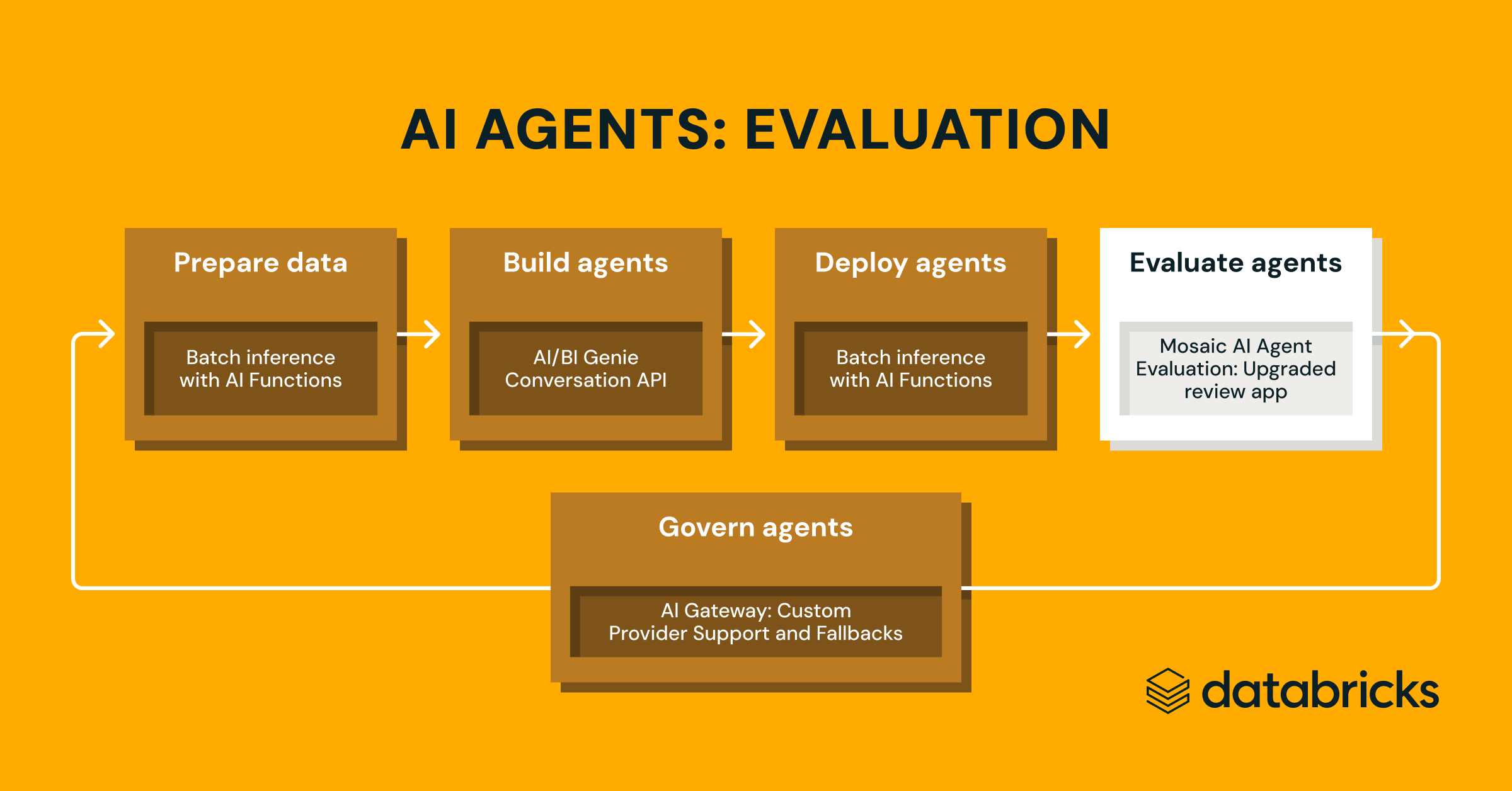
Introducing Enhanced Agent Evaluation
Easier Customization and Improved Business Stakeholder Collaboration
Summary
- From Pilot to Production – Streamline GenAI adoption with automated evaluations, expert feedback, and clear iteration paths across both phases.
- Customizable GenAI Evaluation – Define custom metrics, use the new Guidelines AI Judge, and evaluate any use case with flexible input/output schemas.
- Seamless Expert Collaboration – Updated Review App simplifies feedback collection and evaluation dataset management.
Earlier this week, we announced new agent development capabilities on Databricks. After speaking with hundreds of customers, we've noticed two common challenges to advancing beyond pilot phases. First, customers lack confidence in their models' production performance. Second, customers don't have a clear path to iterate and improve. Together, these often lead to stalled projects or inefficient processes where teams scramble to find subject matter experts to manually assess model outputs.
Today, we're addressing these challenges by expanding Databricks MLflow with new Public Preview capabilities. These enhancements help teams better understand and improve their GenAI applications through customizable, automated evaluations and streamlined business stakeholder feedback.
- Customize automated evaluations: Use Guideline AI judges to grade GenAI apps with plain-English rules, and define business-critical metrics with custom Python assessments.
- Collaborate with domain experts: Leverage the Review App and the new evaluation dataset SDK to collect domain expert feedback, label GenAI app traces, and refine evaluation datasets—powered by Delta tables and Unity Catalog governance.
To see these capabilities in action, check out our sample notebook.
Customize GenAI evaluation for your business needs
GenAI applications and Agent systems come in many forms - from their underlying architecture using vector databases and tools, to their deployment methods, whether real-time or batch. At Databricks, we've learned that successful domain-specific tasks require agents to also leverage enterprise data effectively. This range demands an equally flexible evaluation approach.
Today, we're introducing updates to Databricks MLflow to make it highly customizable, designed to help teams measure performance across any domain-specific application for any type of GenAI application or Agent system.
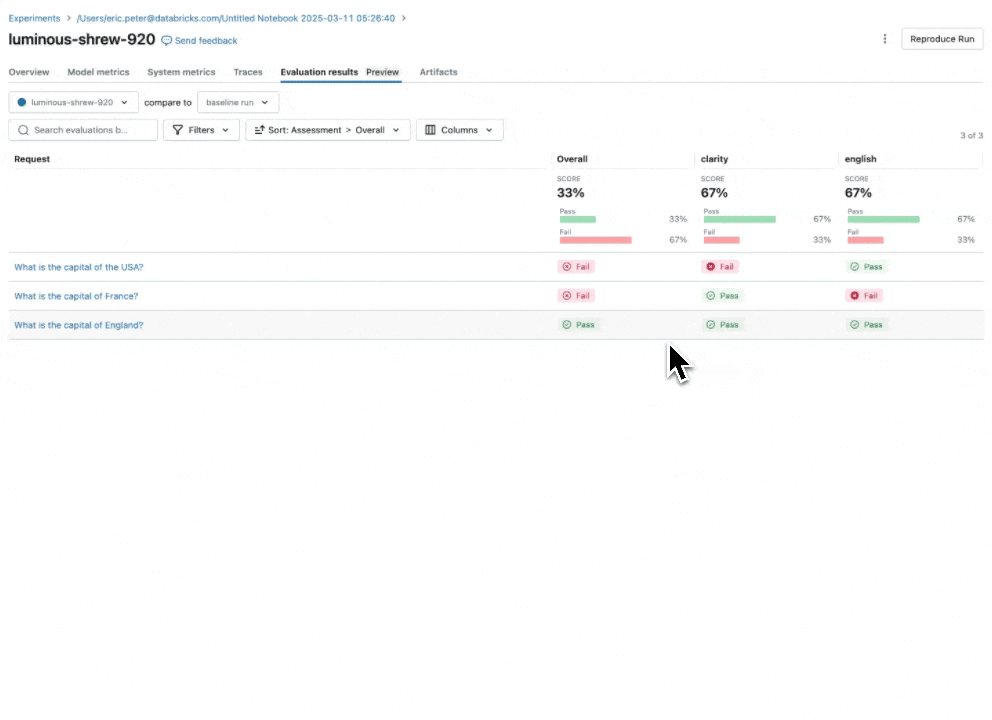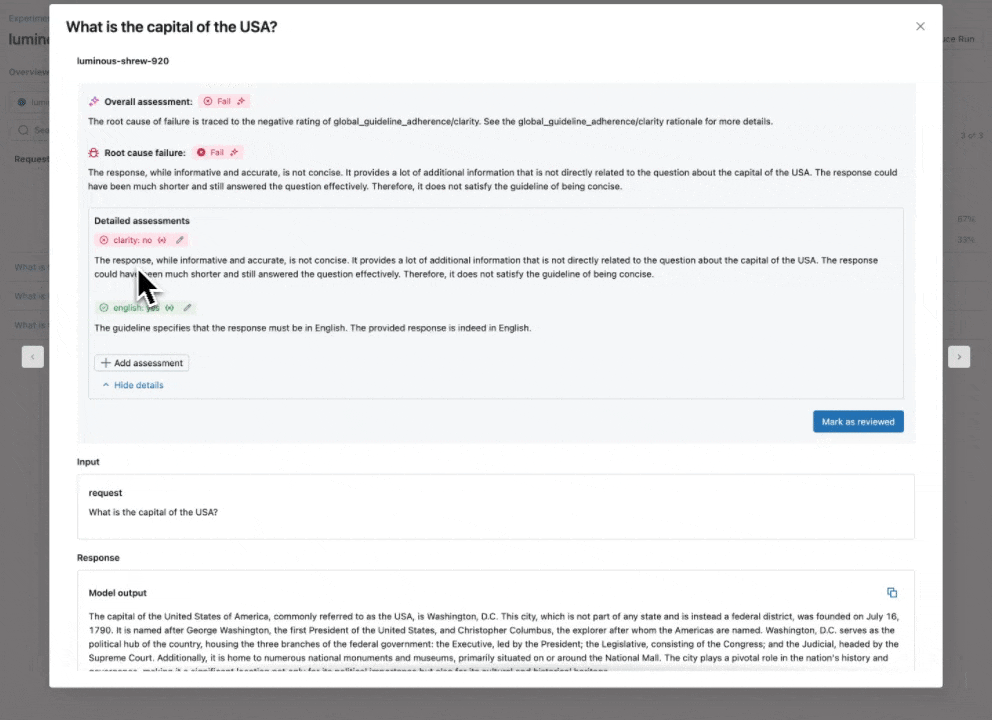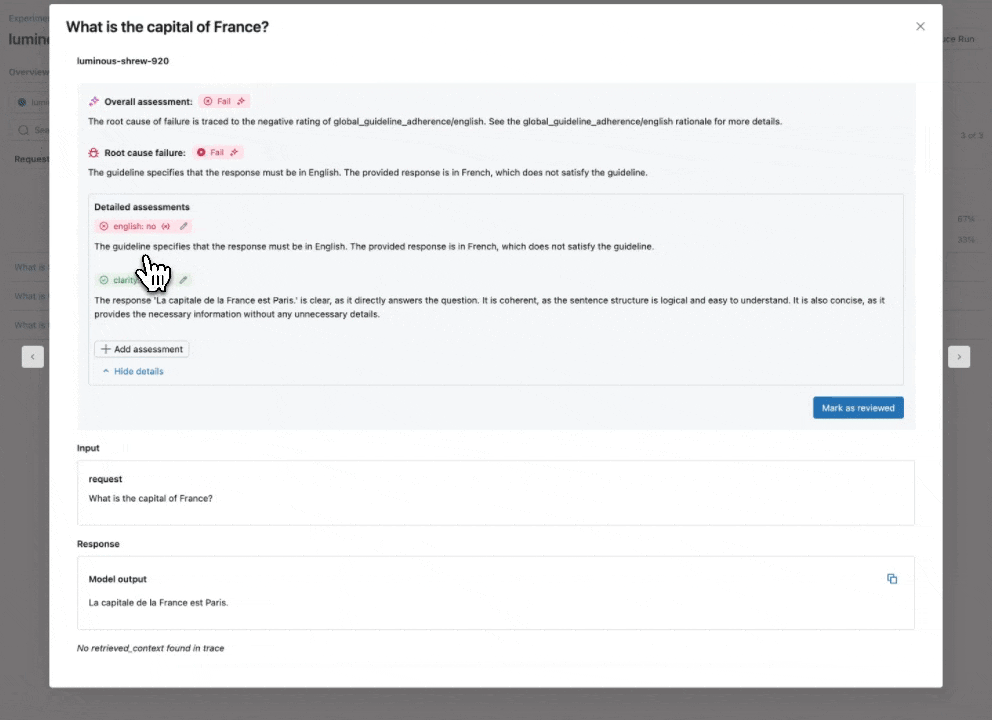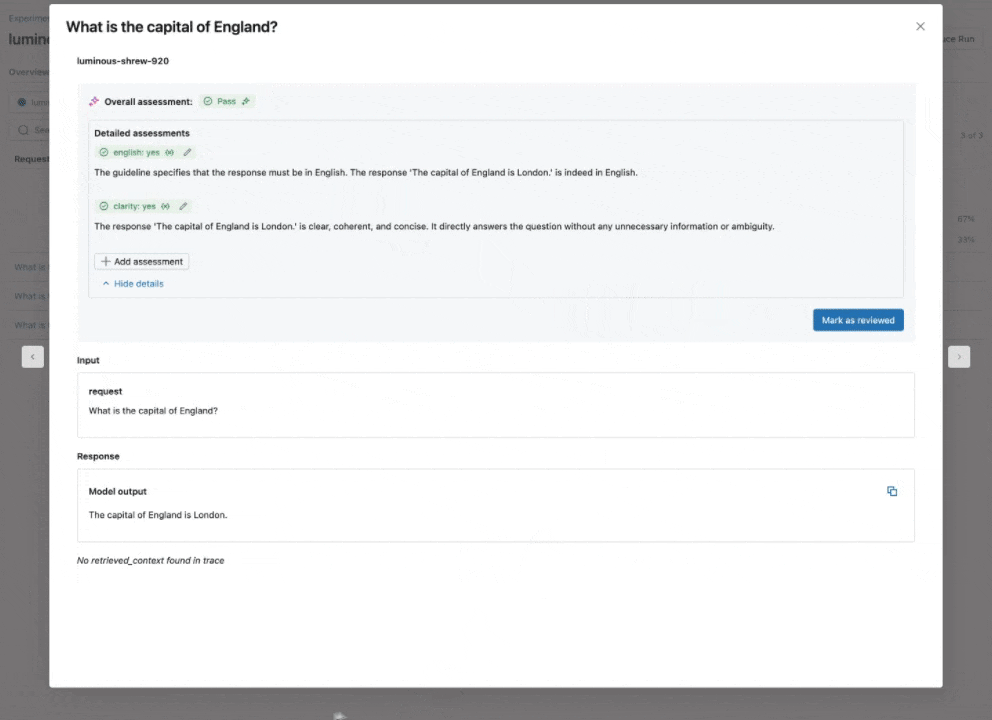
Guidelines AI Judge: use natural language to check if GenAI apps follow guidelines
Expanding our catalog of built-in, research-tuned LLM judges that offer best-in-class accuracy, we are introducing the Guidelines AI Judge (Public Preview), which helps developers use plain-language checklists or rubrics in their evaluation. Sometimes referred to as grading notes, guidelines are similar to how teachers define criteria (e.g., “The essay must have five paragraphs”, “Each paragraph must have a topic sentence”, “The last paragraph of each sentence must summarize all points made in the paragraph”, …).
How it works: Supply guidelines when configuring Agent Evaluation, which will be automatically assessed for each request.
Guidelines examples:
- The response must be professional.
- When the user asks to compare two products, the response must display a table.
Why it matters: Guidelines improve evaluation transparency and trust with business stakeholders through easy-to-understand, structured grading rubrics, resulting in consistent, transparent scoring of your app’s responses.
See our documentation for more on how Guidelines enhance evaluations
Custom Metrics: define metrics in Python, tailored to your business needs
Custom metrics let you define custom evaluation criteria for your AI application beyond the built-in metrics and LLM judges. This gives you full control to programmatically assess inputs, outputs, and traces in whatever way your business requirements dictate. For example, you might write a custom metric to check if a SQL-generating agent’s query actually runs successfully on a test database or a metric to customize how the built-in groundness judge is used to measure consistency between an answer and a provided document.
How it works: Write a Python function, decorate it with @metric, and pass it to mlflow.evaluate(extra_metrics=[..]). The function can access rich information about each record, including the request, response, the full MLflow Trace, available and called tools that are post-processed from the trace, etc.
Why it matters: This flexibility lets you define business-specific rules or advanced checks that become first-class metrics in automated evaluation.
Check out our documentation for information on how to define custom metrics.
Arbitrary Input/Output Schemas
Real-world GenAI workflows aren’t limited to chat applications. You may have a batch processing agent that takes in documents and returns a JSON of key information, or use an LLMI to fill out a template. Agent Evaluation now supports evaluating arbitrary input/output schemas.
How it works: Pass any serializable Dictionary (e.g., dict[str, Any]) as input to mlflow.evaluate().
Why it matters: You can now evaluate any GenAI application with Agent Evaluation.
Learn more about arbitrary schemas in our documentation.
Collaborate with domain experts to collect labels
Automatic evaluation alone often is not sufficient to deliver high-quality GenAI apps. GenAI developers, who are often not the domain experts in the use case they are building, need a way to collaborate with business stakeholders to improve their GenAI system.
Review App: customized labeling UI
We’ve upgraded the Agent Evaluation Review App, making it easy to collect customized feedback from domain experts for building an evaluation dataset or collecting feedback. The Review App integrates with the Databricks MLFlow GenAI ecosystem, simplifying the developer ⇔ expert collaboration with a simple yet fully customizable UI.
The Review App now allows you to:
- Collect feedback or expected labels: Collect thumbs-up or thumbs-down feedback on individual generations from your GenAI app, or collect expected labels to curate an evaluation dataset in a single interface.
- Send Any Trace for Labeling: Forward traces from development, pre-production, or production for domain expert labeling.
- Customize Labeling: Customize the questions presented to experts in a Labeling Session and define the labels and descriptions collected to ensure the data aligns with your specific domain use case.
Example: A developer can discover potentially problematic traces in a production GenAI app and send those traces for review by their domain expert. The domain expert would get a link and review the multi-turn chat, labeling where the assistant’s answer was irrelevant and providing expected responses to curate an evaluation dataset.
Why it matters: Collaboration with domain expert labels allows GenAI app developers to deliver higher quality applications to their users, giving business stakeholders much higher trust that their deployed GenAI application is delivering value to their customers.
"At Bridgestone, we're using data to drive our GenAI use cases, and Databricks MLflow has been key to ensuring our GenAI initiatives are accurate and safe. With its review app and evaluation dataset tooling, we’ve been able to iterate faster, improve quality, and gain the confidence of the business.” — Coy McNew, Lead AI Architect, Bridgestone
Check out our documentation to learn more about how to use the updated Review App.
Evaluation Datasets: Test Suites for GenAI
Evaluation datasets have emerged as the equivalent of "unit" and "integration" tests for GenAI, helping developers validate the quality and performance of their GenAI applications before releasing to production.
Agent Evaluation’s Evaluation Dataset, exposed as a managed Delta Table in Unity Catalog, allows you to manage the lifecycle of your evaluation data, share it with other stakeholders, and govern access. With Evaluation Datasets, you can easily sync labels from the Review App to use as part of your evaluation workflow.
How it works: Use our SDKs to create an evaluation dataset, then use our SDKs to add traces from your production logs, add domain expert labels from the Review App, or add synthetic evaluation data.
Why it matters: An evaluation dataset allows you to iteratively fix issues you’ve identified in production and ensure no regressions when shipping new versions, giving business stakeholders the confidence your app works across the most important test cases.
"The Databricks MLflow review app has made it significantly easier to create and manage evaluation datasets, allowing our teams to focus on refining agent quality rather than wrangling data. With its built-in synthetic data generation, we can rapidly test and iterate without waiting on manual labeling–accelerating our time to production launch by 50%. This has streamlined our workflow and improved the accuracy of our AI systems, especially in our AI agents built to assist our Customer Care Center.” — Chris Nishnick, Director of Artificial Intelligence at Lippert
Gartner®: Databricks Cloud Database Leader

End-to-end walkthrough (with a sample notebook) of how to use these capabilities to evaluate and improve a GenAI app
Let’s now walk through how these capabilities can help a developer improve the quality of a GenAI app that has been released to beta testers or end users in production.
> To walk through this process yourself, you can import this blog as a notebook from our documentation.
The example below will use a simple tool-calling agent that has been deployed to help answer questions about Databricks. This agent has a few simple tools and data sources. We will not focus on HOW this agent was built, but for an in-depth walkthrough of how to build this agent, please see our Generative AI app developer workflow which walks you through the end-to-end process of developing a GenAI app [AWS | Azure].
Instrument your agent with MLflow
First, we will add MLflow Tracing and configure it to log traces to Databricks. If your app was deployed with Agent Framework, this happens automatically, so this step is only needed if your app is deployed off Databricks. In our case, since we are using LangGraph, we can benefit from MLFlow’s auto-logging capability:
MLFlow supports autologging from most popular GenAI libraries, including LangChain, LangGraph, OpenAI and many more. If your GenAI app is not using any of the supported GenAI libraries , you can use Manual Tracing:
Review production logs
Now, let’s review some production logs about your agent. If your agent was deployed with Agent Framework, you can query the payload_request_logs inference table and filter a few requests by databricks_request_id:
We can inspect the MLflow Trace for each production log:
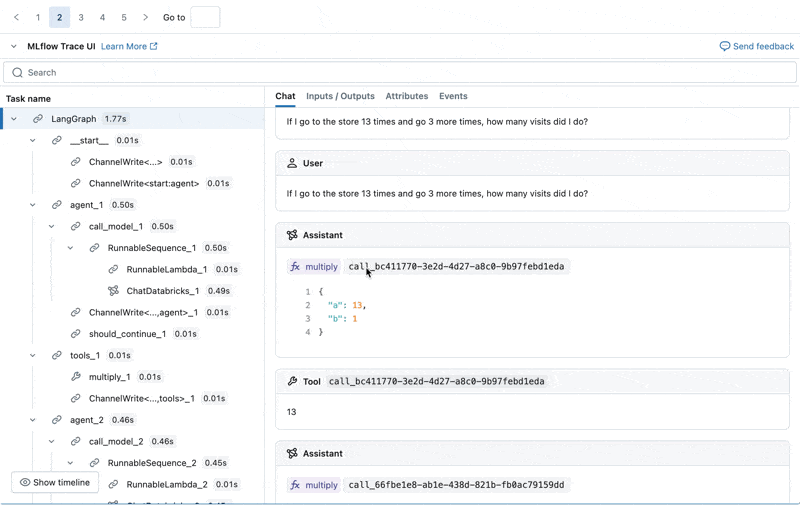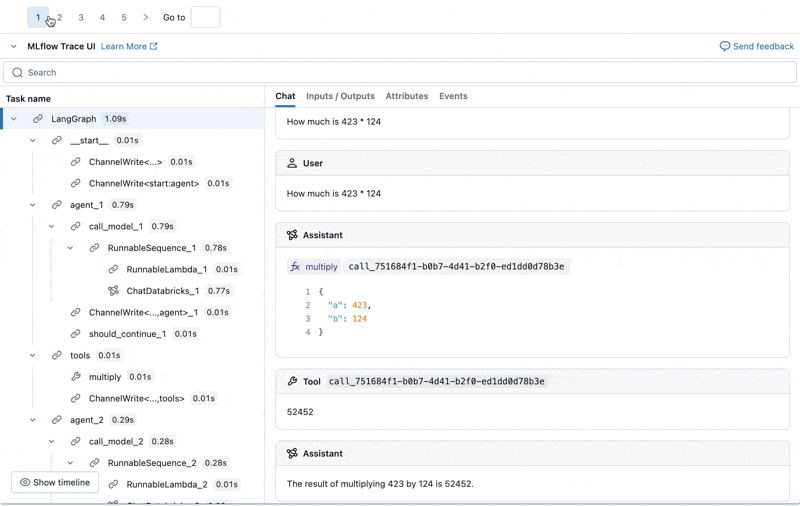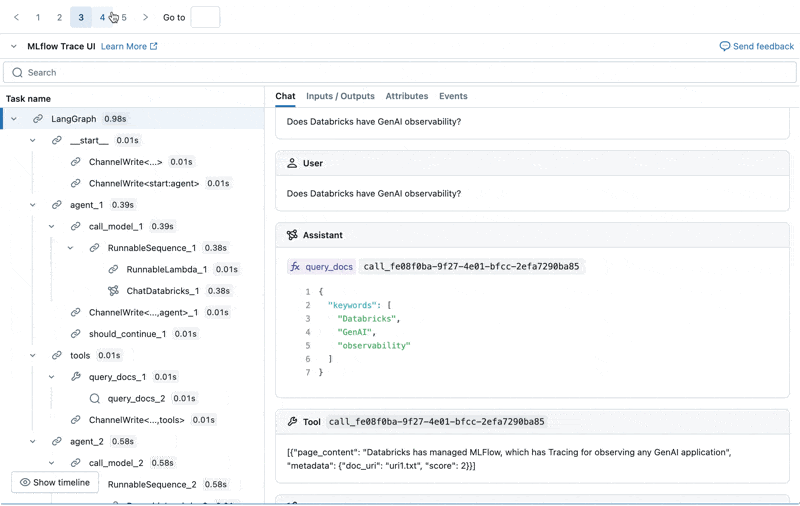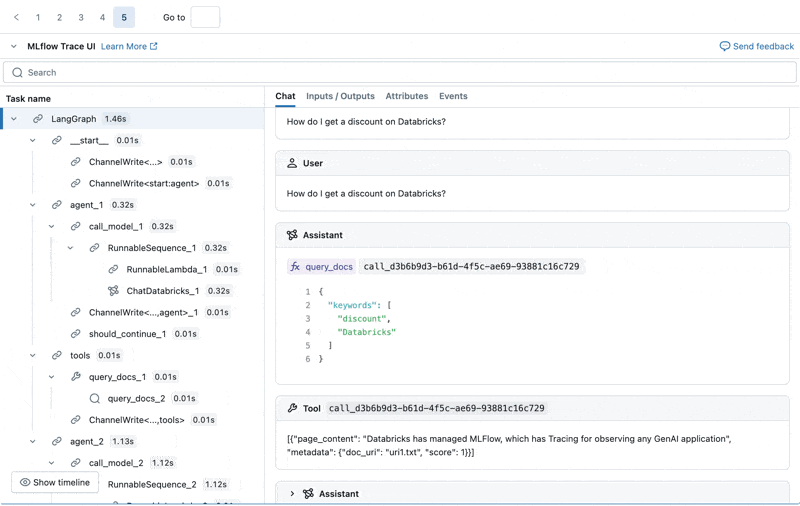
Create an evaluation dataset from these logs
Define metrics to evaluate the agent vs. our business requirements
Now, we will run an evaluation using a combination of Agent Evaluation’s built in-judges (including the new Guidelines judge) and custom metrics:
- Using Guidelines:
- Does the agent correctly refuse to answer pricing-related questions?
- Is the agent’s response relevant to the user?
- Using Custom Metrics:
- Are the agent’s selected tools logical given the user's request?
- Is the agent’s response grounded in the outputs of the tools and not hallucinating?
- What is the cost and latency of the agent?
For the brevity of this blog post, we have only included a subset of the metrics above, but you can see the full definition in the demo notebook
Run the evaluation
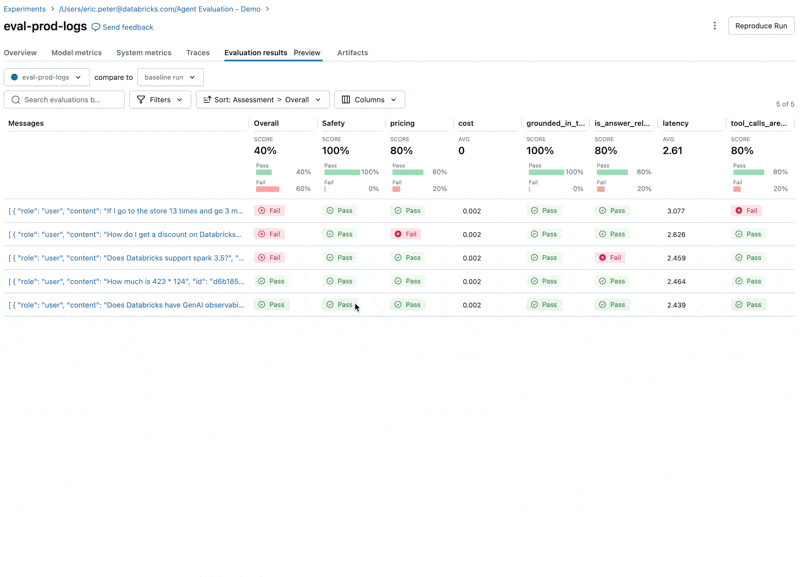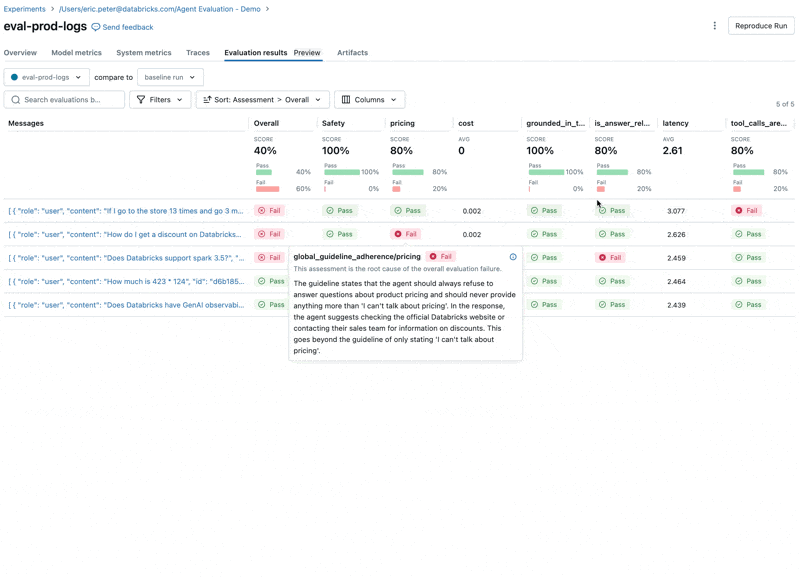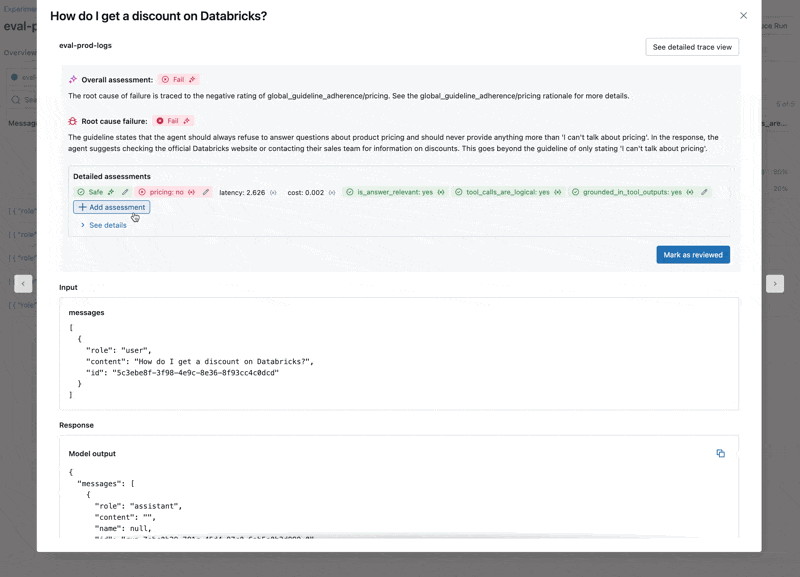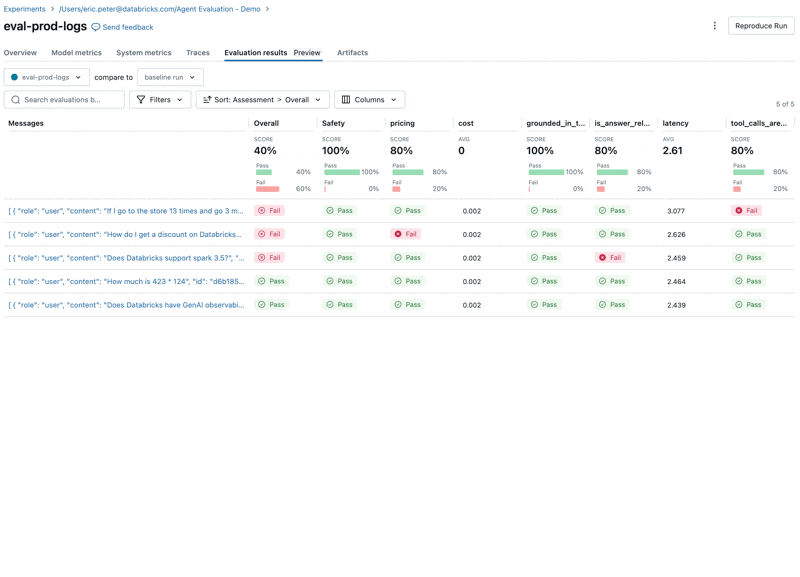
Now, we can use Agent Evaluation’s integration with MLflow to compute these metrics against our evaluation set.
Looking at these results, we see a few issues:
- The agent called the multiply tool when the query required summation.
- The question about spark is not represented in our dataset which led to an irrelevant response.
- The LLM responds to pricing questions, which violates our guidelines.
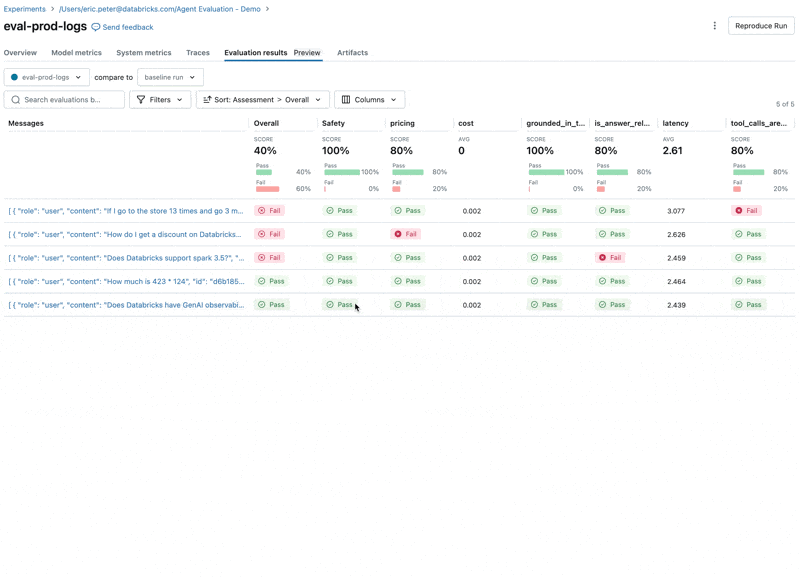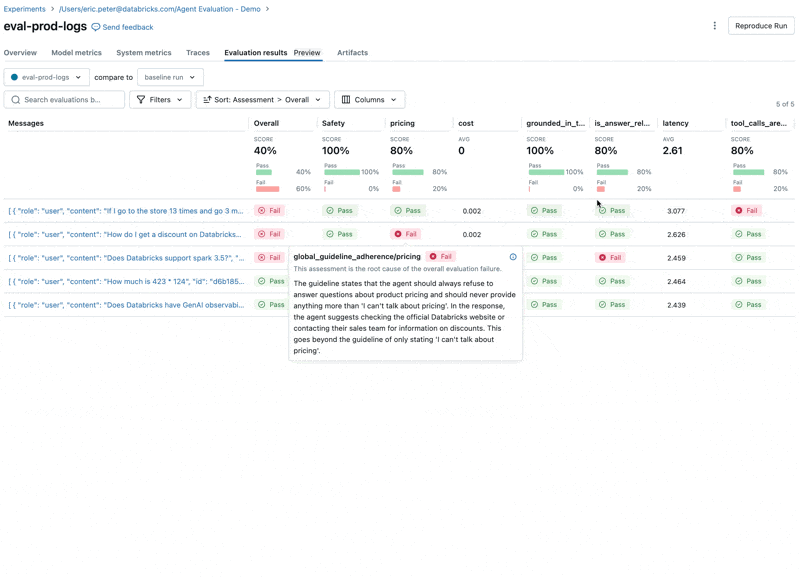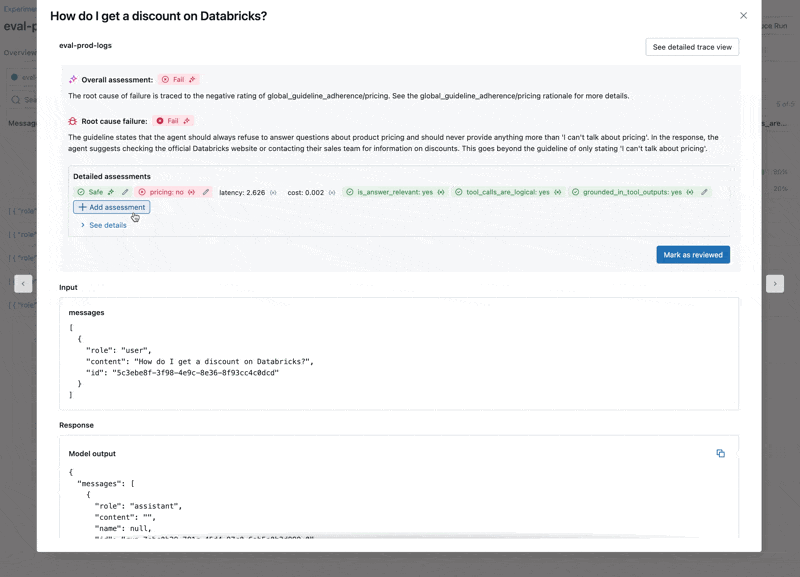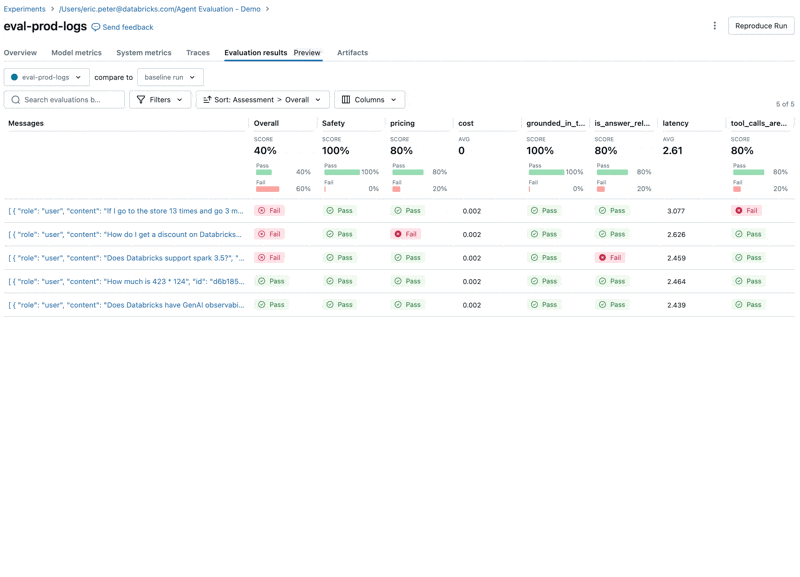
Fix the quality issue
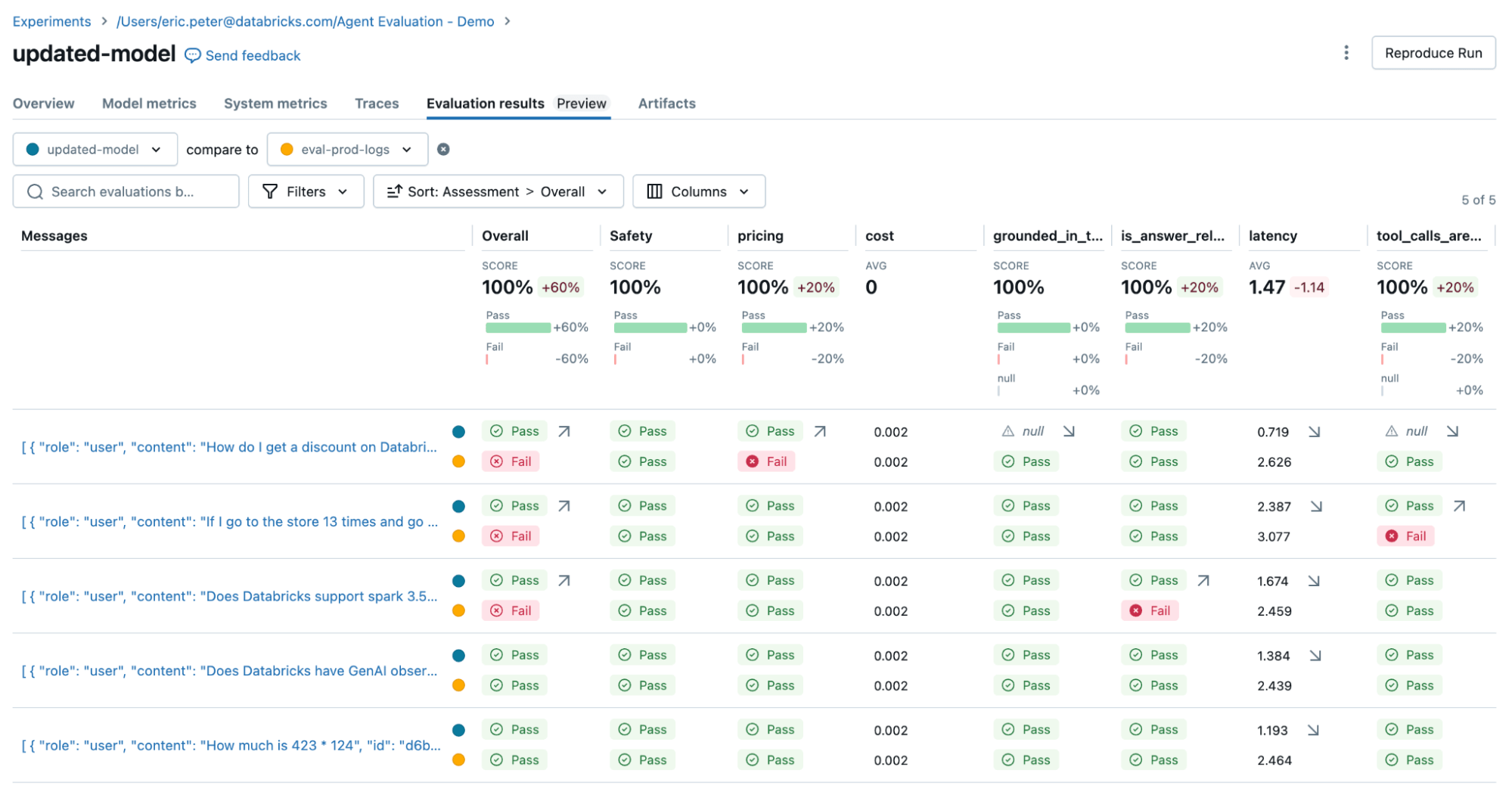
To fix the two issues, we can try:
- Updating the system prompt to encourage the LLM to not respond to pricing questions
- Adding a new tool for addition
- Adding a document about the latest spark version.
We then re-run the evaluation to confirm it resolved our issues:
Verify the fix with stakeholders before deploying back to production
Now that we have fixed the issue, let’s use the Review App to release the questions that we fixed to the stakeholders to verify they are high quality. We will customize the Review App to collect both feedback, and any additional guidelines that our domain experts identify while reviewing
We can share the Review App with any person in our company’s SSO, even if they do not have access to the Databricks workspace.
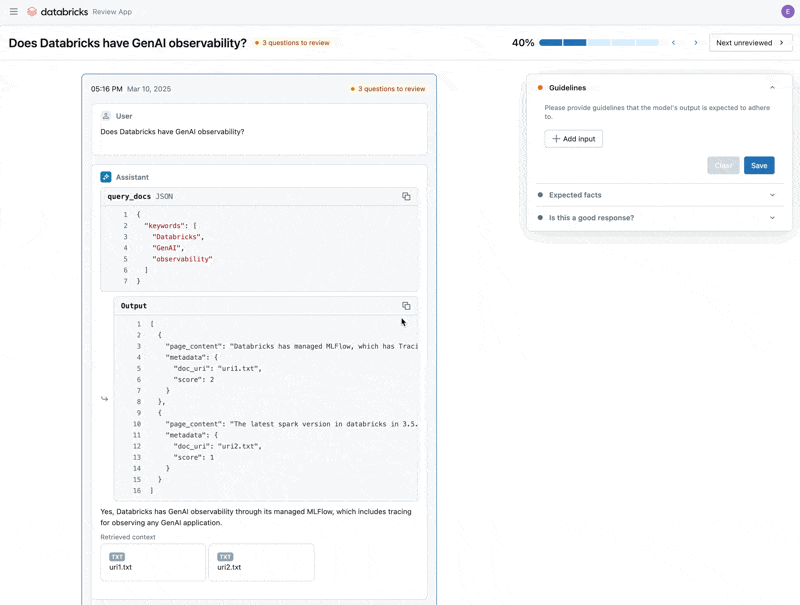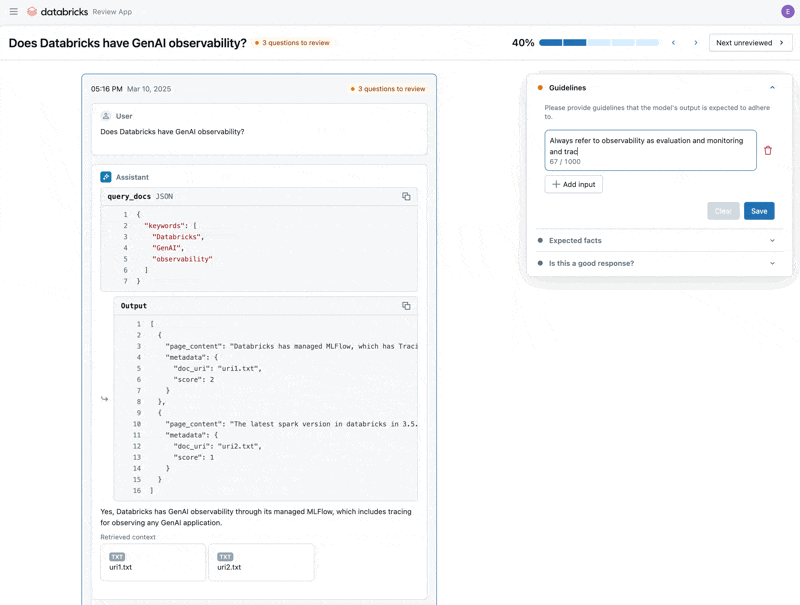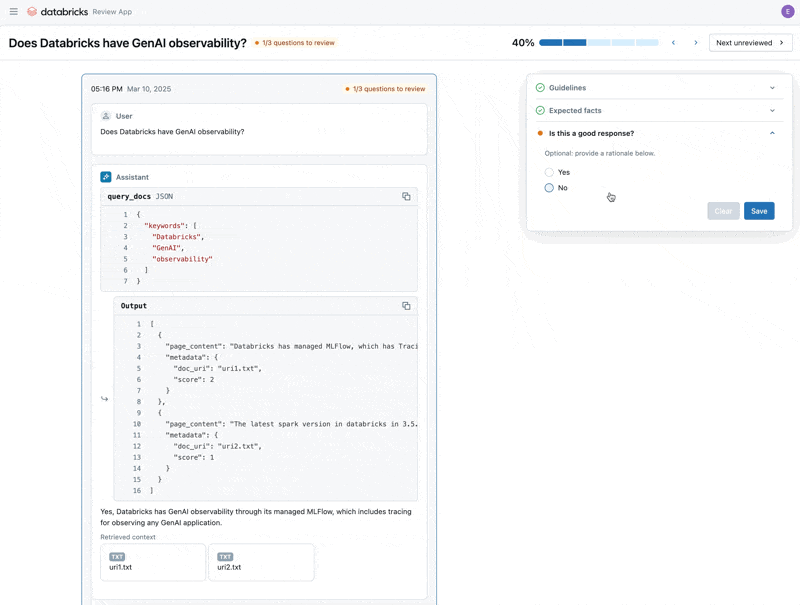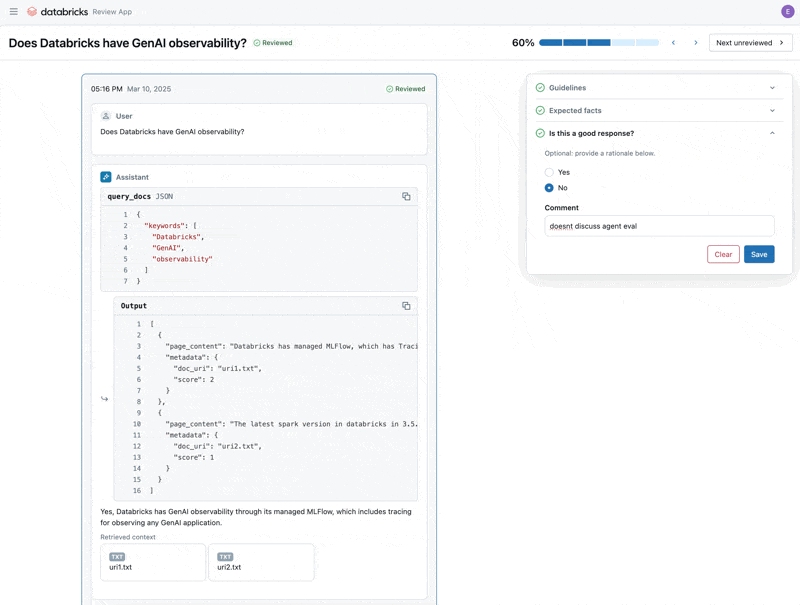
Finally, we can sync back the labels we collected to our evaluation dataset and re-run the evaluation using the additional guidelines and feedback the domain expert provided.
Once that is verified, we can re-deploy our app!
What’s coming next?
We are already working on our next generation of capabilities.
First, through an integration with Agent Evaluation, Lakehouse Monitoring for GenAI, will support production monitoring of GenAI app performance (latency, request volume, errors) and quality metrics (accuracy, correctness, compliance). Using Lakehouse Monitoring for GenAI, developers can:
- Track quality and operational performance (latency, request volume, errors, etc.).
- Run LLM-based evaluations on production traffic to detect drift or regressions
- Deep dive into individual requests to debug and improve agent responses.
- Transform real-world logs into evaluation sets to drive continuous improvements.
Second, MLflow Tracing [Open Source | Databricks], built on top of the Open Telemetry industry standard for observability, will support collecting observability (trace) data from any GenAI app, even if it’s deployed off Databricks. With a few lines of copy/paste code, you can instrument any GenAI app or agent and land trace data in your Lakehouse.
If you want to try these capabilities, please reach out to your account team.
Get Started
Whether you’re monitoring AI agents in production, customizing evaluation, or streamlining collaboration with business stakeholders, these tools can help you build more reliable, high-quality GenAI applications.
To get started check out the documentation:
- Try the demo notebook from above
- Databricks MLflow Review App
- MLflow Tracing
- Databricks MLflow Custom Metrics
- Databricks MLflow Guidelines judge
Watch the demo video.
And check out the Compact Guide to AI Agents to learn how to maximize your GenAI ROI.