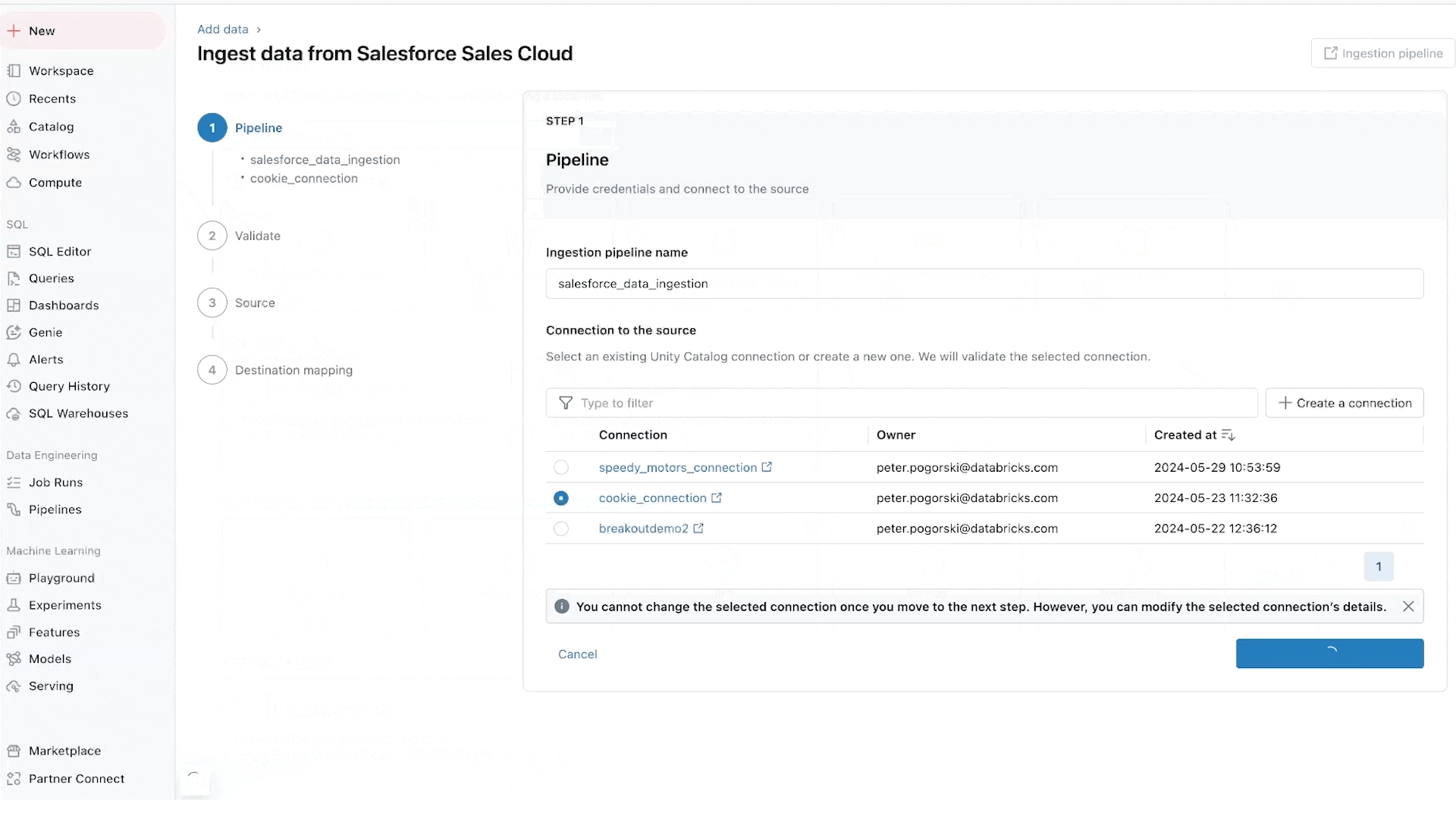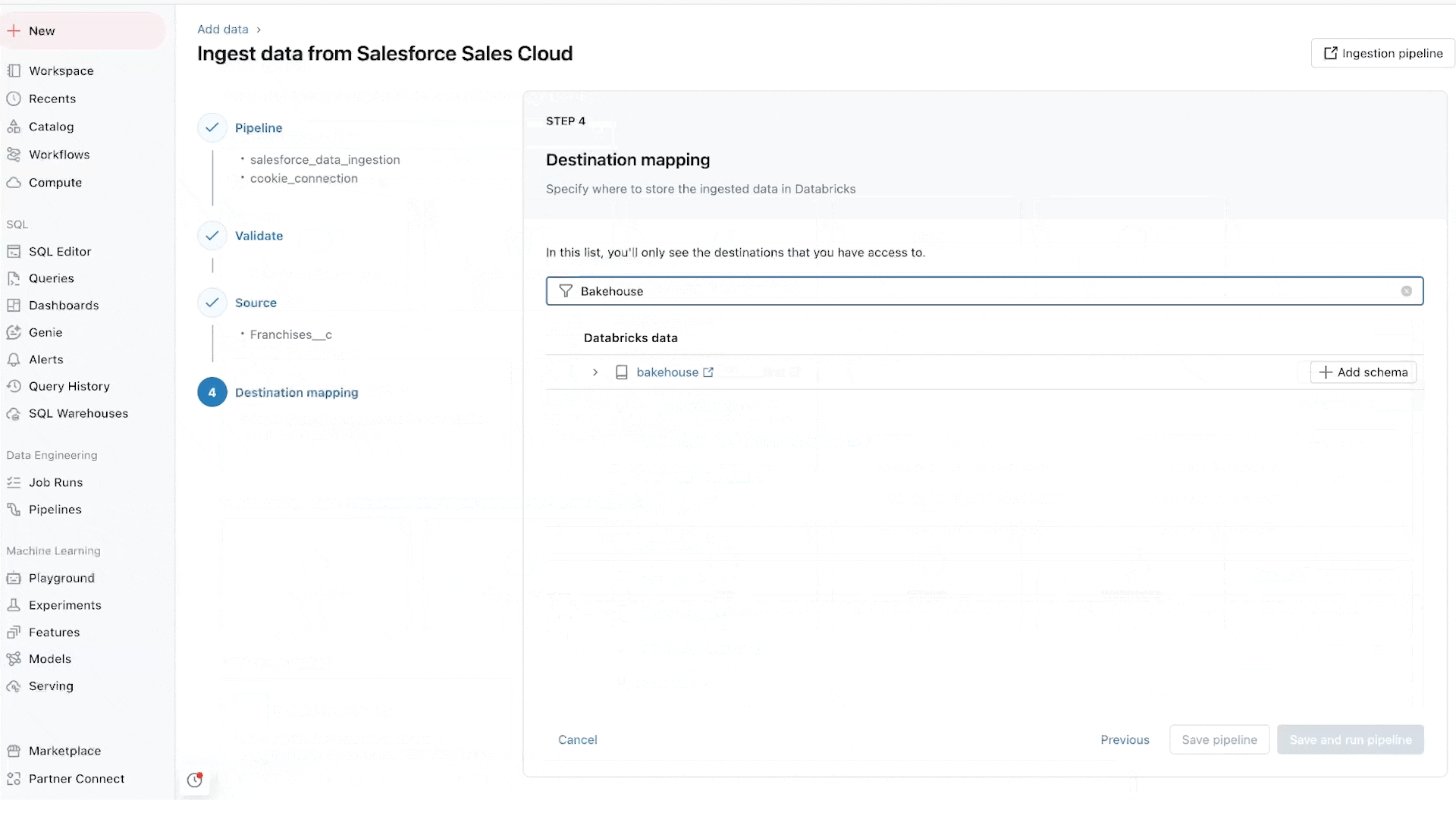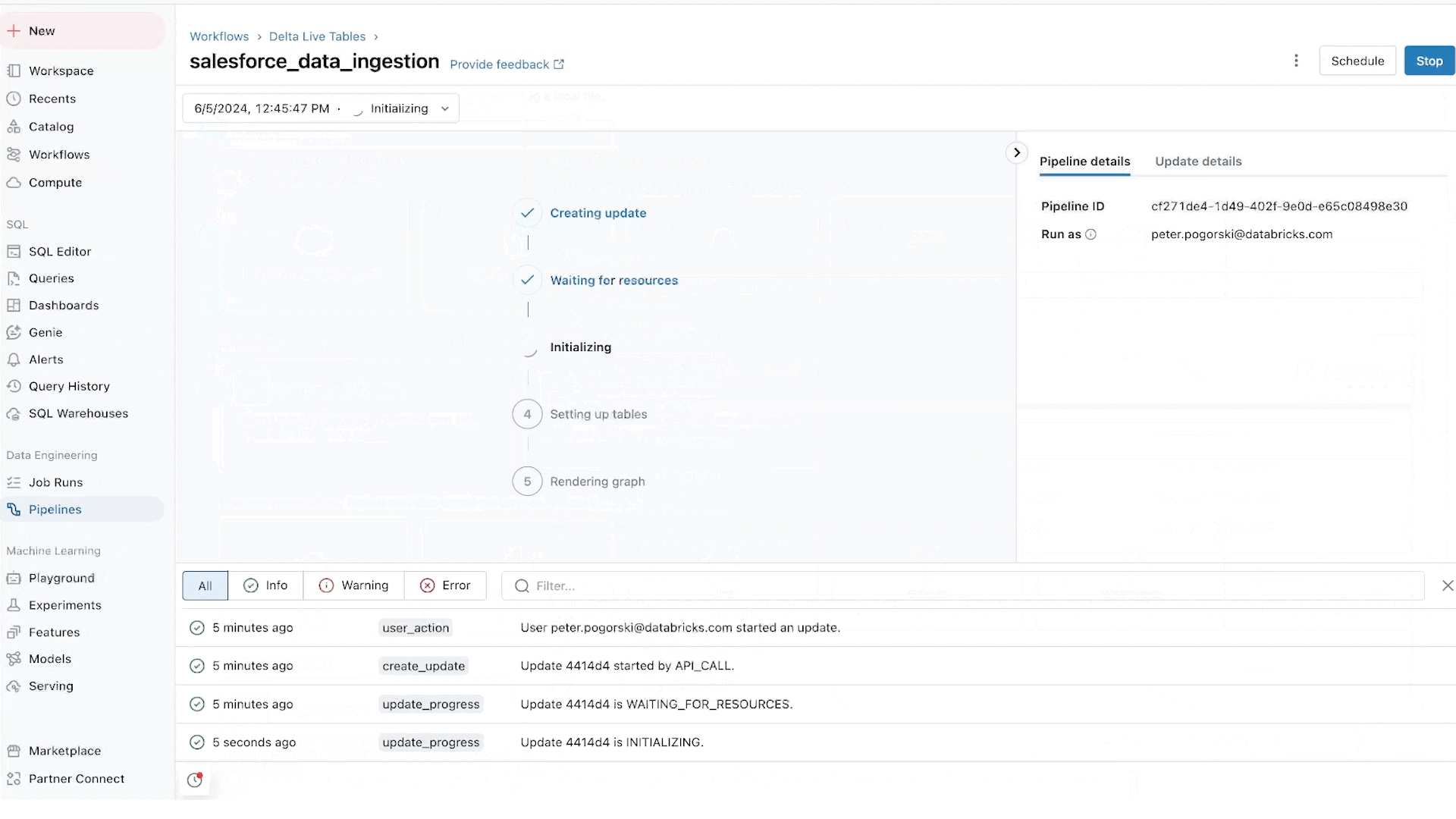
To start, the connectors take as little as just a few steps to set up. Moreover, once you’ve set up a connector, it’s fully managed by Databricks. This lowers the costs of maintenance. It also means that ingestion no longer requires specialized knowledge—and that data can be democratized across your organization.
“The Salesforce connector was simple to set up and provides the ability to sync data to our data lake. This has saved a great deal of development time and ongoing support time making our migration faster” — Martin Lee, Technology Lead Software Engineer, Ruffer
Lakeflow Connect is efficient
Under the hood, Lakeflow Connect pipelines are built on Delta Live Tables, which are designed for efficient incremental processing. Moreover, many of the connectors read and write only the data that’s changed in the source system. Finally, we leverage Arcion’s source-specific technology to optimize each connector for performance and reliability while also limiting impact on the source system.
Because ingestion is just the first step, we don’t stop there. You can also construct efficient materialized views that incrementally transform your data as it works its way through the medallion architecture. Specifically, Delta Live Tables can process updates to your views incrementally—only updating the rows that need to change rather than fully recomputing all rows. Over time, this can significantly improve the performance of your transformations, which in turn makes your end-to-end ETL pipelines just that much more efficient.
"The connector enhances our ability to transfer data by providing a seamless and robust integration between Salesforce and Databricks. [...] The time required to extract and prepare data has been reduced from approximately 3 hours to just 30 minutes” — Amber Howdle-Fitton, Data and Analytics Manager, Kotahi
Lakeflow Connect is native to the Data Intelligence Platform
Lakeflow Connect is fully integrated with the rest of your Databricks tooling. Like the rest of your data and AI assets, it's governed by Unity Catalog, powered by Delta Live Tables using serverless compute, and orchestrated with Databricks Workflows. This enables features like unified monitoring across your ingestion pipelines. Moreover, because it’s all part of the same platform, you can then use Databricks SQL, AI/BI and Mosaic AI to get the most out of your data.
"With Databricks' new Lakeflow Connector for SQL Server, we can eliminate [...] intermediary products between our source database and Databricks. This means faster data ingestion, reduced costs, and less effort spent configuring, maintaining, and monitoring third-party CDC solutions. This feature will greatly benefit us by streamlining our data pipeline." — Kun Lee, Senior Director Database Administrator, CoStar
Gartner®: Databricks Cloud Database Leader

An exciting Lakeflow roadmap
The first wave of connectors can create SQL Server, Salesforce, and Workday pipelines via API. But this Public Preview is only the beginning. In the coming months, we plan to begin Private Previews of connectors to additional data sources, such as:
- ServiceNow
- Google Analytics 4
- SharePoint
- PostgreSQL
- SQL Server on-premises
The roadmap also includes a deeper feature set for each connector. This may include:
- UI for connector creation
- Data lineage
- SCD type 2
- Robust schema evolution
- Data sampling
More broadly, Lakeflow Connect is only the first component of Lakeflow. Later this year, we plan to preview Lakeflow Pipelines for transformation and Lakeflow Jobs for orchestration—the evolution of Delta Live Tables and Workflows, respectively. Once they’re available, they will not require any migration. The best way to prepare for these new additions is to start using Delta Live Tables and Workflows today.
Getting started with Lakeflow Connect
SQL Server connector: Supports ingestion from Azure SQL Database and AWS RDS for SQL Server, with incremental reads that use change data capture (CDC) and change tracking technology. Learn more about the SQL Server Connector.
Salesforce connector: Supports ingestion from Salesforce Sales Cloud, allowing you to join these CRM insights with data in the Data Intelligence Platform to deliver additional insights and more accurate predictions. Learn more about the Salesforce connector.
Workday connector: Supports ingestion from Workday Reports-as-a-Service (RaaS), allowing you to analyze and enrich your reports. Learn more about the Workday connector.
"The Salesforce connector provided in Lakeflow Connect has been crucial for us, enabling direct connections to our Salesforce databases and eliminating the need for an additional paid intermediate service." — Amine Hadj-Youcef, Solution Architect, Engie
To get access to the preview, contact your Databricks account team.
Note that Lakeflow Connect uses serverless compute for Delta Live Tables. Therefore:
- Serverless compute must be enabled in your account (see how to do so for Azure or AWS, and see a list of serverless-enabled regions for Azure or AWS)
- Your workspace must be enabled for Unity Catalog.
For further guidance, refer to the Lakeflow Connect documentation.