Making AI More Accessible: Up to 80% Cost Savings with Meta Llama 3.3 on Databricks
Announcing Meta Llama 3.3 availability in Databricks Model Serving
by Ahmed Bilal, Kasey Uhlenhuth, Hanlin Tang and Ana Nieto
- 80% Cost Savings: Achieve significant cost savings with the new Llama 3.3 model and reduced pricing.
- Faster Inference Speeds: Get 40% faster responses and reduced batch processing time, enabling better customer experiences and faster insights.
- Access to the new Meta Llama 3.3 model: Databricks is the most comprehensive platform for deploying and managing Llama models.
As enterprises build agent systems to deliver high quality AI apps, we continue to deliver optimizations to deliver best overall cost-efficiency for our customers. We’re excited to announce the availability of the Meta Llama 3.3 model on the Databricks Data Intelligence Platform, and significant updates to Databricks’s Model Serving pricing and efficiency. These updates together will reduce your inference costs by up to 80%, making it significantly more cost effective than before for enterprises building AI agents or doing batch LLM processing.
- 80% Cost Savings: Achieve significant cost savings with the new Llama 3.3 model and reduced pricing.
- Faster Inference Speeds: Get 40% faster responses and reduced batch processing time, enabling better customer experiences and faster insights.
- Access to the new Meta Llama 3.3 model: leverage the latest from Meta to achieve greater quality and performance.
Build Enterprise AI Agents with Databricks and Llama 3.3
We’re proud to partner with Meta to bring Llama 3.3 70B to Databricks. This model rivals the larger Llama 3.1 405B in instruction-following, math, multilingual, and coding tasks while offering a cost-efficient solution for domain-specific chatbots, intelligent agents, and large-scale document processing.
While Llama 3.3 sets a new benchmark for open foundation models, building production-ready AI agents requires more than just a powerful model. Databricks is the most comprehensive platform for deploying and managing Llama models, with a robust suite of tools to build secure, scalable, and reliable AI agent systems that can reason over your enterprise data.
- Access Llama with a Unified API: Easily access Llama and other leading foundation models, including OpenAI and Anthropic, through a single interface. Experiment, compare, and switch models effortlessly for maximum flexibility.
- Secure and Monitor Traffic with AI Gateway: Monitor usage and request/response using Agent Bricks AI Gateway while enforcing safety policies like PII detection and harmful content filtering for secure, compliant interactions.
- Build Faster Real-Time Agents: Create high-quality real-time agents with 40% faster inference speeds, function-calling capabilities and support for manual or automated agent evaluation.
- Process Batch Workflows at Scale: Easily apply LLMs to large datasets directly on your governed data using a simple SQL interface, with 40% faster processing speeds and fault tolerance.
- Customize Models to Get High Quality: Fine-tune Llama with proprietary data to build domain-specific, high-quality solutions.
- Scale with Confidence: Grow deployments with SLA-backed serving, secure configurations, and compliance-ready solutions designed to auto-scale with your enterprise’s evolving demands.
Making GenAI More Affordable with New Pricing:
We’re rolling out proprietary efficiency improvements across our inference stack, enabling us to reduce prices and make GenAI even more accessible to everyone. Here’s a closer look at the new pricing changes:
Pay-per-Token Serving Price Cuts:
- Llama 3.1 405B model: 50% reduction in input token price, 33% reduction in output token price.
- Llama 3.3 70B and Llama 3.1 70B model: 50% reduction for both input and output tokens.
Provisioned Throughput Price Cuts:
- Llama 3.1 405B: 44% cost reduction per token processed.
- Llama 3.3 70B and Llama 3.1 70B: 49% reduction in dollars per total tokens processed.
Lowering Total Cost of Deployment by 80%
With the more efficient and high-quality Llama 3.3 70B model, combined with the pricing reductions, you can now achieve up to an 80% reduction in your total TCO.
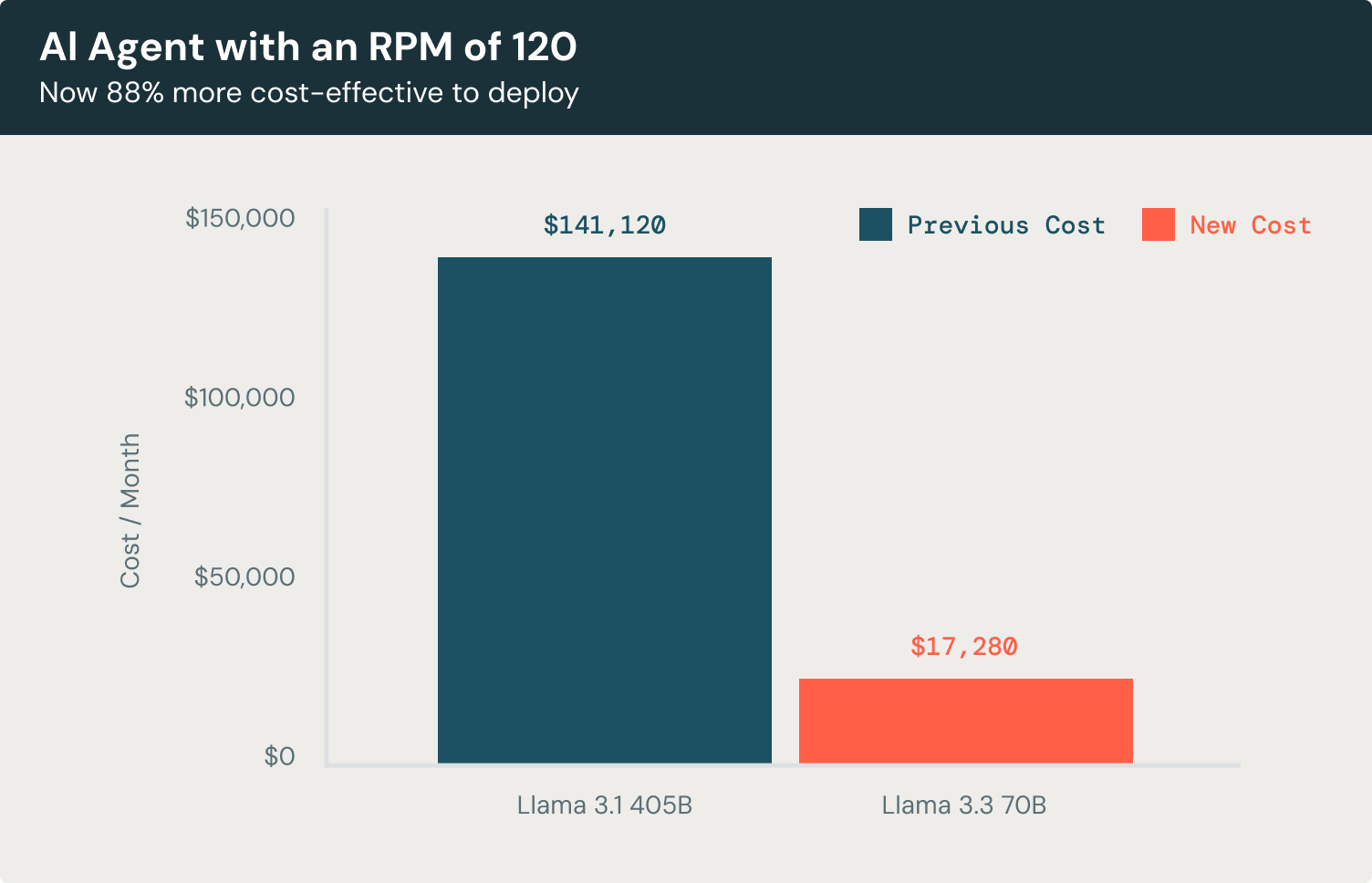
Let’s look at a concrete example. Suppose you’re building a customer service chatbot agent designed to handle 120 requests per minute (RPM). This chatbot processes an average of 3,500 input tokens and generates 300 output tokens per interaction, creating contextually rich responses for users.
Using Llama 3.3 70B, the monthly cost of running this chatbot, focusing solely on LLM usage, would be 88% lower cost compared to Llama 3.1 405B and 72% more cost-effective compared to leading proprietary models.
Now let’s take a look at a batch inference example. For tasks like document classification or entity extraction across a 100K-record dataset, the Llama 3.3 70B model offers remarkable efficiency compared to Llama 3.1 405B. Processing rows with 3500 input tokens and generating 300 output tokens each, the model achieves the same high-quality results while cutting costs by 88%, that’s 58% more cost-effective than using leading proprietary models. This enables you to classify documents, extract key entities, and generate actionable insights at scale without excessive operational expenses.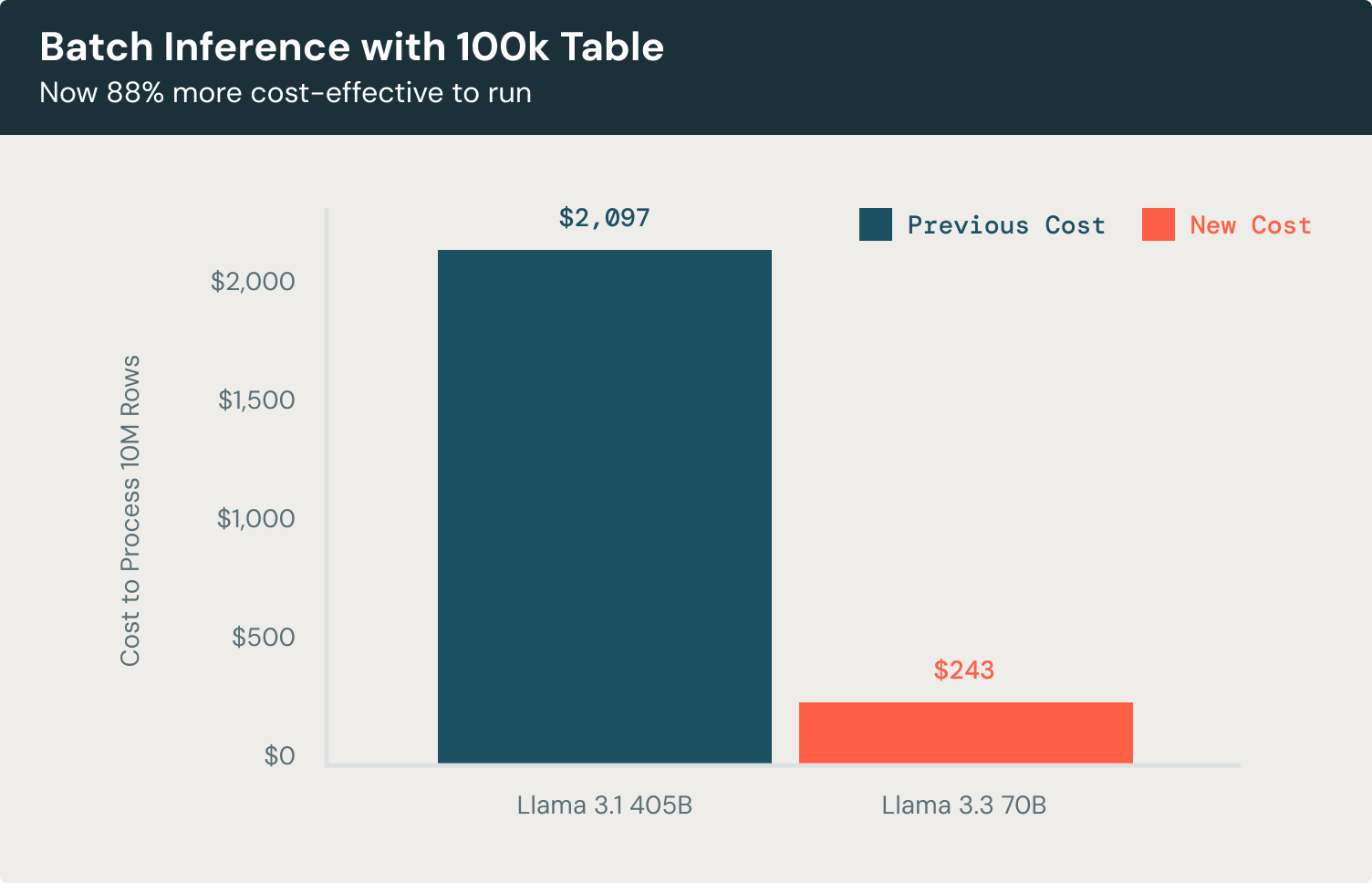
Get Started Today
Visit the AI Playground to quickly try Llama 3.3 directly from your workspace. For more information, please refer to the following resources:
- Learn more about Model Serving
- Apply LLM on large batches of data with Batch LLM inference
- Build Production-quality Agentic and RAG Apps with Agent Framework and Evaluation
- See Databricks Foundation Model Serving pricing
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.