Intelligent Kubernetes Load Balancing at Databricks
Real-Time, Client-Side Load Balancing for Internal and Ingress Traffic in Kubernetes
by Gaurav Nanda, Vincent Cheng and Rohit Agrawal
- Why Kubernetes’ default load balancing falls short for high-throughput, persistent connections like gRPC, especially at Databricks scale.
- How we built a client-side, control-plane-driven load balancing system using custom rpc client and xDS.
- Trade-offs of alternative approaches like headless services and Istio, and why we chose a lightweight, client-driven model.
Introduction
At Databricks, Kubernetes is at the heart of our internal systems. Within a single Kubernetes cluster, the default networking primitives like ClusterIP services, CoreDNS, and kube-proxy are often sufficient. They offer a simple abstraction to route service traffic. But when performance and reliability matter, these defaults begin to show their limits.
In this post, we’ll share how we built an intelligent, client-side load balancing system to improve traffic distribution, reduce tail latencies, and make service-to-service communication more resilient.
If you are a Databricks user, you don’t need to understand this blog to be able to use the platform to its fullest. But if you’re interested in taking a peek under the hood, read on to hear about some of the cool stuff we’ve been working on!
Problem statement
High-performance service-to-service communication in Kubernetes has several challenges, especially when using persistent HTTP/2 connections, as we do at Databricks with gRPC.
How Kubernetes Routes Requests by Default
- The client resolves the service name (e.g., my-service.default.svc.cluster.local) via CoreDNS, which returns the service’s ClusterIP (a virtual IP).
- The client sends the request to the ClusterIP, assuming it's the destination.
- On the node, iptables, IPVS, or eBPF rules (configured by kube-proxy) intercept the packet. The kernel rewrites the destination IP to one of the backend Pod IPs based on basic load balancing, such as round-robin, and forwards the packet.
- The selected pod handles the request, and the response is sent back to the client.
While this model generally works, it quickly breaks down in performance-sensitive environments, leading to significant limitations.
Limitations
At Databricks, we operate hundreds of stateless services communicating over gRPC within each Kubernetes cluster. These services are often high-throughput, latency-sensitive, and run at significant scale.
The default load balancing model falls short in this environment for several reasons:
- High tail latency: gRPC uses HTTP/2, which maintains long-lived TCP connections between clients and services. Since Kubernetes load balancing happens at Layer 4, the backend pod is chosen only once per connection. This leads to traffic skew, where some pods receive significantly more load than others. As a result, tail latencies increase and performance becomes inconsistent under load.
- Inefficient resource usage: When traffic is not evenly spread, it becomes hard to predict capacity requirements. Some pods get CPU or memory starved while others sit idle. This leads to over-provisioning and waste.
- Limited load balancing strategies: kube-proxy supports only basic algorithms like round-robin or random selection. There's no support for strategies like:
- Weighted round robin
- Error-aware routing
- Zone-aware traffic routing
These limitations pushed us to rethink how we handle service-to-service communication within a Kubernetes cluster.
Our Approach: Client-Side Load Balancing with Real-Time Service Discovery
To address the limitations of kube-proxy and default service routing in Kubernetes, we built a proxyless, fully client-driven load balancing system backed by a custom service discovery control plane.
The fundamental requirement we had was to support load balancing at the application layer, and removing dependency on the DNS on a critical path. A Layer 4 load balancer, like kube-proxy, cannot make intelligent per-request decisions for Layer 7 protocols (such as gRPC) that utilize persistent connections. This architectural constraint creates bottlenecks, necessitating a more intelligent approach to traffic management.
The following table summarizes the key differences and the advantages of a client-side approach:
Table 1: Default Kubernetes LB vs. Databricks' Client-Side LB
| Feature/Aspect | Default Kubernetes Load Balancing (kube-proxy) | Databricks' Client-Side Load Balancing |
|---|---|---|
| Load Balancing Layer | Layer 4 (TCP/IP) | Layer 7 (Application/gRPC) |
| Decision Frequency | Once per TCP connection | Per-request |
| Service Discovery | CoreDNS + kube-proxy (virtual IP) | xDS-based Control Plane + Client Library |
| Supported Strategies | Basic (Round-robin, Random) | Advanced (P2C, Zone-affinity, Pluggable) |
| Tail Latency Impact | High (due to traffic skew on persistent connections) | Reduced (even distribution, dynamic routing) |
| Resource Utilization | Inefficient (over-provisioning) | Efficient (balanced load) |
| Dependency on DNS/Proxy | High | Minimal/Minimal, not on a critical path |
| Operational Control | Limited | Fine-grained |
This system enables intelligent, up-to-date request routing with minimal dependency on DNS or Layer 4 networking. It gives clients the ability to make informed decisions based on live topology and health data.
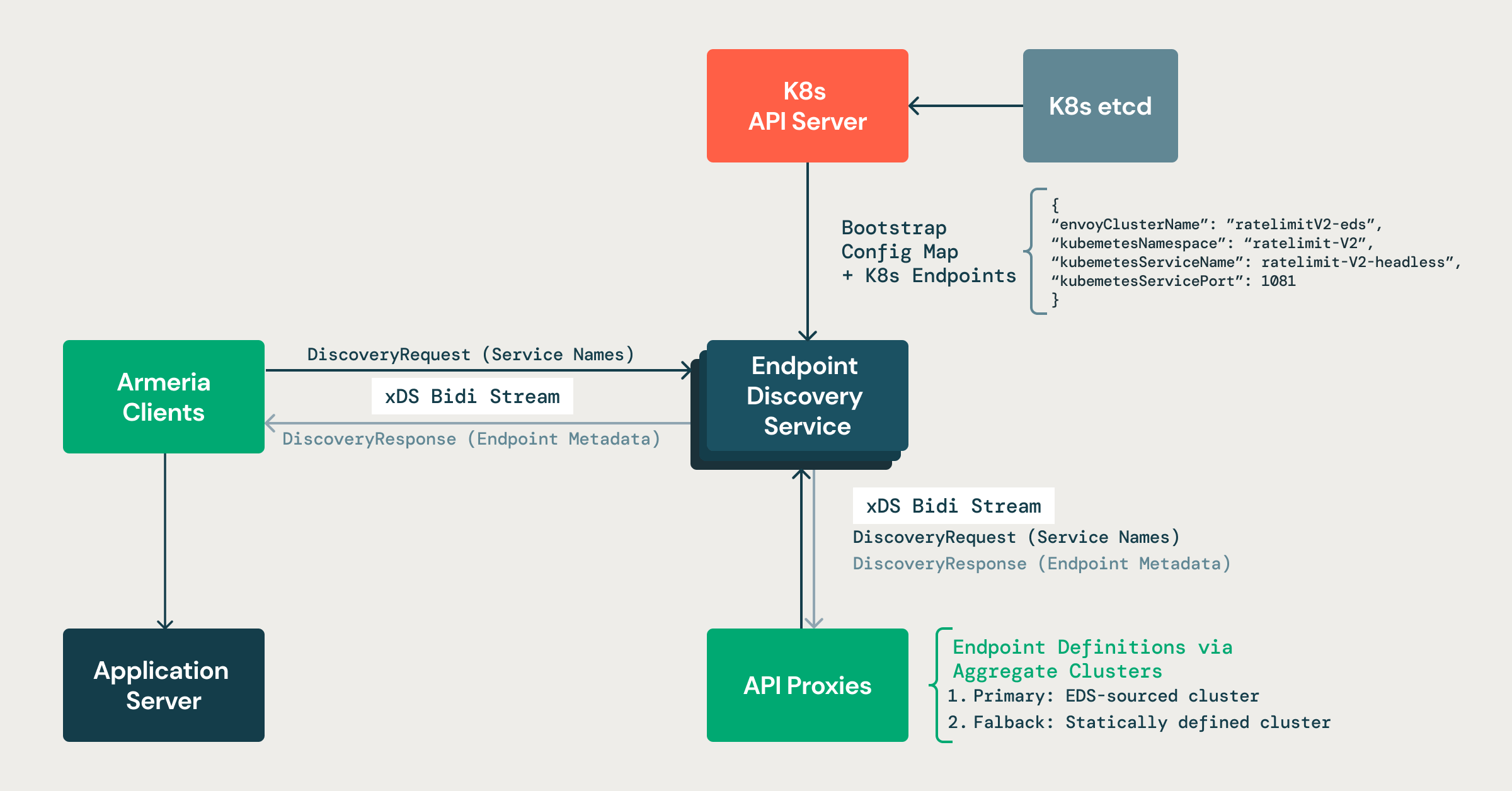
The figure shows our custom Endpoint Discovery Service in action. It reads service and endpoint data from the Kubernetes API and translates it into xDS responses. Both Armeria clients and API proxies stream requests to it and receive live endpoint metadata, which is then used by application servers for intelligent routing with fallback clusters as backup.”
Custom Control Plane (Endpoint discovery service)
We run a lightweight control plane that continuously monitors the Kubernetes API for changes to Services and EndpointSlices. It maintains an up-to-date view of all backend pods for every service, including metadata like zone, readiness, and shard labels.
RPC Client Integration
A strategic advantage for Databricks was the widespread adoption of a common framework for service communication across most of its internal services, which are predominantly written in Scala. This shared foundation allowed us to embed client-side service discovery and load balancing logic directly into the framework, making it easy to adopt across teams without requiring custom implementation effort.
Each service integrates with our custom client, which subscribes to updates from the control plane for the services it depends on during the connection setup. The client maintains a dynamic list of healthy endpoints, including metadata like zone or shard, and updates automatically as the control plane pushes changes.
Because the client bypasses both DNS resolution and kube-proxy entirely, it always has a live, accurate view of service topology. This allows us to implement consistent and efficient load balancing strategies across all internal services.
Advanced Load Balancing in Clients
The rpc client performs request-aware load balancing using strategies like:
- Power of Two Choices (P2C): For the majority of services, a simple Power of Two Choices (P2C) algorithm has proven remarkably effective. This strategy involves randomly selecting two backend servers and then choosing the one with fewer active connections or lower load. Databricks' experience indicates that P2C strikes a strong balance between performance and implementation simplicity, consistently leading to uniform traffic distribution across endpoints.
- Zone-affinity-based: The system also supports more advanced strategies, such as zone-affinity-based routing. This capability is vital for minimizing cross-zone network hops, which can significantly reduce network latency and associated data transfer costs, especially in geographically distributed Kubernetes clusters.
The system also accounts for scenarios where a zone lacks sufficient capacity or becomes overloaded. In such cases, the routing algorithm intelligently spills traffic over to other healthy zones, balancing load while still preferring local affinity whenever possible. This ensures high availability and consistent performance, even under uneven capacity distribution across zones. - Pluggable Support: The architecture's flexibility allows for pluggable support for additional load balancing strategies as needed.
More advanced strategies, like zone-aware routing, required careful tuning and deeper context about service topology, traffic patterns, and failure modes; a topic to explore in a dedicated follow-up post.
To ensure the effectiveness of our approach, we ran extensive simulations, experiments, and real-world metric analysis. We validated that load remained evenly distributed and that key metrics like tail latency, error rate, and cross-zone traffic cost stayed within target thresholds. The flexibility to adapt strategies per-service has been valuable, but in practice, keeping it simple (and consistent) has worked best.
xDS Integration with Envoy
Our control plane extends its utility beyond the internal service-to-service communication. It plays a crucial role in managing external traffic by speaking the xDS API to Envoy, the discovery protocol that lets clients fetch up-to-date configuration (like clusters, endpoints, and routing rules) dynamically. Specifically, it implements Endpoint Discovery Service (EDS) to provide Envoy with consistent and up-to-date metadata about backend endpoints by programming ClusterLoadAssignment resources. This ensures that gateway-level routing (e.g., for ingress or public-facing traffic) aligns with the same source of truth used by internal clients.
Summary
This architecture gives us fine-grained control over routing behavior while decoupling service discovery from the limitations of DNS and kube-proxy. The key takeaways are:
- clients always have a live, accurate view of endpoints and their health,
- load balancing strategies can be tailored per-service, improving efficiency and tail latency, and
- both internal and external traffic share the same source of truth, ensuring consistency across the platform.
Impact
After deploying our client-side load balancing system, we observed significant improvements across both performance and efficiency:
- Uniform Request Distribution
Server-side QPS became evenly distributed across all backend pods. Unlike the prior setup, where some pods were overloaded while others remained underutilized, traffic now spreads predictably. The top chart shows the distribution before EDS, while the bottom chart shows the balanced distribution after EDS.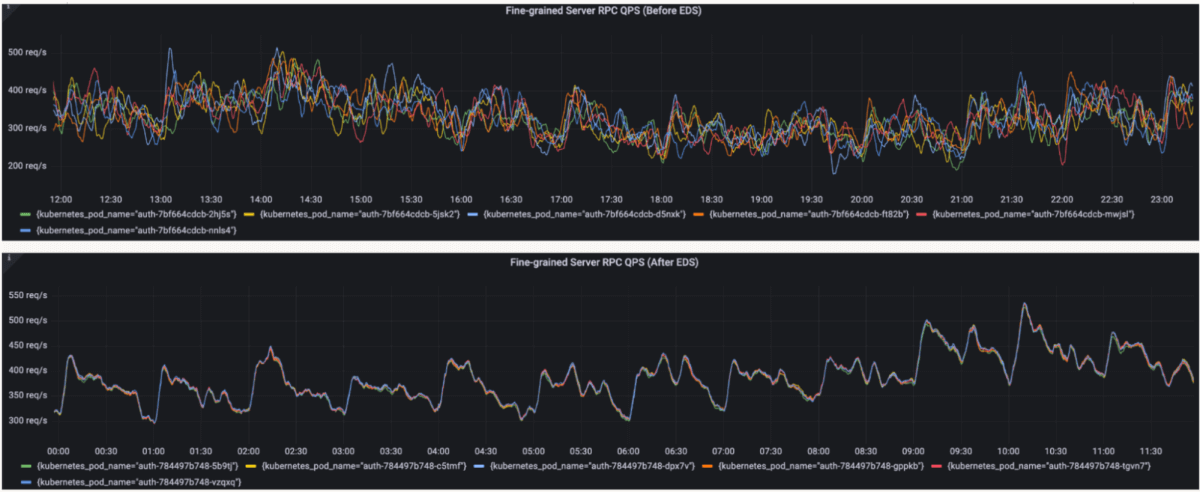
- Stable Latency Profiles
The variation in latency across pods dropped noticeably. Latency metrics improved and stabilized across pods, reducing long-tail behavior in gRPC workloads. The diagram below shows how P90 latency became more stable after client-side load balancing was enabled.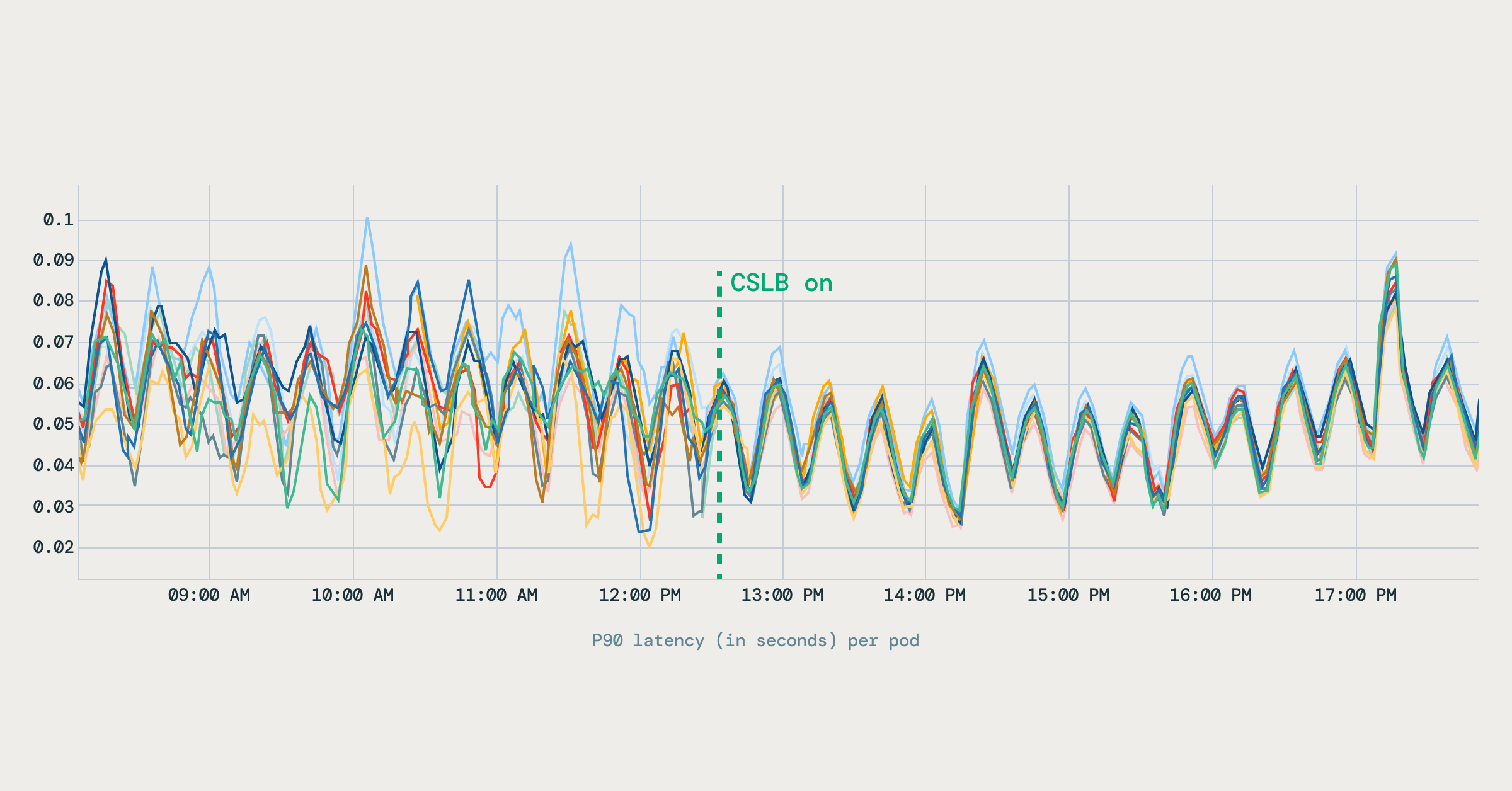
- Resource Efficiency
With more predictable latency and balanced load, we were able to reduce over-provisioned capacity. Across several services, this resulted in approximately a 20% reduction in pod count, freeing up compute resources without compromising reliability.
Challenges and Lessons Learned
While the rollout delivered clear benefits, we also uncovered several challenges and insights along the way:
- Server cold starts: Before client-side load balancing, most requests were sent over long-lived connections, so new pods were rarely hit until existing connections were recycled. After the shift, new pods began receiving traffic immediately, which surfaced cold-start issues where they handled requests before being fully warmed up. We addressed this by introducing slow-start ramp-up and biasing traffic away from pods with higher observed error rates. These lessons also reinforced the need for a dedicated warmup framework.
- Metrics-based routing: We initially experimented with skewing traffic based on resource usage signals such as CPU. Although conceptually attractive, this approach proved unreliable: monitoring systems had different SLOs than serving workloads, and metrics like CPU were often trailing indicators rather than real-time signals of capacity. We ultimately moved away from this model and chose to rely on more dependable signals such as server health.
- Client-library integration: Building load balancing directly into client libraries brought strong performance benefits, but it also created some unavoidable gaps. Languages without the library, or traffic flows that still depend on infrastructure load balancers, remain outside the scope of client-side balancing.
Alternatives Considered
While developing our client-side load balancing approach, we evaluated other alternative solutions. Here’s why we ultimately decided against these:
Headless Services
Kubernetes headless services (clusterIP: None) provide direct pod IPs via DNS, allowing clients and proxies (like Envoy) to perform their own load balancing. This approach bypasses the limitation of connection-based distribution in kube-proxy and enables advanced load balancing strategies offered by Envoy (such as round robin, consistent hashing, and least-loaded round robin).
In theory, switching existing ClusterIP services to headless services (or creating additional headless services using the same selector) would mitigate connection reuse issues by providing clients direct endpoint visibility. However, this approach comes with practical limitations:
- Lack of Endpoint Weights: Headless services alone don't support assigning weights to endpoints, restricting our ability to implement fine-grained load distribution control.
- DNS Caching and Staleness: Clients frequently cache DNS responses, causing them to send requests to stale or unhealthy endpoints.
- No Support for Metadata: DNS records do not carry any additional metadata about the endpoints (e.g., zone, region, shard). This makes it difficult or impossible to implement strategies like zone-aware or topology-aware routing.
Although headless services can offer a temporary improvement over ClusterIP services, the practical challenges and limitations made them unsuitable as a long-term solution at Databricks' scale.
Service Meshes (e.g., Istio)
Istio provides powerful Layer 7 load balancing features using Envoy sidecars injected into every pod. These proxies handle routing, retries, circuit breaking, and more - all managed centrally through a control plane.
While this model offers many capabilities, we found it unsuitable for our environment at Databricks for a few reasons:
- Operational complexity: Managing thousands of sidecars and control plane components adds significant overhead, particularly during upgrades and large-scale rollouts.
- Performance overhead: Sidecars introduce additional CPU, memory, and latency costs per pod — which becomes substantial at our scale.
- Limited client flexibility: Since all routing logic is handled externally, it’s difficult to implement request-aware strategies that rely on application-layer context.
We also evaluated Istio’s Ambient Mesh. Since Databricks already had proprietary systems for functions like certificate distribution, and our routing patterns were relatively static, the added complexity of adopting a full mesh outweighed the benefits. This was especially true for a small infra team supporting a predominantly Scala codebase.
It is worth noting that one of the biggest advantages of sidecar-based meshes is language-agnosticism: teams can standardize resiliency and routing across polyglot services without maintaining client libraries everywhere. At Databricks, however, our environment is heavily Scala-based, and our monorepo plus fast CI/CD culture make the proxyless, client-library approach far more practical. Rather than introducing the operational burden of sidecars, we invested in building first-class load balancing directly into our libraries and infrastructure components.
Future directions and Areas of exploration
Our current client-side load balancing approach has significantly improved internal service-to-service communication. Yet, as Databricks continues to scale, we’re exploring several advanced areas to further enhance our system:
Cross-Cluster and Cross-Region Load Balancing: As we manage thousands of Kubernetes clusters across multiple regions, extending intelligent load balancing beyond individual clusters is critical. We are exploring technologies like flat L3 networking and service-mesh solutions, integrating seamlessly with multi-region Endpoint Discovery Service (EDS) clusters. This will enable robust cross-cluster traffic management, fault tolerance, and globally efficient resource utilization.
Advanced Load Balancing Strategies for AI Use Cases: We plan to introduce more sophisticated strategies, such as weighted load balancing, to better support advanced AI workloads. These strategies will enable finer-grained resource allocation and intelligent routing decisions based on specific application characteristics, ultimately optimizing performance, resource consumption, and cost efficiency.
If you're interested in working on large-scale distributed infrastructure challenges like this, we're hiring. Come build with us — explore open roles at Databricks!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.