An Introduction to Time Series Forecasting with Generative AI
by Ryuta Yoshimatsu , Puneet Jain and Bryan Smith
An Introduction to Time Series Forecasting with Generative AI
Time series forecasting has been a cornerstone of enterprise resource planning for decades. Predictions about future demand guide critical decisions such as the number of units to stock, labor to hire, capital investments into production and fulfillment infrastructure, and the pricing of goods and services. Accurate demand forecasts are essential for these and many other business decisions.
However, forecasts are rarely if ever perfect. In the mid-2010s, many organizations dealing with computational limitations and limited access to advanced forecasting capabilities reported forecast accuracies of only 50-60%. But with the wider adoption of the cloud, the introduction of far more accessible technologies and the improved accessibility of external data sources such as weather and event data, organizations are beginning to see improvements.
As we enter the era of generative AI, a new class of models referred to as time series transformers appears capable of helping organizations deliver even more improvement. Similar to large language models (like ChatGPT) that excel at predicting the next word in a sentence, time series transformers predict the next value in a numerical sequence. With exposure to large volumes of time series data, these models become experts at picking up on subtle patterns of relationships between the values in these series with demonstrated success across a variety of domains.
In this blog, we will provide a high-level introduction to this class of forecasting models, intended to help managers, analysts and data scientists develop a basic understanding of how they work. We will then provide access to a series of notebooks built around publicly available datasets demonstrating how organizations housing their data in Databricks may easily tap into several of the most popular of these models for their forecasting needs. We hope that this helps organizations tap into the potential of generative AI for driving better forecast accuracies.
Understanding Time Series Transformers
Generative AI models are a form of a deep neural network, a complex machine learning model within which a large number of inputs are combined in a variety of ways to arrive at a predicted value. The mechanics of how the model learns to combine inputs to arrive at an accurate prediction is referred to as a model's architecture.
The breakthrough in deep neural networks that have given rise to generative AI has been the design of a specialized model architecture called a transformer. While the exact details of how transformers differ from other deep neural network architectures are quite complex, the simple matter is that the transformer is very good at picking up on the complex relationships between values in long sequences.
To train a time series transformer, an appropriately architected deep neural network is exposed to a large volume of time series data. After it has had the opportunity to train on millions if not billions of time series values, it learns the complex patterns of relationships found in these datasets. When it is then exposed to a previously unseen time series, it can use this foundational knowledge to identify where similar patterns of relationships within the time series exist and predict new values in the sequence.
This process of learning relationships from large volumes of data is referred to as pre-training. Because the knowledge gained by the model during pre-training is highly generalizable, pre-trained models referred to as foundation models can be employed against previously unseen time series without additional training. That said, additional training on an organization's proprietary data, a process referred to as fine-tuning, may in some instances help the organization achieve even better forecast accuracy. Either way, once the model is deemed to be in a satisfactory state, the organization simply needs to present it with a time series and ask, what comes next?
Addressing Common Time Series Challenges
While this high-level understanding of a time series transformer may make sense, most forecast practitioners will likely have three immediate questions. First, while two time series may follow a similar pattern, they may operate at completely different scales, how does a transformer overcome that problem? Second, within most time series models there are daily, weekly and annual patterns of seasonality that need to be considered, how do models know to look for those patterns? Third, many time series are influenced by external factors, how can this data be incorporated into the forecast generation process?
The first of these challenges is addressed by mathematically standardizing all time series data using a set of techniques referred to as scaling. The mechanics of this are internal to each model's architecture but essentially incoming time series values are converted to a standard scale that allows the model to recognize patterns in the data based on its foundational knowledge. Predictions are made and those predictions are then returned to the original scale of the original data.
Regarding the seasonal patterns, at the heart of the transformer architecture is a process called self-attention. While this process is quite complex, fundamentally this mechanism allows the model to learn the degree to which specific prior values influence a given future value.
While that sounds like the solution for seasonality, it's important to understand that models differ in their ability to pick up on low-level patterns of seasonality based on how they divide time series inputs. Through a process called tokenization, values in a time series are divided into units called tokens. A token may be a single time series value or it may be a short sequence of values (often referred to as a patch).
The size of the token determines the lowest level of granularity at which seasonal patterns can be detected. (Tokenization also defines logic for dealing with missing values.) When exploring a particular model, it's important to read the sometimes technical information around tokenization to understand whether the model is appropriate for your data.
Finally, regarding external variables, time series transformers employ a variety of approaches. In some, models are trained on both time series data and related external variables. In others, models are architected to understand that a single time series may be composed of multiple, parallel, related sequences. Regardless of the precise technique employed, some limited support for external variables can be found with these models.
A Brief Look at Four Popular Time Series Transformers
With a high-level understanding of time series transformers under our belt, let's take a moment to look at four popular foundation time series transformer models:
Chronos
Chronos is a family of open-source, pretrained time series forecasting models from Amazon. These models take a relatively naive approach to forecasting by interpreting a time series as just a specialized language with its own patterns of relationships between tokens. Despite this relatively simplistic approach which includes support for missing values but not external variables, the Chronos family of models has demonstrated some impressive results as a general-purpose forecasting solution (Figure 1).

Figure 1. Evaluation metrics for Chronos and various other forecasting models applied to 27 benchmarking data sets (from https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFM is an open-source foundation model developed by Google Research, pre-trained on over 100 billion real-world time series points. Unlike Chronos, TimesFM includes some time series-specific mechanisms in its architecture that enable the user to exert fine-grained control over how inputs and outputs are organized. This has an impact on how seasonal patterns are detected but also the computation times associated with the model. TimesFM has proven itself to be a very powerful and flexible time series forecasting tool (Figure 2).
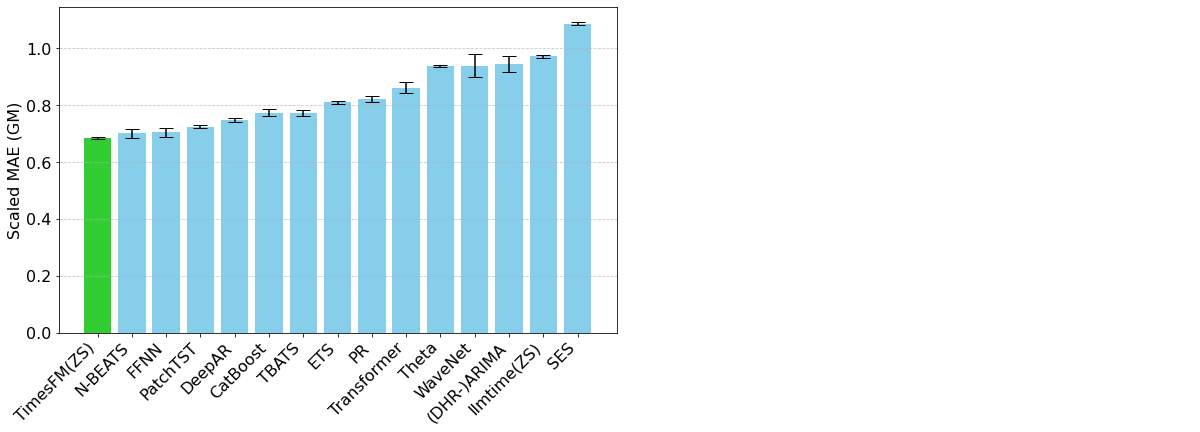
Figure 2. Evaluation metrics for TimesFM and various other models against the Monash Forecasting Archive dataset (from https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Moirai, developed by Salesforce AI Research, is another open-source foundation model for time series forecasting. Trained on "27 billion observations spanning 9 distinct domains", Moirai is presented as a universal forecaster capable of supporting both missing values and external variables. Variable patch sizes allow organizations to tune the model to the seasonal patterns in their datasets and when applied properly have been demonstrated to perform quite well against other models (Figure 3).

Figure 3. Evaluation metrics for Moirai and various other models against the Monash Time Series Forecasting Benchmark (from https://blog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPT is a proprietary model with support for external (exogenous) variables but not missing values. Focused on ease of use, TimeGPT is hosted through a public API that allows organizations to generate forecasts with as little as a single line of code. In benchmarking the model against 300,000 unique series at different levels of temporal granularity, the model was shown to produce some impressive results with very little forecasting latency (Figure 4).
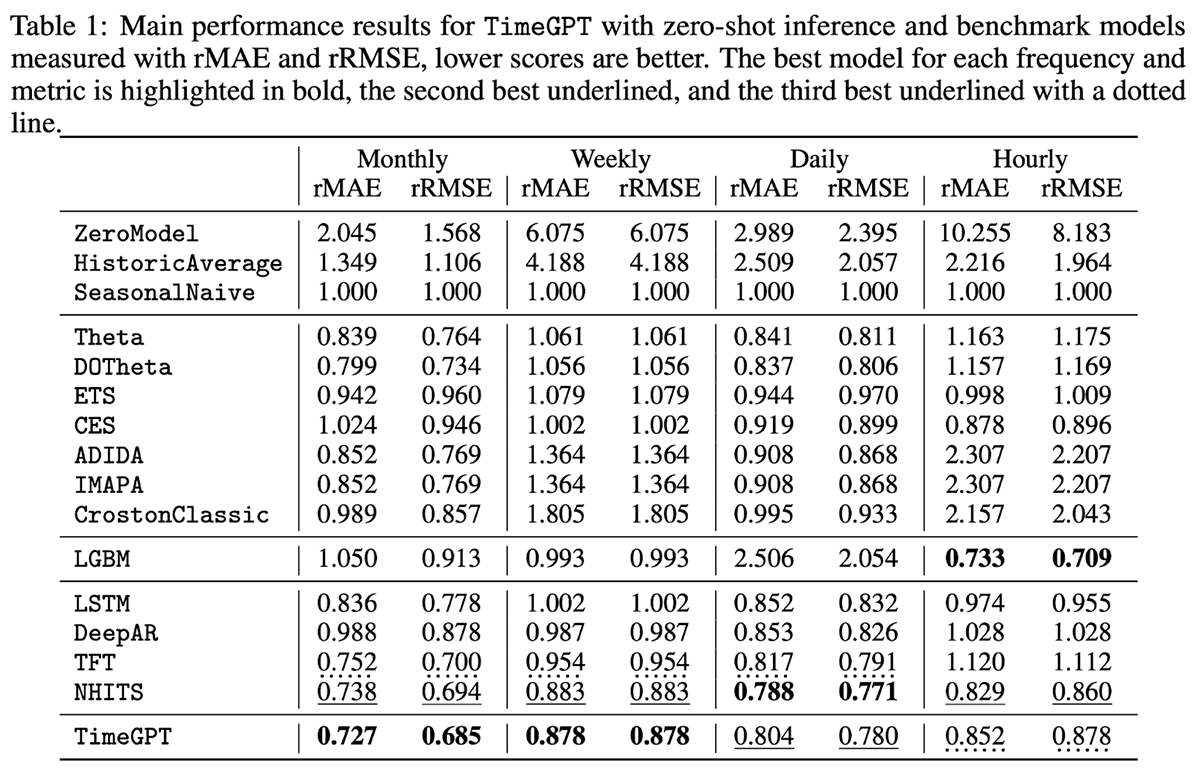
Figure 4. Evaluation metrics for TimeGPT and various other models against 300,000 unique series (from https://arxiv.org/pdf/2310.03589)
Getting Started with Transformer Forecasting on Databricks
With so many model options and more still on the way, the key question for most organizations is, how to get started in evaluating these models using their own proprietary data? As with any other forecasting approach, organizations using time series forecasting models must present their historical data to the model to create predictions, and those predictions must be carefully evaluated and eventually deployed to downstream systems to make them actionable.
Because of Databricks' scalability and efficient use of cloud resources, many organizations have long used it as the basis for their forecasting work, producing tens of millions of forecasts on a daily and even higher frequency to run their business operations. The introduction of a new class of forecasting models doesn't change the nature of this work, it simply provides these organizations more options for doing it within this environment.
That's not to say that there are not some new wrinkles that come with these models. Built on a deep neural network architecture, many of these models perform best when employed against a GPU, and in the case of TimeGPT, they may require API calls to an external infrastructure as part of the forecast generation process. But fundamentally, the pattern of housing an organization's historical time series data, presenting that data to a model and capturing the output to a queriable table remains unchanged.
To help organizations understand how they may use these models within a Databricks environment, we've assembled a series of notebooks demonstrating how forecasts can be generated with each of the four models described above. Practitioners may freely download these notebooks and employ them within their Databricks environment to gain familiarity with their use. The code presented may then be adapted to other, similar models, providing organizations using Databricks as the basis for their forecasting efforts additional options for using generative AI in their resource planning processes.
Get started with Databricks for forecasting modeling today with this series of notebooks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.