
TL;DR: We recently released a set of recipes which can accelerate training of a ResNet-50 on ImageNet by up to 7x over standard baselines. In this report we take a deep dive into the technical details of our work and share the insights we gained about optimizing the efficiency of model training over a broad range of compute budgets.
Introduction
ResNets have established themselves as the go-to baseline and testbed for computer vision research (see ResNet Strikes Back or the PyTorch blog). More efficient training recipes can save money and reduce the iteration time in R&D, both of which are a boon to researchers and industry practitioners.
We wanted to push the limits of what can be done with a vanilla ResNet-50 using Composer, our PyTorch library for efficient training. Our goal was to find better training recipes for a vanilla ResNet-50 architecture on ImageNet at the original test resolution of 224 × 224. We are hardly the first to pursue this goal. However, while previous recipes were developed to maximize accuracy, we developed our recipes to maximize efficiency, which is to say achieving a given accuracy using the minimum amount of resources (time and money; see our Methodology blog post for more details about how we quantify efficiency).
Our contributions are as follows:
- We present three different training "recipes" (sets of changes to the training algorithm and hyperparameters) for three different resource training regimes for a vanilla ResNet-50 architecture (with updated anti-aliasing pooling via Blurpool) on ImageNet:
- Mild: < 60 epochs of training, achieves 75- 78.1% top-1 accuracy. This recipe, which forms the basis of our MLPerf submission, achieves 75.9% accuracy in 23.8 minutes on 8x-A100, 17% faster than NVIDIA's MLPerf submission of 28.7 minutes on the same hardware.
- Medium: 60-240 epochs, 78.1-79.5% accuracy. This recipe, for example, can achieve 78.4% accuracy on 8x-A100 in under an hour.
- Hot: ≥ 240 epochs, 79.5-81% accuracy. 80% accuracy on 8x-A100 in 284 minutes, 1.77x faster and 0.2% more accurate than the highly competitive timm A2 baseline.
- We compare our recipes against a suite of baselines that include modern and classic ResNet-50 recipes. We comprehensively benchmark all of our recipes and many of our baselines across six different system configurations.
- We report a number of interesting interactions between different changes to the training algorithm, and between these changes and training duration. The main differentiator between our different training recipes is the amount of regularization—this applies to the number and type of algorithmic changes used, as well as the values of their hyperparameters.
- Our recipes are implemented in Composer, our open-source library for efficient training, and our benchmarking library allows easy replication in a few steps. Our results are in Explorer, our tool for exploring speedups
These recipes show that substantial efficiency gains can be achieved with minimal changes to model architecture. We hope these recipes serve as competitive baselines for future work, and a jumping-off point for subsequent algorithmic efficiency improvements.
Evaluation and Baselines
Hardware and System Information
We evaluated all our recipes and all but two of our seven baselines on six different single-node, 8x accelerator hardware platforms:
- AWS p4d.24xlarge (8x NVIDIA A100 40GB)
- AWS p3.16xlarge (8x NVIDIA V100 16GB)
- GCP a2-highgpu-8g-a100-8 (8x NVIDIA A100 40GB)
- GCP n1-highmem-64-v100-8 (8x NVIDIA V100 16GB)
- Oracle BM.GPU4.8 (8x NVIDIA A100 40GB)
- Our Internal MosaicML Research Cloud (8x NVIDIA A100 80GB).
The software configuration for data collection are as follows:
- MosaicML pytorch_vision docker image 920bb2655d2561adc4249f5fd031b411e7fc293cd9ec014235b520cdd44848a5
- CUDA: 11.3
- PyTorch: 1.11.0+cu113
- Torchvision: 0.12.0+cu113
- ffcv (where relevant): 0.0.3
Replication steps are available in our benchmarking library.
Baseline Recipes
Our baselines consist of seven different ResNet-50 recipes: The "NVIDIA Hparams Baseline" is implemented in Composer, our open-source library for efficient training, and is based on hyperparameters from NVIDIA Deep Learning Examples. It does not use any algorithmic changes that speed up training ("speedup methods"), but it does use the following best practices: a tuned data loading pipeline to maximize throughput; hyperparameter search across batch size and learning rate; step-wise (rather than epoch-wise) learning rate schedule (see our Best Practices blog post for more details); and decoupled weight decay.
We also use the three recipes published in the ResNet Strikes Back (RSB) paper as baselines (recipes timm a1, timm a2, and timm a3). We chose the timm/RSB recipes as baselines for three reasons. First, because they were developed with a similar intent as us: maximize accuracy on a vanilla ResNet-50. Second, because there are three different recipes, each intended for a different training duration/accuracy trade-off: shorter/lower accuracy, medium/midrange accuracy, and longer/higher accuracy. And third, these recipes are extremely competitive.
Another baseline comes from the PyTorch blog. This recipe was developed as an improvement on the timm a1 recipe, and achieves very high performance on ImageNet (80.9%).
We also compare against NVIDIA's MLPerf submission, a specialized recipe written in MXNet that's intended for the MLPerf training benchmark. We did not replicate this recipe, we simply took the published results for 8x NVIDIA A100 80GB.
Our final baseline is a slightly modified version of the recipe used by the authors of FFCV when evaluating their dataloader. This baseline is extremely competitive for low-resource training regimes. We modified this recipe by omitting test-time augmentation, which was part of the original recipe. We did this for the sake of fairness: test time augmentation improves test/validation accuracy without affecting measured training speed. Note that we only ran this baseline on the MosaicML Cloud instance. Also note that two of our three recipes (MosaicML Mild and Medium) use the FFCV dataloader.
Evaluation
All our recipes and baselines are evaluated on the ImageNet-1k validation set. Our recipes, the NVIDIA Hparams Baseline, and the FFCV baseline are evaluated at the end of training. We use the published accuracies for the timm/RSB, PyTorch Blog, and NVIDIA MLPerf submission baselines. In order to evaluate the trade-offs between resource usage (time and money) and training accuracy, we trained each of our recipes, the NVIDIA Hparams Baseline, and the ffcv baseline across a range of training durations (see our Methodology blog post for more details on how we evaluate efficiency). This allows us to determine the optimal resource budget and target accuracy for each recipe. For example, our "Mild" recipe is optimal when training for ≤ 60 epochs, and for achieving accuracies of ≤ 78.1%, but is less efficient than the "Medium" recipe when training for > 60 epochs.
The PyTorch Blog and timm/RSB baselines were trained for 10 epochs, then the time-to-train was extrapolated to the number of epochs required to achieve the published accuracies. When computing time-to-train, the first epoch training time was replaced with the training time for the second epoch. This was done to control for the one-off time required to load data into memory during the first training epoch, which differs depending on the hardware platform and software, and can substantially bias shorter training runs. We also omit validation and checkpointing from training time computations.
Accuracy and time values for Composer Recipes and the NVIDIA Hparams Baseline are the mean across five random seeds. Accuracy and time values for all other baselines are the mean across three random seeds.
A Word on Hyperparameter Optimization
We would also like to note that we did not search for hyperparameters extensively. Our hyperparameter and speedup method selection process was as follows: starting values for speedup method hyperparameters were determined for each method independently when applied to the NVIDIA Hparams Baseline recipe. We then trained different sets of speedup methods for 90 epochs, and selected the set of methods that obtained parity with our NVIDIA Hparams Baseline (76.6%) in the shortest amount of wall-clock time. This became the MosaicML Medium recipe. We then added or removed individual speedup methods trained for different durations, and selected the set of methods that maximized accuracy for a given training duration; MosaicML Mild for short durations, and MosaicML Hot for long durations. We then tuned some algorithm hyperparameters, weight decay, and LR individually at 1-2 increments above and below their starting value, typically in the range of 0.5x - 2x per increment. For example, if weight decay was 0.0005, we might try values of 0.0002, 0.0001, 0.00025, 0.000125. If any of the swept values improved performance, we kept it.
We would like to highlight the simplicity of our hyperparameter optimization, which is in contrast to many other implementations that extensively sweep many parameters to generate a precise "hero run" configuration. Our approach was motivated by usability and generality, and hence there are likely gains that could be obtained by more meticulous hyperparameter search.
Results
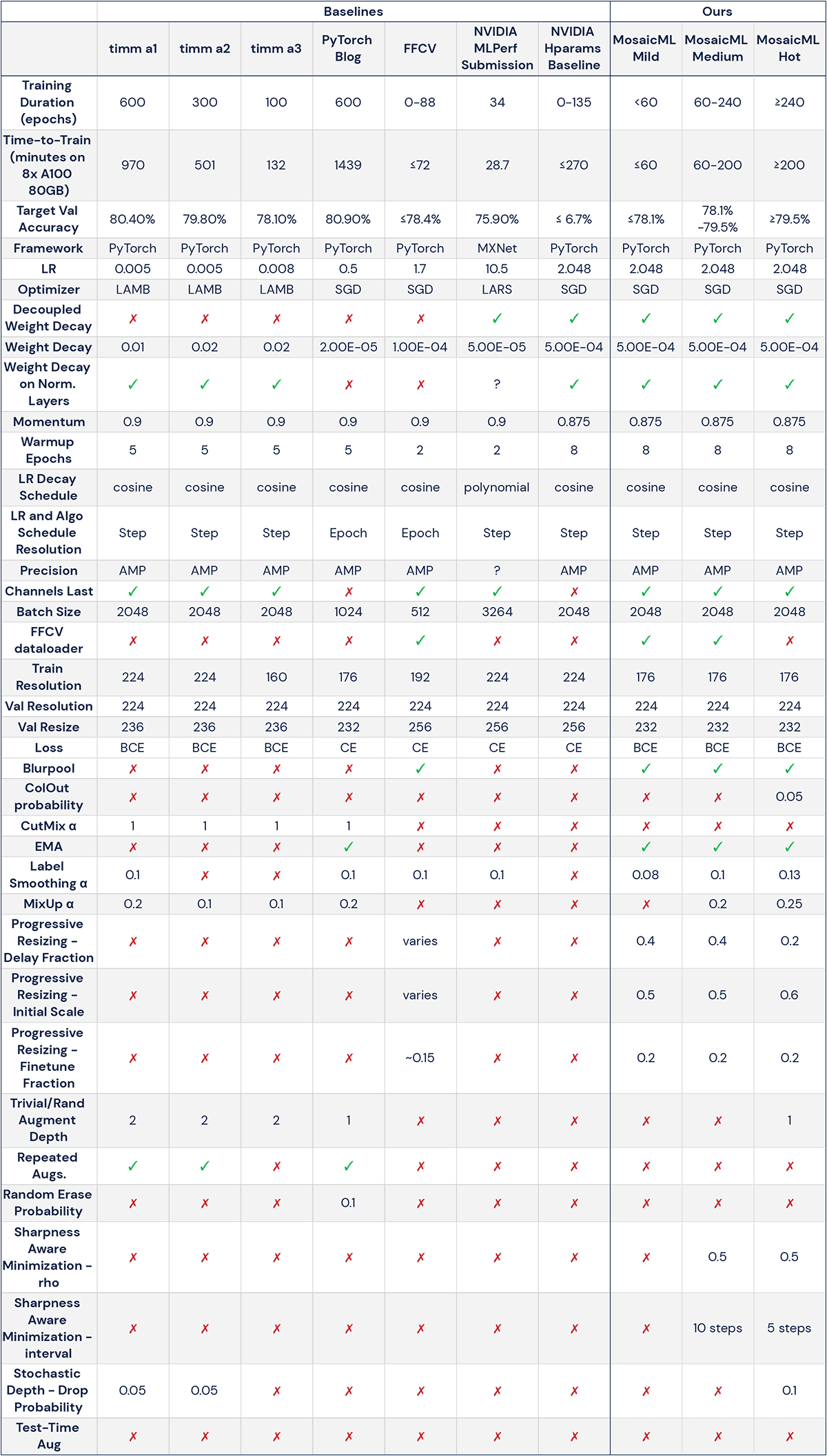
You can see pareto curves for our recipes and baselines in Figure 1, a summary of the recipes in Figure 2, and detailed hyperparameters for our recipes and baselines in Table 1. You can also examine our data yourself (and draw your own conclusions) in Explorer, our tool for examining speedups.
Mild Recipe
We'll start with the MosaicML Mild recipe (Table 1; Figure 1). This is the recipe you use if you want to train your model during your lunch break. This recipe intended for the low-resource regime of the resource/quality trade-off: shorter training durations (0-60 epochs; ≤ 1 hour on 8x A100) and "lower" accuracies (≤ 78.1%; "lower" is in quotes because these numbers are quite competitive). The MosaicML Mild recipe uses the fewest speed-up algorithms out of any of our recipes: BCE loss (as per ResNet Strikes Back and Beyer et al., 2020), BlurPool, EMA, FixRes, Label Smoothing, and Progressive Image Resizing; it also uses the FFCV dataloader and Channels Last memory format (Table 1).
The Mild recipe, which forms the basis of our MLPerf submission, achieves 75.9% accuracy in 23.8 minutes on 8x-A100, 17% faster than NVIDIA's MLPerf submission of 28.7 minutes on the same hardware (Figure 1). We consider this rather noteworthy, given the amount of optimization that goes into MLPerf submissions.
The Mild recipe can also train to 76.6% accuracy in 25.3 minutes on the MosaicML Cloud platform, compared to 180 minutes for the NVIDIA Hparams Baseline recipe—a 7.1x speedup (Table 1). And the Mild recipe remains the pareto-optimal recipe at 78.1% accuracy—equal to that of the timm a3 baseline—in 52.4 minutes on the MosaicML Cloud, a 2.5x speedup over timm a3 (Table 1). Interestingly, the speed-up is even greater on the AWS p4d.24xlarge platform: MosaicML Mild takes 56 minutes, while timm a3 takes 334 minutes, a 3.8x speedup.
The significant slowdown of timm a3 (and consequent speed-up from MosaicML Mild) when moving from MosaicML Cloud to AWS p4d.24xlarge is likely because of the relative reduction in CPU power of the AWS p4d.24xlarge compared to the MosaicML Cloud. The timm a3 recipe uses RandAugment, CutMix, and MixUp, all of which are stochastic image augmentations; image augmentations typically put a heavy load on the CPU, which can bottleneck throughput.
We found that the short training durations (≤ 60 epochs) for which MosaicML Mild is optimal obviate the need for strong regularization. This allows us to avoid CPU-intensive image augmentations, which we examine in more detail in the Ablations and Observations section below. Nevertheless, training the MosaicML Mild recipe has diminishing returns beyond 60 epochs, and the MosaicML Medium recipe becomes the pareto-optimal choice.
Medium Recipe
The MosaicML Medium recipe is what you use if you want your model to finish training after you've had a few meetings. This recipe is optimal for the midrange regime of the resource/quality trade-off: accuracies from 78.1-79.5% and training durations of 60-240 epochs (which roughly corresponds to 1-3 hours on 8x A100, depending on the target accuracy and platform; Figure 1). The MosaicML Medium recipe uses the same speedup methods as the MosaicML Mild recipe (BCE loss, BlurPool, EMA, FixRes, Label Smoothing, and Progressive Resizing, FFCV, and Channels Last), and adds MixUp and Sharpness-Aware Minimization (SAM) (Table 1).
The MosaicML Medium recipe falls in a range not well covered by other baselines—the NVIDIA Hparams Baseline recipe can't achieve more than 76.7%, and the timm a2 recipe achieves 79.8% accuracy, both outside the 78.1-79.5% range of the MosaicML Medium recipe. But if we dig around in the literature, we can find that the FFCV folks can train to 78.4% accuracy in 77.2 minutes on an AWS p4d.24xlarge (8x A100). Note that this is not our modified FFCV baseline that we ran ourselves. This is instead the author-published data that uses test-time augmentation, which, as mentioned earlier, we dropped from our own FFCV baseline because it improves test/validation accuracy without affecting training speed. Nevertheless, the MosaicML Medium recipe achieves 79.4% accuracy in 60.4 minutes on a p4d.24xlarge instance, which is a 1.3x speedup over an arguably unfair baseline.
Hot Recipe
Finally, we arrive at the MosaicML Hot recipe (Figure 1; Table 1). This recipe is what you use if you want to train your model overnight. This recipe is optimal for the high-resource regime of the resource/quality trade-off: accuracies ≥ 79.5% and training durations of ≥ 240 epochs (≥3 hours). This recipe has most of the bells and whistles of the MosaicML Medium recipe, plus RandAugment, Stochastic Depth, and MosaicML's very own in-house speed-up algorithm, ColOut, which stochastically drops rows and columns of pixels from input images.
Notably, the MosaicML Hot recipe omits the FFCV dataloader, which is currently not compatible with RandAugment. We found RandAugment necessary for exceeding 80% accuracy, highlighting the importance of stochastic image augmentations for extended training. We also modified some hyperparameters to increase the amount of regularization (e.g. updating with SAM every 5 steps instead of every 10; increasing MixUp alpha from 0.2 to 0.25), which is important for squeezing the most performance out of longer durations. We discuss some of these practices in more detail in the Ablations and Observations section below.
Our MosaicML Hot recipe achieves 79.9% accuracy in 255 minutes on the MosaicML Cloud platform, while the timm a2 recipe achieves 79.8% in 501 minutes, nearly a 2x speedup. We trained all the way up to 81.0% accuracy, which we were able to do in 880 minutes on the MosaicML Cloud platform. This is both faster and higher accuracy than the two highest accuracy baselines, the timm a1 baseline (80.4% in 970 minutes) and the PyTorch Blog baseline (80.9% in 1439 minutes). If there's a spicier ResNet-50, we haven't seen it.
Ablations & Observations
In this section we describe a number of scientific and technical observations that we feel are of interest to machine learning researchers and practitioners.
Stochastic Image Augmentation is Necessary for Extended Training
We found that validation accuracy always saturated without the use of stochastic image augmentations. Specifically, there was no duration of training or combination of algorithms that allowed us to exceed 79.87% accuracy in any of the 500+ training runs we conducted during recipe development that didn't use RandAugment. This is visible as the saturation of accuracy for the Mosaic Medium recipe in Figure 1. We also note that we use a modified RandAugment implementation that is similar to the timm implementation: the intensity of an augmentation is randomly sampled on a per-image basis, as opposed to being of fixed intensity as originally published. This, combined with our choice to only apply a single augmentation per image (i.e. depth hyperparameter = 1), makes our RandAugment similar to TrivialAugment. We chose to only apply a single RandAugment augmentation per image for two reasons: first, applying two augmentations per image did not improve accuracy, and second, it substantially reduced efficiency by creating a CPU bottleneck, which leads to our next observation.
CPU Power is Critical for Computer Vision Workloads
Stochastic image augmentations are an essential part of modern vision model training recipes, but these sorts of transformations put a significant burden on CPU resources. Table 2 examines the effect of image augmentations on sample throughput. Specifically, we compare a baseline training run to the same run with differing RandAugment depths. The RandAugment depth hyperparameter controls the number of augmentations that are applied to each image—more depth corresponds to more augmentations, which in turn puts a greater load on the CPU. Examining Table 2, we can see that enabling RandAugment with depth = 1 causes an 18% reduction in throughput relative to the baseline, and increasing the depth to 2 causes a further 12% throughput reduction relative to depth = 1.
| Recipe | RandAugment Depth | Throughput (im/sec) |
|---|---|---|
| NVIDIA Hparams Baseline + Channels Last | ✗ | 15422 |
| NVIDIA Hparams Baseline + Channels Last + RandAugment | 1 | 12597 |
| NVIDIA Hparams Baseline + Channels Last + RandAugment | 2 | 11108 |
The importance of CPU power (and system configuration more generally) becomes apparent when examining the change in throughput between the AWS p4d.24xlarge and Oracle BM.GPU4.8 systems (Table 3). Both of these are nominally 8x A100 40GB systems, so one might assume they have similar performance characteristics. And looking at the throughput for only the MosaicML Mild recipe might confirm this assumption: the AWS system has 97% of the throughput of the Oracle system (21582 im/sec and 22242 im/sec, respectively). But examining the throughput for the MosaicML Hot recipe, which is a much more CPU-intensive workload, tells a different story: the AWS system has only 64% of the throughput of the Oracle system (9225 im/sec and 14388 im/sec, respectively). These results demonstrate the importance of benchmarking your workload across available systems: identical GPUs doesn't necessarily mean identical performance.
| Recipe | System | Throughput (im/sec) |
|---|---|---|
| MosaicML Mild | Oracle BM.GPU4.8 | 22242 |
| AWS p4d.24xlarge | 21582 | |
| MosaicML Hot | Oracle BM.GPU4.8 | 14388 |
| AWS p4d.24xlarge | 9225 |
When to Cut CutMix and Nix MixUp
Developing recipes with efficiency in mind requires paying close attention to how algorithms compose with each other and what system resources they use (e.g. CPU vs. memory bandwidth). This led to changes from previous recipes. For example, we found that CutMix, which is an essential ingredient of the timm and PyTorch Blog recipes, was suboptimal in our recipes. Initial experiments replacing MixUp with CutMix while developing our Hot recipe caused not only a substantial drop in accuracy (0.5-0.7 percentage points), but also a training slow-down (0.86x-0.95x; Table 4). It's worth noting that the timm and PyTorch Blog recipes don't apply CutMix and MixUp simultaneously, but rather stochastically alternate between them on a batch-to-batch basis. But given the substantial accuracy drop and modest CPU bottleneck exacerbation we observed from CutMix, we chose to cut CutMix entirely in favor of MixUp.
| Recipe Base | Epochs | CutMix/MixUp | Validation Accuracy | Time-to-Train (Minutes) |
|---|---|---|---|---|
| MosaicML Hot Prototype | 180 | CutMix | 78.85 | 279 |
| MixUp | 79.56 | 242 | ||
| 540 | CutMix | 80.21 | 932 | |
| MixUp | 80.69 | 880 |
Despite MixUp's importance for long training runs, we found it was suboptimal at very short training durations, hence its exclusion from our Mild recipe. Specifically, we found when developing our Mild recipe that Label Smoothing and MixUp performed worse when combined together than when one was added to the recipe without the other (Table 5). A prototype MosaicML Mild recipe with MixUp + Label Smoothing had lower accuracy (75.91%) and throughput (18043 im/sec) than with either MixUp (76.04%, 18527 im/sec) or Label Smoothing (76.33%, 19086) alone. Given the superior accuracy and throughput of Label Smoothing over MixUp, we opted to nix MixUp.
| Recipe Base | MixUp/LabelSmoothing | Epochs | Validation Accuracy | Throughput (im/sec) |
|---|---|---|---|---|
| MosaicML Mild Prototype | MixUp + Label Smoothing | 30 | 75.91 | 18043 |
| MixUp | 30 | 76.04 | 18527 | |
| Label Smoothing | 30 | 76.033 | 19086 |
Beyer et al. found that they could ameliorate ResNet-50 overfitting on ImageNet at training durations of 300-1200 epochs by using what they term "aggressive" MixUp, in which the "mixing" hyperparameter is set to 1 (see our Method Card for more information on MixUp). We tried this as part of our MosaicML Hot recipe development and found that it did not work (Table 6): using aggressive MixUp as part of the MosaicML Hot recipe reduced accuracy by 0.8-1.1% compared to using a less extreme value for the mixing hyperparameter (0.25). It's possible that aggressive MixUp doesn't compose well with other algorithms, or work as well in the higher accuracy regime of our recipes—Beyer et al.'s ResNet-50 performance didn't exceed ~77%. Beyer et al. also found that aggressive MixUp was less effective at preventing overfitting in models trained with SGD compared to models with ADAM, and our recipes all use SGD. Regardless, the dream remains of finding a single cure-all hyperparameter value for overfitting.
| Recipe | MixUp mixing Hparam (α) | Epochs | Validation Accuracy | Time-to-Train (Minutes) |
|---|---|---|---|---|
| MosaicML Hot | 0.25 | 450 | 80.78 | 573 |
| 1.0 ("aggressive") | 450 | 79.69 | 543 | |
| 0.25 | 810 | 81.03 | 980 | |
| 1.0 ("aggressive") | 810 | 80.22 | 1008 |
Play it Again, SAM
Sharpness-Aware Minimization is a technique that provides an accuracy improvement proportional to training duration—longer training runs (as measured by number of training epochs) benefit more from SAM. It's also computationally costly: it computes two sets of gradients, which roughly halves throughput (though recent work from Liu et al. and Du et al. may mitigate this slowdown). For these two reasons we don't use SAM in our Mild recipe, and the latter reason is why we don't use SAM on every step in our Medium and Hot recipes (Table 1). However, because SAM yields greater benefits for longer training regimes, we hypothesized that more frequent SAM updates would be more beneficial for the extended training durations of the Hot recipe. Indeed, when training the Hot recipe for 180 epochs, using SAM once every five steps yields no accuracy improvement—and slows training—whereas by 450 epochs, more frequent SAM updates provide a tangible benefit (Table 7). Thus the pareto optimal choice of SAM update frequency is proportional to training duration.
| Recipe | SAM Interval | Epochs | Validation Accuracy | Time-to-Train (Minutes) |
|---|---|---|---|---|
| MosaicML Hot | 5 | 180 | 79.86 | 254 |
| 10 | 180 | 79.86 | 237 | |
| 5 | 450 | 80.78 | 573 | |
| 10 | 450 | 80.69 | 532 |
PyTorch Binary Cross Entropy Doesn't Work Out-of-the-Box
Like Wightman et al.'s timm recipes, we found binary cross-entropy (bce) loss to be an essential component of all our recipes. Interestingly, we found that PyTorch's built-in bce loss functions (torch.nn.BCELoss and torch.nn.BCEWithLogitsLoss) don't work well out-of-the-box. The default reduction value ("mean") averages the loss over all n samples in a batch and 1000 classes in ImageNet, resulting in infinitesimal loss values that don't allow learning with learning rate values in the traditional range. Our solution was to set reduction="sum" and then divide the loss by the number of samples in the batch.
We also found it necessary to use Kornblith et al.'s practice of initializing the logit biases to -log(n_classes) such that the initial outputs are roughly equal to 1/n_classes. Using a default initialization for the logit biases is worse than using traditional cross-entropy loss, and causes a ~0.8% accuracy drop compared to using the -log(n_classes) initialization (Table 8).
| Recipe | Epochs | Loss | Validation Accuracy |
|---|---|---|---|
| MosaicML Medium Prototype | 36 | BCE (default init) | 75.91 |
| 36 | Cross-Entropy | 76.29 | |
| 36 | BCE (-log(n_classes) init) | 76.75 | |
| 90 | BCE (default init) | 78.34 | |
| 90 | Cross-Entropy | 78.60 | |
| 90 | BCE (-log(n_classes) init) | 79.1 |
Composer's BCE loss implements the appropriate loss scaling, and the -log(n_classes) can be enabled with a single hyperparameter.
Conclusions
We developed the Mild, Medium, and Hot ResNet-50 training recipes for low-, medium-, and high-resource training regimes, respectively. These training recipes improve upon even the most competitive ResNet-50 training recipe baselines, garnering speedups of up to 7x. We found that the main differentiator between our Mild, Medium, and Hot recipes is the amount of regularization—this applies both to the number of algorithms used as well as the values of their hyperparameters. The optimal composition of training algorithms and hyperparameters was strongly dependent on the duration of training and system configuration. You can find our results in Explorer, our tool for exploring speedups. Our recipes are fully replicable using Composer, our open-source library for efficient training, and our benchmarking library.
While we're satisfied with the range of recipes and hardware platforms we evaluate, there's still so much more that could be done. Perhaps we overlooked your favorite baseline? Download Composer and benchmark against us! Maybe you have a homebrew wafer-scale system that Composer could bring speedups to? Profile our recipes on your own hardware! Is there a speed-up method that you think could turn the MosaicML Hot recipe into Composer FaceMelter? Add it to Composer and give it a spin! And please, be a part of our community by engaging with us on Twitter, joining our Slack, or just giving us a star on Github.