Introducing Serverless Batch Inference
Effortless, Scalable LLM Batch Inference with AI Functions
by Ankit Mathur, Ahmed Bilal and Youngbin Kim
- Instant, Serverless AI – Zero setup, 10x faster batch inference.
- Structured & Scalable Workflows – Extract insights, run at scale, built-in observability.
- Seamless Databricks Integration – Works across SQL, Python, and AI/BI tools.
Generative AI is transforming how organizations interact with their data, and batch LLM processing has quickly become one of Databricks' most popular use cases. Last year, we launched the first version of AI Functions to enable enterprises to apply LLMs to private data—without data movement or governance trade-offs. Since then, thousands of organizations have powered batch pipelines for classification, summarization, structured extraction, and agent-driven workflows. As generative AI workloads move into production, speed, scalability, and simplicity have become essential.
That’s why, as part of our Week of Agents initiative, we’ve rolled out major updates to AI Functions, enabling them to power production-grade batch workflows on enterprise data. AI functions—whether general-purpose (ai_query() for flexible prompts) or task-specific (ai_classify(), ai_translate())— are now fully serverless and production-grade, requiring zero configuration and delivering over 10x faster performance. Additionally, they’re now deeply integrated into the Databricks Data Intelligence Platform and accessible directly from notebooks, Lakeflow Pipelines, Databricks SQL, and even Databricks AI/BI.
What’s New?
- Completely Serverless – No endpoint setup & no infrastructure management. Just run your query.
- Faster Batch Processing – Over 10x speed improvement with our production-grade Databricks Foundation Model API Batch backend.
- Easily extract structured insights – Using our Structured Output feature in AI Functions, our Foundation Model API extracts insights in a structure you specify. No more “convincing” the model to give you output in the schema you want!
- Real-Time Observability – Track query performance and automate error handling.
- Built for Data Intelligence Platform – Use AI Functions seamlessly in SQL, Notebooks, Workflows, DLT, Spark Streaming, AI/BI Dashboards, and even AI/BI Genie.
Databricks' Approach to Batch Inference
Many AI platforms treat batch inference as an afterthought, requiring manual data exports and endpoint management that result in fragmented workflows. With Databricks SQL, you can test your query on a couple rows with a simple LIMIT clause. If you realize you might want to filter on a column, you can easily add a WHERE clause. And then just remove the LIMIT to run at scale. To those who regularly write SQL, this may seem obvious, but in most other GenAI platforms, this would have required multiple file exports and custom filtering code!
Once you have your query tested, running it as part of your data pipeline is as simple as adding a task in a Workflow and incrementalizing it is easy with Lakeflow. And if a different user runs this query, it’ll only show the results for the rows they have access to in Unity Catalog. That’s concretely what it means that this product runs directly within the Data Intelligence Platform—your data stays where it is, simplifying governance, and cutting down the hassle of managing multiple tools.
You can use both SQL and Python to use AI Functions, making Batch AI accessible to both analysts and data scientists. Customers are already having success with AI Functions:
“Batch AI with AI Functions is streamlining our AI workflows. It's allowing us to integrate large-scale AI inference with a simple SQL query-no infrastructure management needed. This will directly integrate into our pipelines cutting costs and reducing configuration burden. Since adopting it we've seen dramatic acceleration in our developer velocity when combining traditional ETL and data pipelining with AI inference workloads.” —Ian Cadieu, CTO, Altana
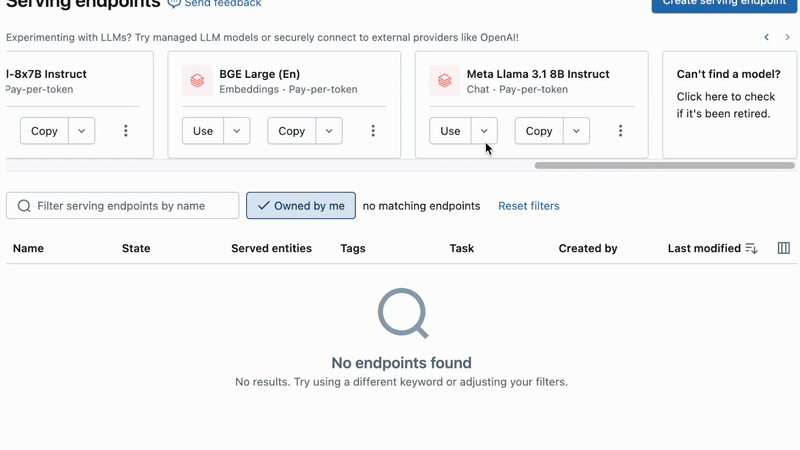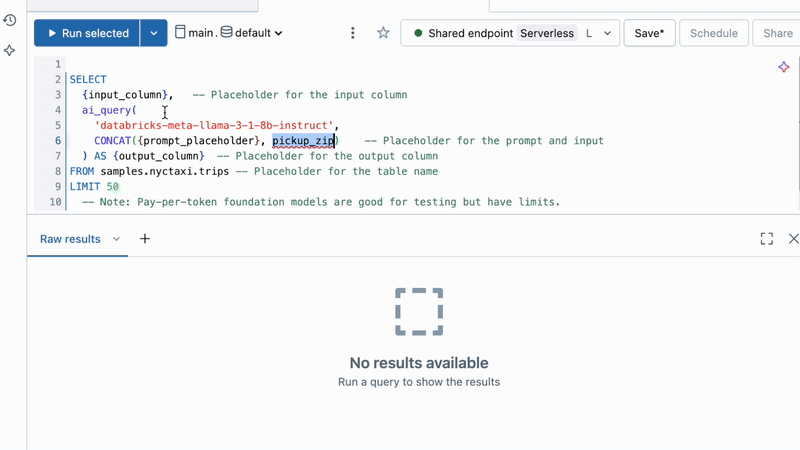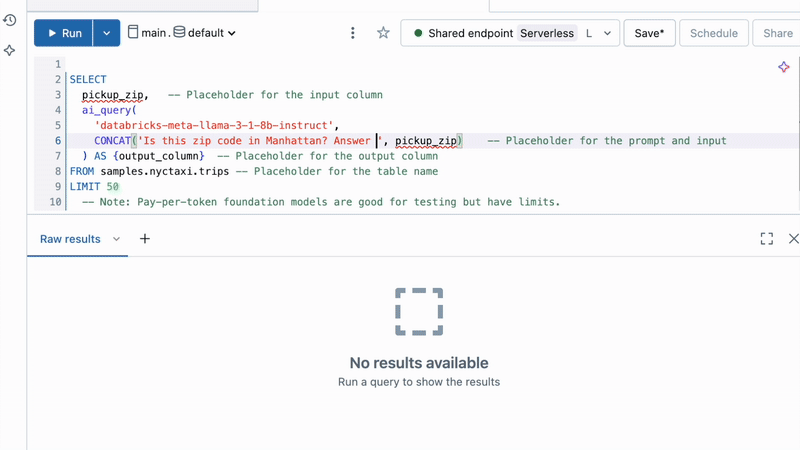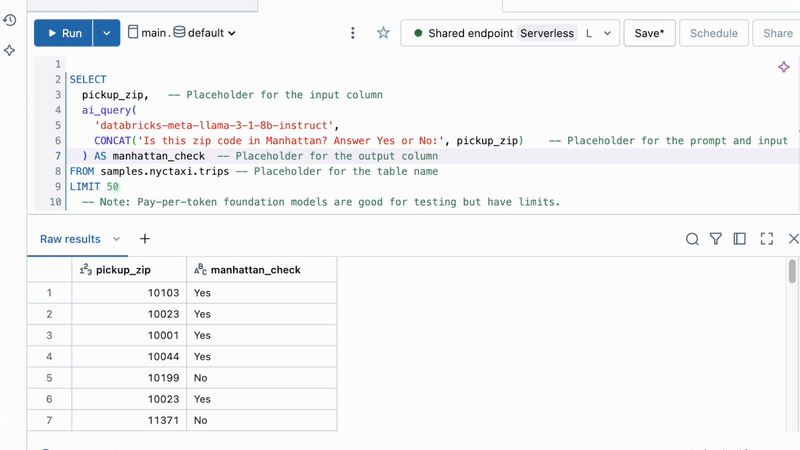
Running AI on customer support transcripts is as simple as this:
Or applying batch inference at scale in Python:
Deep Dive into the Latest Improvements
1. Instant, Serverless Batch AI
Previously, most AI Functions either had throughput limits or required dedicated endpoint provisioning, which restricted their use at high scale or added operational overhead in managing and maintaining endpoints.
Starting today, AI Functions are fully serverless—no endpoint setup needed at any scale! Simply call ai_query or task-based functions like ai_classify or ai_translate, and inference runs instantly, no matter the table size. The Foundation Model API Batch Inference service manages resource provisioning automatically behind the scenes, scaling up jobs that need high throughput while delivering predictable job completion times.
For more control, ai_query() still lets you choose specific Llama or GTE embedding models, with support for additional models coming soon. Other models, including fine-tuned LLMs, external LLMs (such as Anthropic & OpenAI), and classical AI models, can also still be used with ai_query() by deploying them on Databricks Model Serving.
2. >10x Faster Batch Inference
We have optimized our system for Batch Inference at every layer. Foundation Model API now offers much higher throughput that enables faster job completion times and industry-leading TCO for Llama model inference. Additionally, long-running batch inference jobs are now significantly faster due to our systems intelligently allocating capacity to jobs. AI functions are able to adaptively scale up backend traffic, enabling production-grade reliability.
As a result of this, AI Functions execute >10x faster, and in some cases up to 100x faster, reducing processing time from hours to minutes. These optimizations apply across general-purpose (ai_query) and task-specific (ai_classify, ai_translate) functions, making Batch AI practical for high-scale workloads.
| Workload | Previous Runtime (s) | New Runtime (s) | Improvement |
|---|---|---|---|
| Summarize 10,000 documents | 20,400 | 158 | 129x faster |
| Classify 10,000 customer support interactions | 13,740 | 73 | 188x faster |
| Translate 50,000 texts | 543,000 | 658 | 852x faster |
3. Easily extract structured insights with Structured Output
GenAI models have shown amazing promise at helping analyze large corpuses of unstructured data. We’ve found numerous businesses benefit from being able to specify a schema for the data they want to extract. However, previously, folks relied on brittle prompt engineering techniques and sometimes repeated queries to iterate on the answer to arrive at a final answer with the right structure.
To solve this problem, AI Functions now support Structured Output, allowing you to define schemas directly in queries and using inference-layer techniques to ensure model outputs conform to the schema. We have seen this feature dramatically improve performance for structured generation tasks, enabling businesses to launch it into production consumer apps. With a consistent schema, users can ensure consistency of responses and simplify integration into downstream workflows.
Example: Extract structured metadata from research papers:
4. Real-Time Observability & Reliability
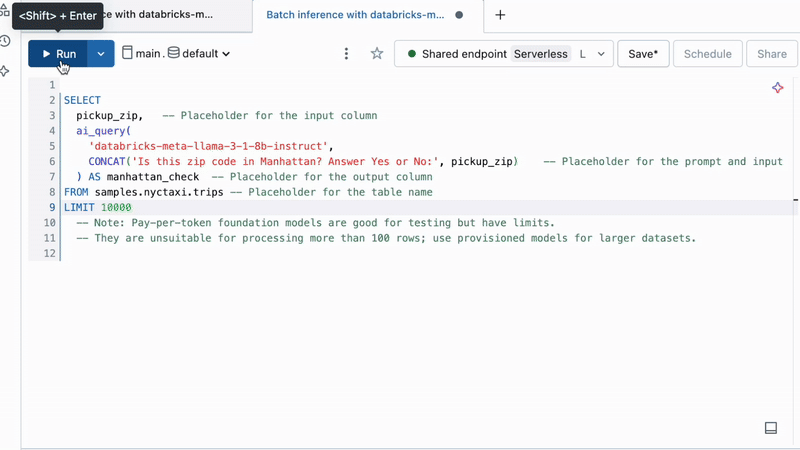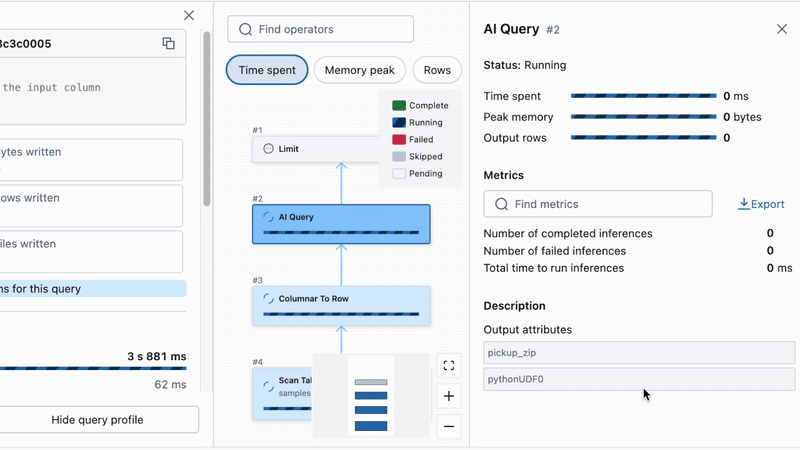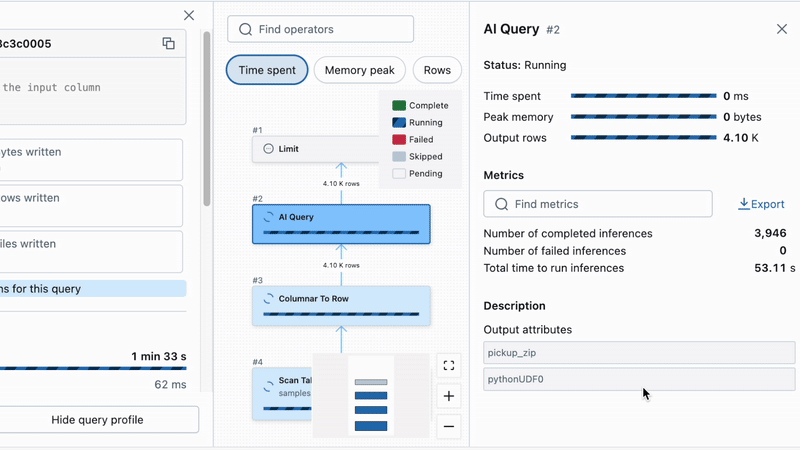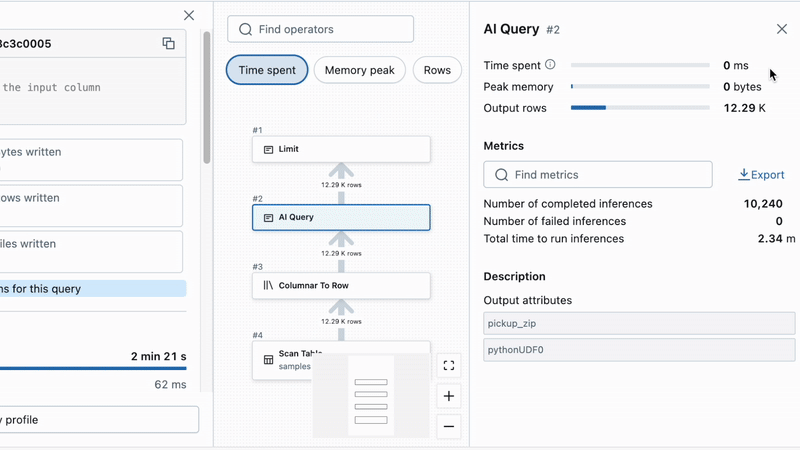
Tracking the progress of your batch inference job is now much easier. We surface live statistics about inference failures to help track down any performance concerns or invalid data. All this data can be found in the Query Profile UI, which provides real-time execution status, processing times, and error visibility. In AI Functions, we’ve built automatic retries that handle transient failures, and setting the fail_on_error flag to false can ensure a single bad row does not fail the entire job.
5. Built for the Data Intelligence Platform
AI Functions run natively across the Databricks Intelligence Platform, including SQL, Notebooks, DBSQL, AI/BI Dashboards, and AI/BI Genie—bringing intelligence to every user, everywhere.
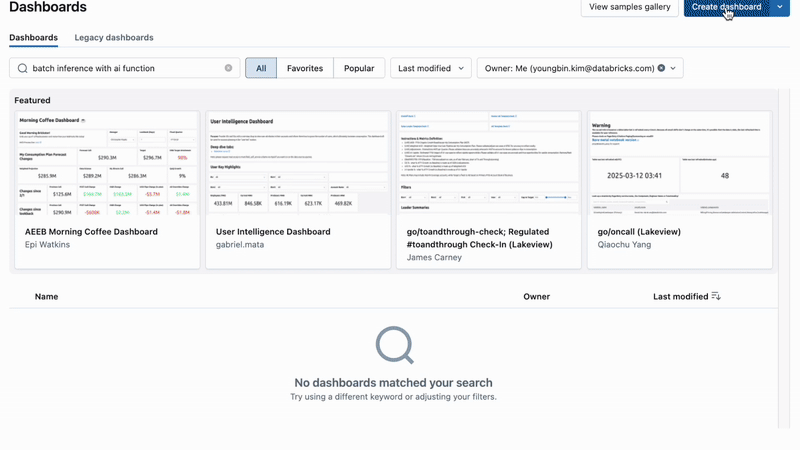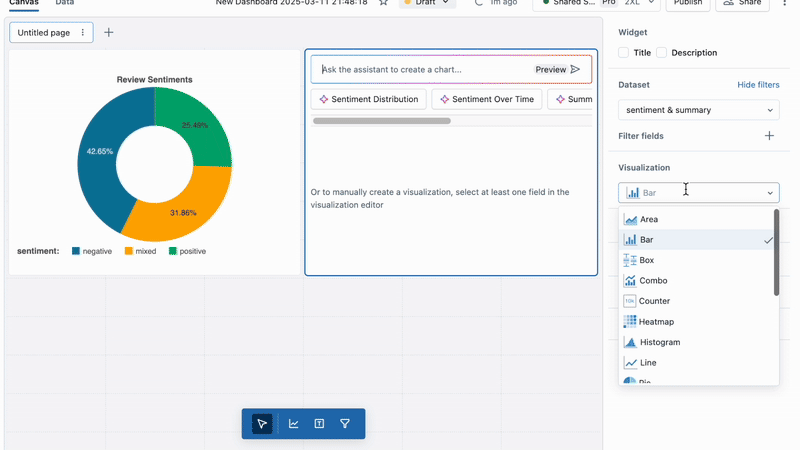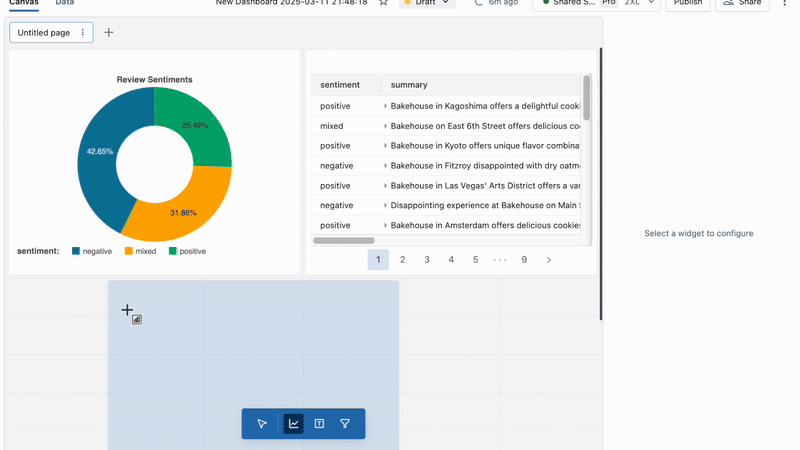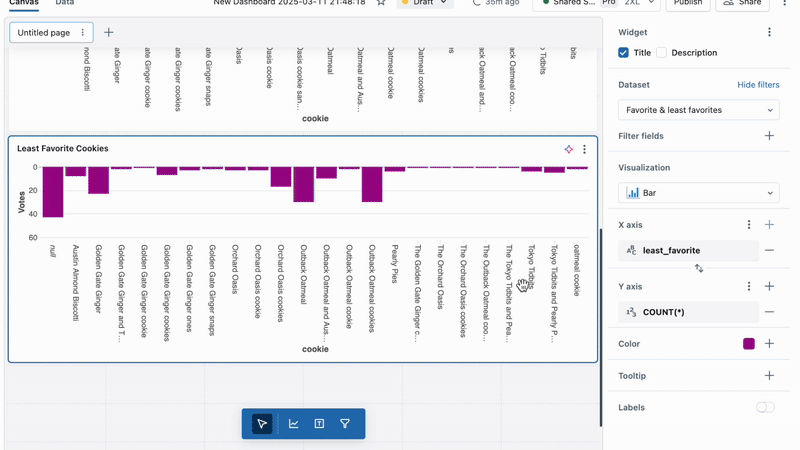
With Spark Structured Streaming and Delta Live Tables (coming soon), you can integrate AI functions with custom preprocessing, post-processing logic, and other AI Functions to build end-to-end AI batch pipelines.
Start Using Batch Inference with AI Functions Now
Batch AI is now simpler, faster, and fully integrated. Try it today and unlock enterprise-scale batch inference with AI.
- Explore the docs to see how AI Functions simplify batch inference within Databricks
- Watch the demo for a step-by-step guide to running batch LLM inference at scale.
- Learn how to deploy a production-grade Batch AI pipeline at scale.
- Check out the Compact Guide to AI Agents to learn how to maximize your GenAI ROI.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.