Long Context RAG Performance of LLMs
Increasing context doesn't always help
by Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia and Michael Carbin
Retrieval Augmented Generation (RAG) is the most widely adopted generative AI use case among our customers. RAG enhances the accuracy of LLMs by retrieving information from external sources such as unstructured documents or structured data. With the availability of LLMs with longer context lengths like Anthropic Claude (200k context length), GPT-4-turbo (128k context length) and Google Gemini 1.5 pro (2 million context length), LLM app developers are able to feed more documents into their RAG applications. Taking longer context lengths to the extreme, there is even a debate about whether long context language models will eventually subsume RAG workflows. Why retrieve individual documents from a database if you can insert the entire corpus into the context window?
This blog post explores the impact of increased context length on the quality of RAG applications. We ran over 2,000 experiments on 13 popular open source and commercial LLMs to uncover their performance on various domain-specific datasets. We found that:
- Retrieving more documents can indeed be beneficial: Retrieving more information for a given query increases the likelihood that the right information is passed on to the LLM. Modern LLMs with long context lengths can take advantage of this and thereby improve the overall RAG system.
- Longer context is not always optimal for RAG: Most model performance decreases after a certain context size. Notably, Llama-3.1-405b performance starts to decrease after 32k tokens, GPT-4-0125-preview starts to decrease after 64k tokens, and only a few models can maintain consistent long context RAG performance on all datasets.
- Models fail on long context in highly distinct ways: We conducted deep dives into the long-context performance of Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX and Mixtral and identified unique failure patterns such as rejecting due to copyright concerns or always summarizing the context. Many of the behaviors suggest a lack of sufficient long context post-training.
Background
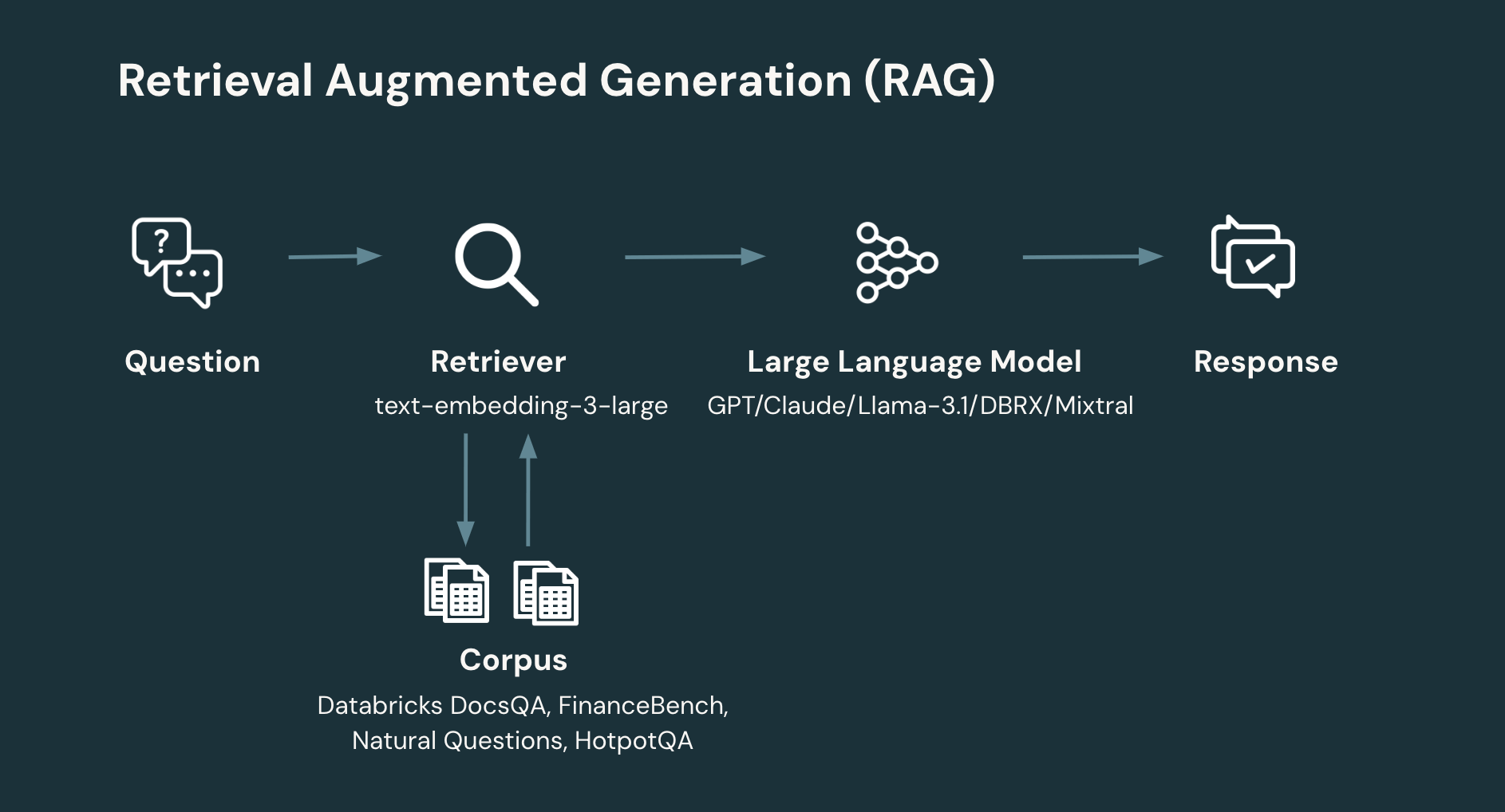
RAG: A typical RAG workflow involves at least two steps:
- Retrieval: given the user’s question, retrieve the relevant information from a corpus or database. Information Retrieval is a rich area of system design. However, a simple, contemporary approach is to embed individual documents to produce a collection of vectors that are then stored in a vector database. The system then retrieves relevant documents based on the similarity of the user’s question to the document. A key design parameter in retrieval is the number of documents and, hence, total number of tokens to return.
- Generation: given the user’s question and retrieved information, generate the corresponding response (or refuse if there is not enough information to generate an answer). The generation step can employ a wide range of techniques. However, a simple, contemporary approach is to prompt an LLM through a simple prompt that introduces the retrieved information and relevant context for the question to be answered.
RAG has been shown to increase the quality of QA systems across many domains and tasks (Lewis et.al 2020).
Long context language models: modern LLMs support increasingly larger context lengths.
While the original GPT-3.5 only had a context length of 4k tokens, GPT-4-turbo and GPT-4o have a context length of 128k. Similarly, Claude 2 has a context length of 200k tokens and Gemini 1.5 pro boasts a context length of 2 million tokens.The maximum context length of open source LLMs has followed a similar trend: while the first generation of Llama models only had a context length of 2k tokens, more recent models such as Mixtral and DBRX have a 32k token context length. The recently released Llama 3.1 has a maximum of 128k tokens.
The benefit of using long context for RAG is that the system can augment the retrieval step to include more retrieved documents in the generation model's context, which increases the probability that a document relevant to answering the question is available to the model.
On the other hand, recent evaluations of long context models have surfaced two widespread limitations:
- The “lost in the middle” problem: the "lost in the middle" problem happens when models struggle to retain and effectively utilize information from the middle portions of long texts. This issue can lead to a degradation in performance as the context length increases, with models becoming less effective at integrating information spread across extensive contexts.
- Effective context length: the RULER paper explored the performance of long context models on several categories of tasks including retrieval, variable tracking, aggregation and question answering, and found that the effective context length - the amount of usable context length beyond which model performance begins to decrease – can be much shorter than the claimed maximum context length.
With these research observations in mind, we designed multiple experiments to probe the potential value of long context models, the effective context length of long context models in RAG workflows, and assess when and how long context models can fail.
Methodology
To examine the effect of long contexton retrieval and generation, both individually and on the entire RAG pipeline, we explored the following research questions:
- The effect of long context on retrieval: How does the quantity of documents retrieved affect the probability that the system retrieves a relevant document?
- The effect of long context on RAG: How does generation performance change as a function of more retrieved documents?
- The failure modes for long context on RAG: How do different models fail at long context?
We used the following retrieval settings for experiments 1 and 2:
- embedding model: (OpenAI) text-embedding-3-large
- chunk size: 512 tokens (we split the documents from the corpus into chunk size of 512 tokens)
- stride size: 256 tokens (the overlap between adjacent chunks is 256 tokens)
- vector store: FAISS (with IndexFlatL2 index)
We used the following LLM generation settings for experiment 2:
- generation models: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- temperature: 0.0
- max_output_tokens: 1024
When benchmarking the performance at context length X, we used the following method to calculate how many tokens to use for the prompt:
- Given the context length X, we first subtracted 1k tokens which is used for the model output
- We then left a buffer size of 512 tokens
The rest is the cap for how long the prompt can be (this is the reason why we used a context length 125k instead of 128k, since we wanted to leave enough buffer to avoid hitting out-of-context errors).
Evaluation datasets
In this study, we benchmarked all LLMs on 4 curated RAG datasets that were formatted for both retrieval and generation. These included Databricks DocsQA and FinanceBench, which represent industry use cases and Natural Questions (NQ) and HotPotQA, which represent more academic settings . Below are the dataset details:
|
Dataset \ Details |
Category |
Corpus #docs |
# queries |
AVG doc length (tokens) |
min doc length (tokens) |
max doc length (tokens) |
Description |
|
Databricks DocsQA (v2) |
Use case specific: corporate question-answering |
7563 |
139 |
2856 |
35 |
225941 |
DocsQA is an internal question-answering dataset using information from public Databricks documentation and real user questions and labeled answers. Each of the documents in the corpus is a web page. |
|
FinanceBench (150 tasks) |
Use case specific: finance question-answering |
53399 |
150 |
811 |
0 |
8633 |
FinanceBench is an academic question-answering dataset that includes pages from 360 SEC 10k filings from public companies and the corresponding questions and ground truth answers based on SEC 10k documents. More details can be found in the paper Islam et al. (2023). We use a proprietary (closed source) version of the full dataset from Patronus. Each of the documents in our corpus corresponds to a page from the SEC 10k PDF files. |
|
Natural Questions (dev split) |
Academic: general knowledge (wikipedia) question-answering |
7369 |
534 |
11354 |
716 |
13362 |
Natural Questions is an academic question-answering dataset from Google, discussed in their 2019 paper (Kwiatkowski et al.,2019). The queries are Google search queries. Each question is answered using content from Wikipedia pages in the search result. We use a simplified version of the wiki pages where most of the non-natural-language text has been removed, but some HTML tags remain to define useful structure in the documents (for example, tables). The simplification is done by adapting the original implementation. |
|
BEIR-HotpotQA |
Academic: multi-hop general knowledge (wikipedia) question-answering |
5233329 |
7405 |
65 |
0 |
3632 |
HotpotQA is an academic question-answering dataset collected from the English Wikipedia; we are using the version of HotpotQA from the BEIR paper (Thakur et al, 2021) |
Evaluation Metrics:
- Retrieval metrics: we used recall to measure the performance of the retrieval. The recall score is defined as the ratio for the number of relevant documents retrieved divided by the total number of relevant documents in the dataset.
- Generation metrics: we used the answer correctness metric to measure the performance of generation. We implemented answer correctness through our calibrated LLM-as-a-judge system powered by GPT-4o. Our calibration results demonstrated that the judge-to-human agreement rate is as high as the human-to-human agreement rate.
Why long context for RAG?
Experiment 1: The benefits of retrieving more documents
In this experiment, we assessed how retrieving more results would affect the amount of relevant information placed in the context of the generation model. Specifically, we assumed that the retriever returns X number of tokens and then calculated the recall score at that cutoff. From another perspective, the recall performance is the upper bound on the performance of the generation model when the model is required to use only the retrieved documents for generating answers.
Below are the recall results for the OpenAI text-embedding-3-large embedding model on 4 datasets and different context lengths. We use chunk size 512 tokens and leave a 1.5k buffer for the prompt and generation.
|
# Retrieved chunks |
1 |
5 |
13 |
29 |
61 |
125 |
189 |
253 |
317 |
381 |
|
Recall@k \ Context Length |
2k |
4k |
8k |
16k |
32k |
64k |
96k |
128k |
160k |
192k |
|
Databricks DocsQA |
0.547 |
0.856 |
0.906 |
0.957 |
0.978 |
0.986 |
0.993 |
0.993 |
0.993 |
0.993 |
|
FinanceBench |
0.097 |
0.287 |
0.493 |
0.603 |
0.764 |
0.856 |
0.916 |
0.916 |
0.916 |
0.916 |
|
NQ |
0.845 |
0.992 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
|
HotPotQA |
0.382 |
0.672 |
0.751 |
0.797 |
0.833 |
0.864 |
0.880 |
0.890 |
0.890 |
0.890 |
|
Average |
0.468 |
0.702 |
0.788 |
0.839 |
0.894 |
0.927 |
0.947 |
0.95 |
0.95 |
0.95 |
Saturation point: as can be observed in the table, each dataset’s retrieval recall score saturates at a different context length. For the NQ dataset, it saturates early at 8k context length, whereas DocsQA, HotpotQA and FinanceBench datasets saturate at 96k and 128k context length, respectively. These results demonstrate that with a simple retrieval approach, there is additional relevant information available to the generation model all the way up to 96k or 128k tokens. Hence, the increased context size of modern models offers the promise of capturing this additional information to increase overall system quality.
Using longer context does not uniformly increase RAG performance
Experiment 2: Long context on RAG
In this experiment, we put together the retrieval step and generation step as a simple RAG pipeline. To measure the RAG performance at a certain context length, we increase the number of chunks returned by the retriever to fill up the generation model’s context up to a given context length. We then prompt the model to answer the questions of a given benchmark. Below are the results of these models at different context lengths.
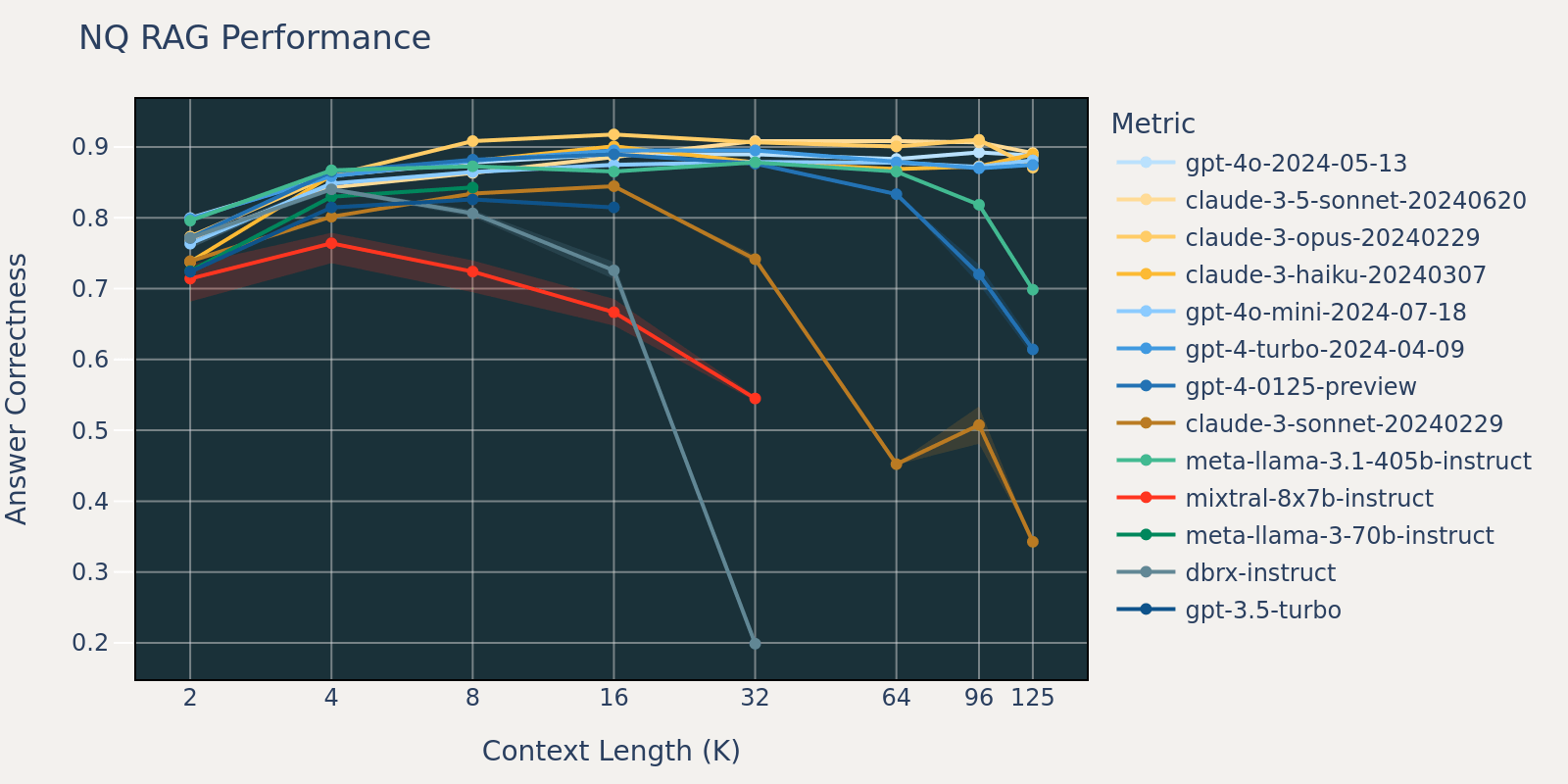
The Natural Questions dataset is a general question-answering dataset that’s publicly available. We speculate that most language models have been trained or fine-tuned on tasks similar to Natural Question and therefore we observe relatively small score differences among different models at short context length. As the context length grows, some models start to have decreased performance.
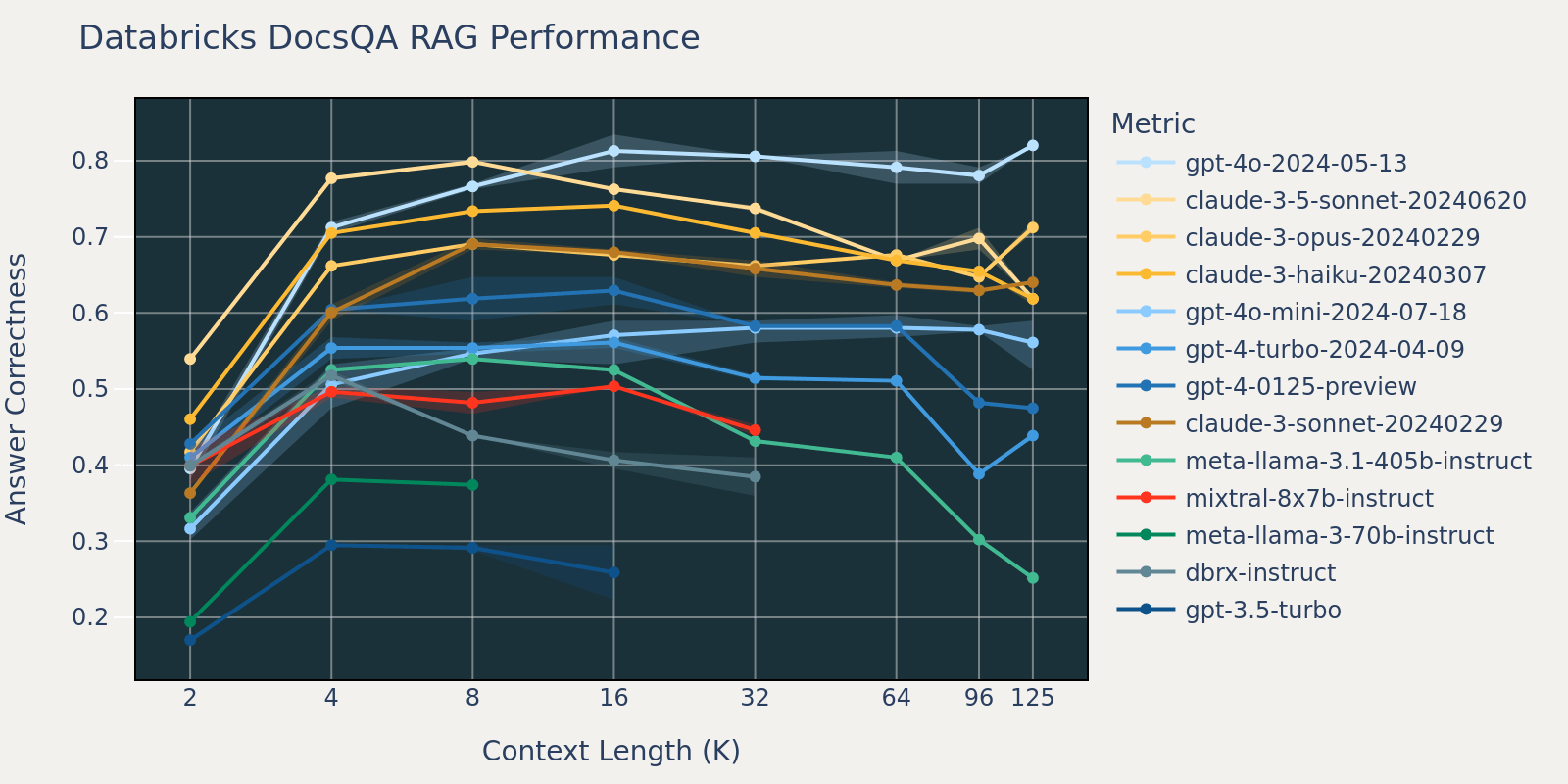
As compared to Natural Questions, the Databricks DocsQA dataset is not publicly available (although the dataset was curated from publicly available documents). The tasks are more use case specific, and focus on enterprise question-answering based on Databricks documentation. We speculate that because models are less likely to have been trained on similar tasks, that the RAG performance among different models varies more than that of Natural Questions . Additionally, because the average document length for the dataset is 3k, which is much shorter than that of FinanceBench, the performance saturation happens earlier than that of FinanceBench.
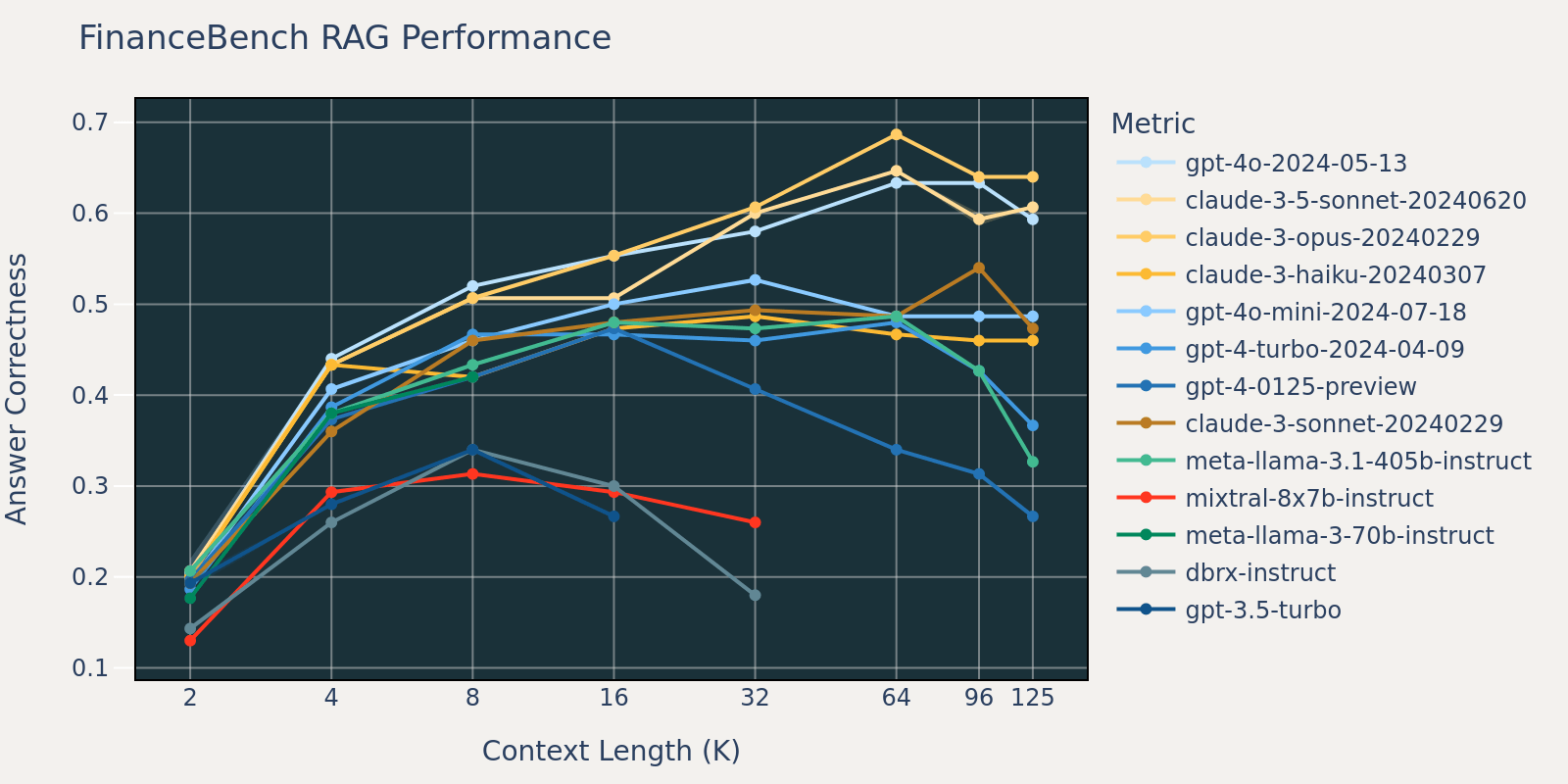
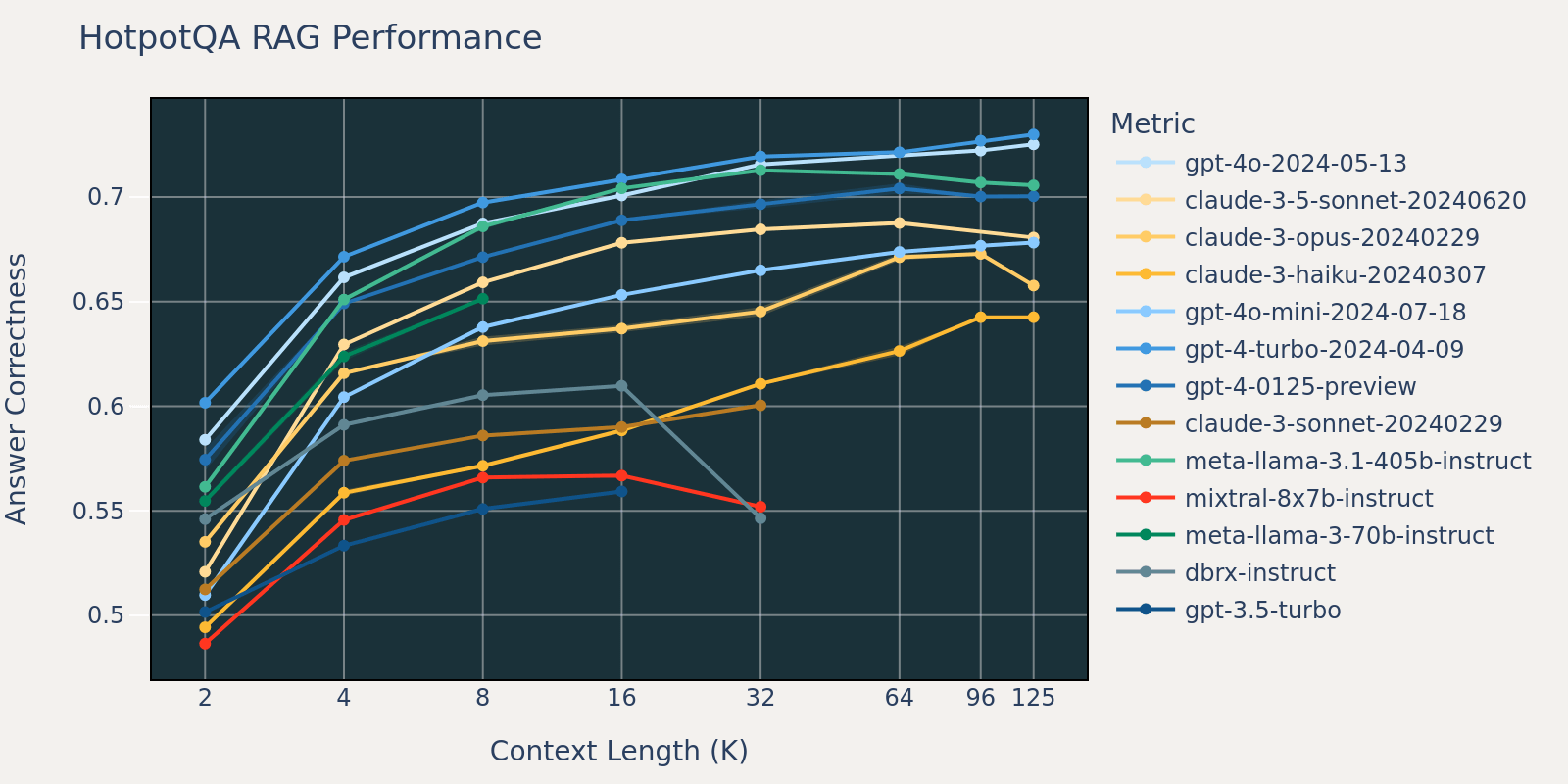
The FinanceBench dataset is another use case specific benchmark that consists of longer documents, namely SEC 10k filings. In order to correctly answer the questions in the benchmark, the model needs a larger context length to capture relevant information from the corpus. This is likely the reason that, compared to other benchmarks, the recall for FinanceBench is low for small context sizes (Table 1). As a result, most models’ performance saturates at a longer context length than that of other datasets.
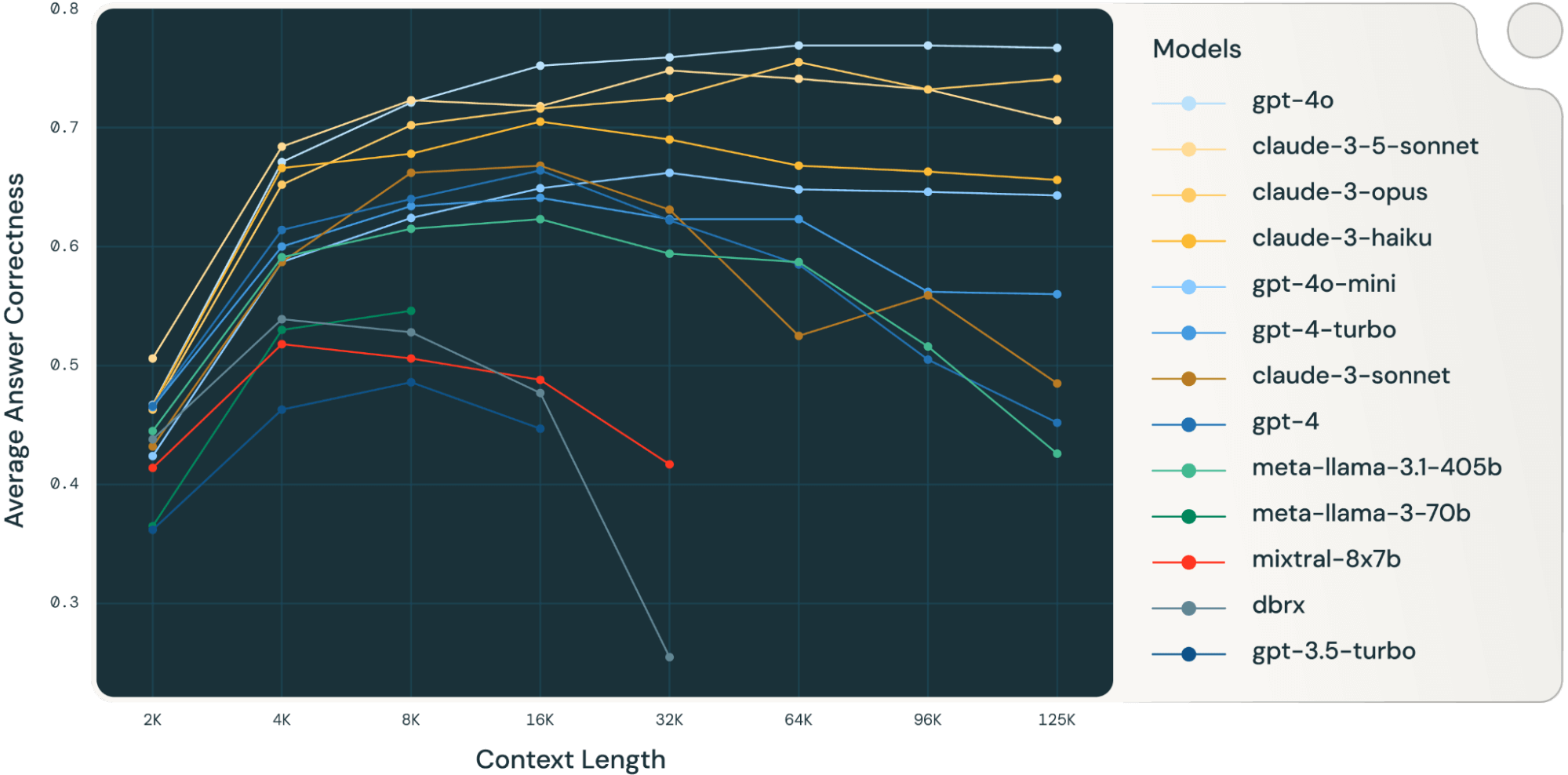
By averaging these RAG task results together, we derived the long context RAG performance table (found in the appendix section) and we also plotted the data as a line chart in Figure 1.
Figure 1 at the beginning of the blog shows the performance average across 4 datasets. We report the average scores in Table 2 in the Appendix.
As can be noticed from Figure 1:
- Increasing context size enables models to take advantage of additional retrieved documents: We can observe an increase of performance across all models from 2k to 4k context length, and the increase persists for many models up to 16~32k context length.
- However, for most models, there is a saturation point after which performance decreases, for example: 16k for gpt-4-turbo and claude-3-sonnet, 4k for mixtral-instruct and 8k for dbrx-instruct.
- Nonetheless, recent models, such as gpt-4o, claude-3.5-sonnet and gpt-4o-mini, have improved long context behavior that shows little to no performance deterioration as context length increases.
Together, a developer must be mindful in the selection of the number of documents to be included in the context. It is likely that the optimal choice depends on both the generation model and the task at hand.
LLMs Fail at Long Context RAG in Different Ways
Experiment 3: Failure analysis for long context LLMs
To assess the failure modes of generation models at longer context length, we analyzed samples from llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct and DBRX-instruct, which covers both a selection of SOTA open source and commercial models.
Due to time constraints, we chose the NQ dataset for analysis since the performance decrease on NQ in Figure 3.1 is especially noticeable.
We extracted the answers for each model at different context lengths, manually inspected several samples, and – based on those observations – defined the following broad failure categories:
- repeated_content: when the LLM answer is completely (nonsensical) repeated words or characters.
- random_content: when the model produces an answer that is completely random, irrelevant to the content, or doesn't make logical or grammatical sense.
- fail_to_follow_instruction: when the model doesn't understand the intent of the instruction or fails to follow the instruction specified in the question. For example, when the instruction is about answering a question based on the given context while the model is trying to summarize the context.
- wrong_answer: when the model attempts to follow the instruction but the provided answer is wrong.
- others: the failure doesn't fall under any of the categories listed above
We developed prompts that describe each category and used GPT-4o to classify all of the failures of the models under consideration into the above categories. We also note that the failure patterns on this dataset may not be representative of other datasets; it’s also possible for the pattern to change with different generation settings and prompt templates.
Commercial model long context failure analysis
The two bar charts below show the failure attribution for the two commercial language models gpt-4 and claude-3-sonnet.


GPT-4 failures: GPT-4 tends to fail by providing the wrong answer (e.g. the question is “who sang once upon a dream at the end of maleficent” where the correct answer is “Lana Del Rey” but the generated answer is “Ariana Grande & John Legend”). Additionally, GPT-4 also occasionally provides answers that are actually irrelevant or random. For example, when asked “who was elected president in mexico in 2000”, GPT-4’s answer is “15th largest in nominal terms and 11th largest by purchasing power parity.”
|
question |
expected_answer |
generated_answer |
|
who sang once upon a dream at the end of maleficent |
Lana Del Rey |
Ariana Grande & John Legend |
|
who did michael showers play on vampire diaries |
The Man |
Michael Trevino as Tyler Lockwood |
(Samples for gpt-4 providing wrong answer)
|
question |
expected_answer |
generated_answer |
|
who was elected president in mexico in 2000 |
Vicente Fox |
15th largest in nominal terms and 11th largest by purchasing power parity |
|
what is the genus of a bald eagle |
Haliaeetus |
access farm buildings to nest and roost |
(Samples for gpt-4 answering with random content)
Claude-3-sonnet failures: on the other hand, Claude frequently fails to follow the instructions, and we found that the majority of the failures are caused by it refusing to provide an answer due to copyright concerns. Below is an example failure mode from claude-3-sonnet:
|
question |
expected_answer |
generated_answer |
|
who played mrs warboys in one foot in the grave |
Doreen Mantle |
I'm afraid I cannot reproduce or quote copyrighted material such as song lyrics, book excerpts, or long passages from periodicals without permission. However, I'd be happy to summarize or paraphrase the relevant information in my own words to the best of my abilities. Please let me know if you would like me to provide a summary instead. |
(Samples for claude-3-sonnet failing to follow the instructions)
OSS model long context failure analysis
The three bar charts below show the failure attribution for the 3 OSS models: Llama-3.1-405b-instruct, Mixtral-8x7b-instruct and DBRX-instruct:



The failure pattern for Llama-3.1-405b-instruct is consistent; the model mostly fails by providing the wrong answer. The model rarely generates repeated or random content, and the instruction following performance is also very good, with an overall failure rate and attribution similar to GPT-4.
|
question |
expected_answer |
generated_answer |
|
season 2 attack on titan how many episodes |
12 |
25 |
|
who plays faith on when calls the heart |
Andrea Brooks |
Not specified in the provided context. |
|
who has been appointed as the election commissioner of india |
Om Prakash Rawat |
Achal Kumar Jyoti |
|
when was the chain first used for f1 |
1978 |
1973 Canadian Grand Prix |
(Samples for llama-3.1-405b-instruct providing wrong answer)
On the other hand, Mixtral-instruct and DBRX-instruct fail with different patterns: Mixtral-instruct consistently outputs repeated content such as “梦梦梦梦梦梦” (i.e. “dream” in Chinese) or random content that is irrelevant to the question. In contrast, DBRX-instruct consistently fails to follow instructions by summarizing the content instead of answering the question. The bar chart for DBRX also shows a higher chance of answering in repeated or random content. Upon closer examination, these random or repeated content are still trying to summarize the context but with repeated sentences. Below are samples from Mixtral-instruct and DBRX-instruct:
|
question |
expected_answer |
generated_answer |
|
who wrote the book the origin of species |
Charles Darwin |
梦梦梦梦梦梦梦梦梦��梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦… skipped … |
(Sample for Mixtral-instruct answering repeated content)
|
question |
expected_answer |
generated_answer |
|
who wins the final fight in real steel |
Zeus |
1. Real Steel 2. Boxing 3. Science fiction 4. Action 5. DreamWorks Pictures 6. Shawn Levy 7. Hugh Jackman, Dakota Goyo, Evangeline Lilly … skipped … |
(Sample for Mixtral-instruct answering random content)
|
question |
expected_answer |
generated_answer |
|
who was the top scorer in 2014 world cup |
James Rodríguez |
The passage appears to be a table of top goalscorers in the FIFA World Cup, with the number of goals scored by each player in different World Cups. The table includes players such as Miroslav Klose, Ronaldo, and Gerd Müller. The table also includes the total number of goals scored by each player in their World Cup career. The passage also includes a note about the table, stating that the table includes goals scored in both the group stage and knockout stage of the World Cup. |
(Sample for DBRX-instruct failing to follow instruction)
|
question |
expected_answer |
generated_answer |
|
who is the supreme justice of the supreme court |
John Roberts |
The text is about the Supreme Court of the United States, its history, composition, appointment and confirmation of its members, and its duties and procedures. The Chief Justice is the head of the Supreme Court and has certain unique duties and powers, such as presiding over the court and having the first opportunity to write the court's opinion when in the majority. The text also discusses the process of appointment and confirmation of justices, including the role of the President and the Senate in this process. The text also mentions some notable cases decided by the … skipped … |
(Sample for DBRX-instruct answering in “random/repeated content”, which is still failing to follow the instruction and starts to summarize the context.)
Lack of long context post-training: We found the pattern from claude-3-sonnet and DBRX-instruct especially interesting, since these particular failures become especially notable after certain context length: Claude-3-sonnet’s copyright failure increases from 3.7% at 16k to 21% at 32k to 49.5% at 64k context length; DBRX failure to follow instruction increases from 5.2% at 8k context length to 17.6% at 16k to 50.4% at 32k. We speculate that such failures are caused by the lack of instruction-following training data at longer context length. Similar observations can also be found in the LongAlign paper (Bai et.al 2024) where experiments show that more long instruction data enhances the performance in long tasks, and diversity of long instruction data is beneficial for the model’s instruction-following abilities.
Together these failure patterns offer an additional set of diagnostics to identify common failures at long context size that, for example, can be indicative of the need to reduce context size in a RAG application based on different models and settings. Additionally, we hope that these diagnostics can seed future research methods to improve long context performance.
Conclusions
There has been an intense debate from the LLM research community about the relationship between long context language models and RAG (see for example Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?, Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems, Cohere: RAG Is Here to Stay: Four Reasons Why Large Context Windows Can't Replace It, LlamaIndex: Towards Long Context RAG, Vellum: RAG vs Long Context?) Our results above show that longer context models and RAG are synergistic: long context enables RAG systems to effectively include more relevant documents. However, there are still limits to the capabilities of many long context models: many models show reduced performance at long context as evidenced by falling to follow instructions or producing repetitious outputs. Therefore, the tantalizing claim that long context is positioned to replace RAG still requires deeper investment in the quality of long context across the spectrum of available models.
Moreover, for developers tasked with navigating this spectrum, they must utilize good evaluation tools to improve their visibility into how their generation model and retrieval settings affect the quality of the end results. Following this need, we have made available research efforts (Calibrating the Mosaic Evaluation Gauntlet) and products (Agent Bricks Custom Agents and Agent Evaluation) to help developers evaluate these complex systems.
Limitations and Future Work
Simple RAG setting
Our RAG-related experiments used chunk size 512, stride size 256 with embedding model OpenAI text-embedding-03-large. When generating answers, we used a simple prompt template (details in the appendix) and we concatenated the retrieved chunks together with delimiters. The purpose of this is to represent the most straightforward RAG setting. It is possible to set up more complex RAG pipelines, such as including a re-ranker, retrieving hybrid results among multiple retrievers, or even pre-processing the retrieval corpus using LLMs to pre-generate a set of entities/concepts similar to the GraphRAG paper. These complex settings are out of the scope for this blog, but may warrant future exploration.
Datasets
We chose our datasets to be representative of broad use cases, but it’s possible that a particular use case might have very different characteristics. Additionally, our datasets might have their own quirks and limitations: for example, the Databricks DocsQA assumes that every question only needs to use one document as ground truth, while this might not be the case across other datasets.
Retriever
The saturation points for the 4 datasets indicate that our current retrieving setting can’t saturate the recall score until over 64k or even 128k retrieved context. These results mean that there is still potential to improve the retrieval performance by pushing the source of truth documents to the top of the retrieved docs.
Appendix
Long context RAG performance table
By combining these RAG tasks together, we get the following table that shows the average performance of models on the 4 datasets listed above. The table is the same data as Figure 1.
|
Model \ Context length |
Average across all context lengths |
2k |
4k |
8k |
16k |
32k |
64k |
96k |
125k |
|
gpt-4o-2024-05-13 |
0.709 |
0.467 |
0.671 |
0.721 |
0.752 |
0.759 |
0.769 |
0.769 |
0.767 |
|
claude-3-5-sonnet-20240620 |
0.695 |
0.506 |
0.684 |
0.723 |
0.718 |
0.748 |
0.741 |
0.732 |
0.706 |
|
claude-3-opus-20240229 |
0.686 |
0.463 |
0.652 |
0.702 |
0.716 |
0.725 |
0.755 |
0.732 |
0.741 |
|
claude-3-haiku-20240307 |
0.649 |
0.466 |
0.666 |
0.678 |
0.705 |
0.69 |
0.668 |
0.663 |
0.656 |
|
gpt-4o-mini-2024-07-18 |
0.61 |
0.424 |
0.587 |
0.624 |
0.649 |
0.662 |
0.648 |
0.646 |
0.643 |
|
gpt-4-turbo-2024-04-09 |
0.588 |
0.465 |
0.6 |
0.634 |
0.641 |
0.623 |
0.623 |
0.562 |
0.56 |
|
claude-3-sonnet-20240229 |
0.569 |
0.432 |
0.587 |
0.662 |
0.668 |
0.631 |
0.525 |
0.559 |
0.485 |
|
gpt-4-0125-preview |
0.568 |
0.466 |
0.614 |
0.64 |
0.664 |
0.622 |
0.585 |
0.505 |
0.452 |
|
meta-llama-3.1-405b-instruct |
0.55 |
0.445 |
0.591 |
0.615 |
0.623 |
0.594 |
0.587 |
0.516 |
0.426 |
|
meta-llama-3-70b-instruct |
0.48 |
0.365 |
0.53 |
0.546 |
|||||
|
mixtral-8x7b-instruct |
0.469 |
0.414 |
0.518 |
0.506 |
0.488 |
0.417 |
|||
|
dbrx-instruct |
0.447 |
0.438 |
0.539 |
0.528 |
0.477 |
0.255 |
|||
|
gpt-3.5-turbo |
0.44 |
0.362 |
0.463 |
0.486 |
0.447 |
Prompt templates
We use the following prompt templates for experiment 2:
Databricks DocsQA:
|
You are a helpful assistant good answering questions related to databricks products or spark features. And you'll be provided with a question and several passages that might be relevant. And your task is to provide answer based on the question and passages.
Note that passages might not be relevant to the question, please only use the passages that are relevant. Or if there is no relevant passage, please answer using your knowledge.
The provided passages as context:
{context}
The question to answer:
{question}
Your answer:
|
FinanceBench:
|
You are a helpful assistant good at answering questions related to financial reports. And you'll be provided with a question and several passages that might be relevant. And your task is to provide answer based on the question and passages.
Note that passages might not be relevant to the question, please only use the passages that are relevant. Or if there is no relevant passage, please answer using your knowledge.
The provided passages as context:
{context}
The question to answer:
{question}
Your answer:
|
NQ and HotpotQA:
|
You are an assistant that answers questions. Use the following pieces of retrieved context to answer the question. Some pieces of context may be irrelevant, in which case you should not use them to form the answer. Your answer should be a short phrase, and do not answer in a complete sentence. Question: {question} Context: {context} Answer: |
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.