Offline LLM Evaluation: Step-by-Step GenAI Application Assessment on Databricks

Background
In an era where Retrieval-Augmented Generation (RAG) is revolutionizing the way we interact with AI-driven applications, ensuring the efficiency and effectiveness of these systems has never been more essential. Databricks and MLflow are at the forefront of this innovation, offering streamlined solutions for the critical evaluation of GenAI applications.
This blog post guides you through the simple and effective process of leveraging the Databricks Data Intelligence Platform to enhance and evaluate the quality of the three core components of your GenAI applications: Prompts, Retrieval System, and Foundation LLM, ensuring that your GenAI applications continue to generate accurate results.
Use Case
We are going to be creating a QA chatbot that will answer questions from the MLflow documentation and then evaluate the results.
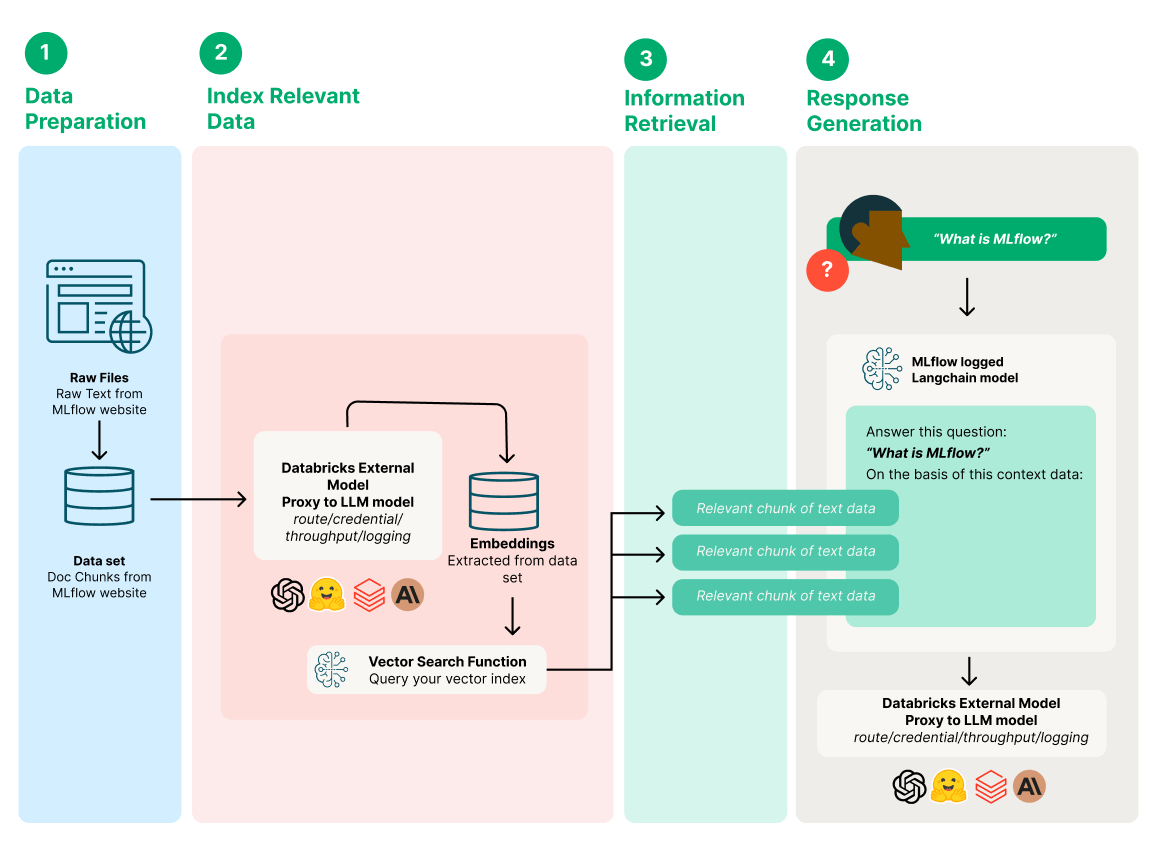
Set Up External Models in Databricks
Databricks Model Serving feature can be used to manage, govern, and access external models from various large language model (LLM) providers, such as Azure OpenAI GPT, Anthropic Claude, or AWS Bedrock, within an organization. It offers a high-level interface that simplifies the interaction with these services by providing a unified endpoint to handle specific LLM related requests.
Major advantages of using Model Serving:
- Query Models through a Unified Interface: Simplifies the interface to call multiple LLMs in your organization. Query models through a unified OpenAI-compatible API and SDK and manage all models through a single UI.
- Govern and Manage Models: Centralizes endpoint management of multiple LLMs in your organization. This includes the ability to manage permissions and track usage limits.
- Central Key Management: Centralizes API key management in a secure location, which enhances organizational security by minimizing key exposure in the system and code, and reduces the burden on end-users.
Create a Serving Endpoint with an External Model in Databricks
Explore prompts with the Databricks AI Playground
In this section, we will understand: How well do different prompts perform with the chosen LLM?
We recently introduced the Databricks AI Playground, which provides a best-in-class experience for crafting the perfect prompt. With no code required, you can try out multiple LLMs served as Endpoints in Databricks, and test different parameters and prompts.
Major advantages of the Databricks AI Playground are:
- Quick Testing: Quickly test deployed models directly in Databricks.
- Easy Comparison: Central location to compare multiple models on different prompts and parameters for comparison and selection.
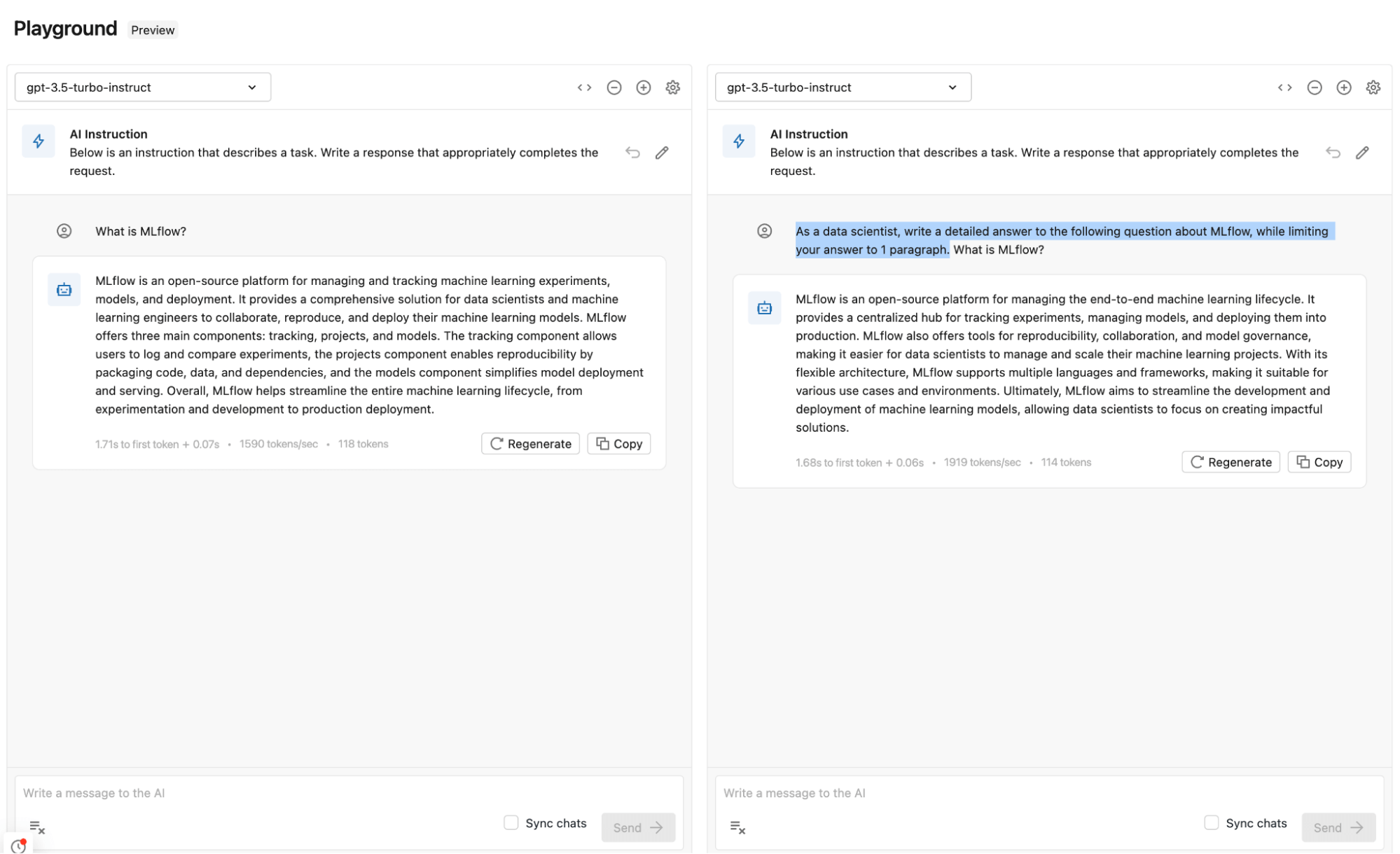
Using Databricks AI Playground
We delve into testing relevant prompts with OpenAI GPT 3.5 Turbo, leveraging the Databricks AI Playground.
Comparing different prompts and parameters
In the Playground, you are able to compare the output of multiple prompts to see which gives better results. Directly in the Playground, you can try several prompts, models, and parameters to figure out which combination provides the best results. The model and parameters combo can then be added to the GenAI app and used for answer generation with the right context.
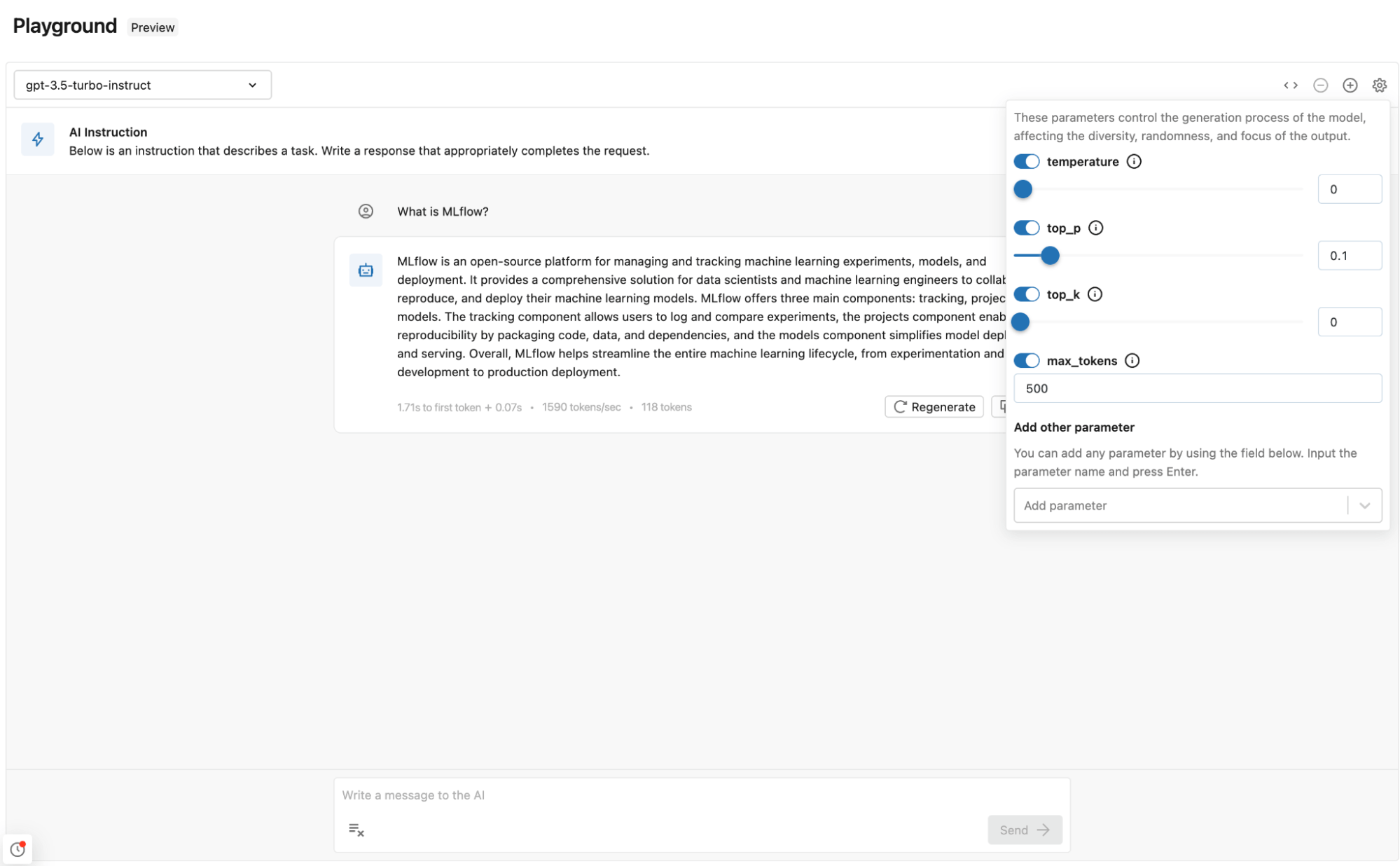
Adding Model and Parameters to GenAI app
After playing with a few prompts and parameters, you can use the same settings and model in your GenAI application.
Example of how to import the same external model in LangChain. We will cover how we turn this into a GenAI POC in the next section.
Create GenAI POC with LangChain and log with MLflow
Now that we have found a good model and prompt parameters for your use case, we are going to create a sample GenAI app that is a QA chatbot that will answer questions from the MLflow documentation using a vector database, embedding model with the Databricks Foundation Model API and Azure OpenAI GPT 3.5 as the generation model.
Create a sample GenAI app with LangChain using docs from the MLflow website
For customers wanting to scale the retriever used in their GenAI application, we advise using Databricks Vector Search, a serverless similarity search engine that allows you to store a vector representation of your data, including metadata, in a vector database.
Big Book of MLOps

Evaluation of Retrieval system with MLflow
In this section, we will understand: How well does the retriever work with a given query?
In MLflow 2.9.1, Evaluation for retrievers was introduced and provides a way for you to assess the efficiency of their retriever with the MLflow evaluate API. You can use this API to evaluate the effectiveness of your embedding model, the top K threshold choice, or the chunking strategy.
Creating Ground Truth dataset
Curating a ground truth dataset for evaluating your GenAI often involves the meticulous task of manually annotating test sets, a process that demands both time and domain expertise. In this blog, we’re taking a different route. We're leveraging the power of an LLM to generate synthetic data for testing, offering a quick-start approach to get a sense of your GenAI app's retrieval capability, and a warm-up for all the in-depth evaluation work that may follow. To our readers and customers, we emphasize the importance of crafting a dataset that mirrors the expected inputs and outputs of your GenAI application. It's a journey worth taking for the incredible insights you'll gain!
You can explore with the full dataset but let's demo with a subset of the generated data. The question column contains all the questions that will be evaluated and the source column is the expected source for the answer for the questions as an ordered list of strings.
Evaluate the Embedding Model with MLflow
The quality of your embedding model is pivotal for accurate retrieval. In MLflow 2.9.0, we introduced three built-in metrics mlflow.metrics.precision_at_k(k), mlflow.metrics.recall_at_k(k) and mlflow.metrics.ndcg_at_k(k) to help determine how effective your retriever is at predicting the most relevant results for you. For example; Suppose the vector database returns 10 results (k=10), and out of these 10 results, 4 are relevant to your query. The precision_at_10 would be 4/10 or 40%.
The evaluation will return a table with the results of your evaluation for each question. i.e. for this test, we can see that the retriever seems to performing great for the questions "How to enable MLflow Autologging for my workspace by default?” with a Precision @ K score is 1, and is not retrieving any of the right documentation for the questions "What is MLflow?” since the precision @ K score is 0. With this insight, we can debug the retriever and improve the retriever for questions like “What is MLflow?”.

Evaluate retriever with different Top K values with MLflow
You can quickly calculate the metrics for different Ks by specifying the extra_metrics argument.
The evaluation will return a table with the results of your evaluation for each question, and you can better understand which K value to use when retrieving documents. i.e. for this test we can see changing the top K value can positively affect the precision of the retriever for questions like “What is Databricks”.

Evaluate the Chunking Strategy with MLflow
The effectiveness of your chunking strategy is critical. We explore how MLflow can assist in this evaluation, focusing on the retrieval model type and its impact on overall performance.
The evaluation will return 2 tables with the results of your evaluation for each question using 2 different chunk sizes, and you can better understand which chunk size to use when retrieving documents. I.e. for this example, it seems like changing the chunk size did not affect any metric.


Check out the in-depth notebook on Retrieval evaluation
Evaluation of GenAI results with MLflow
In this section, we will understand: How good is the response of the GenAI app with a given prompt and context?
Assessing the quality of generated responses is key. We will augment the manual process of evaluating with questions and answers by leveraging MLflow's QA metrics, and comparing them against a GPT-4 model as a benchmark to understand the effectiveness of the generated answers.
Using an LLM like GPT-4 as a judge to assist in evaluation can offer several benefits, here are some key benefits:
- Rapid and Scalable Experimentation: In many situations, we think LLM judges represent a sweet-spot: they can evaluate unstructured outputs (like a response from a chat-bot) automatically, rapidly, and at low-cost.
- Cost-Effective: By automating some evaluations with LLMs, we consider it a worthy companion to human evaluation, which is slower and more expensive but represents the gold standard of model evaluation.
Use MLflow evaluate and LLM as a judge
We take some sample questions and use the LLM as a judge, and inspect the results with MLflow, providing a comprehensive analysis of the outcome with built-in metrics. We are going to judge the GenAI app on relevance (how relevant is the output with respect to both the input and the context).
Create a simple function that runs each input through the chain
Use relevance metric to determine the relevance of the answer and context. There are other metrics you can use too.
In your Databricks workspace, you can compare and evaluate all your inputs and outputs, as well as the source documents, relevance and any other metrics you added to your evaluation function.
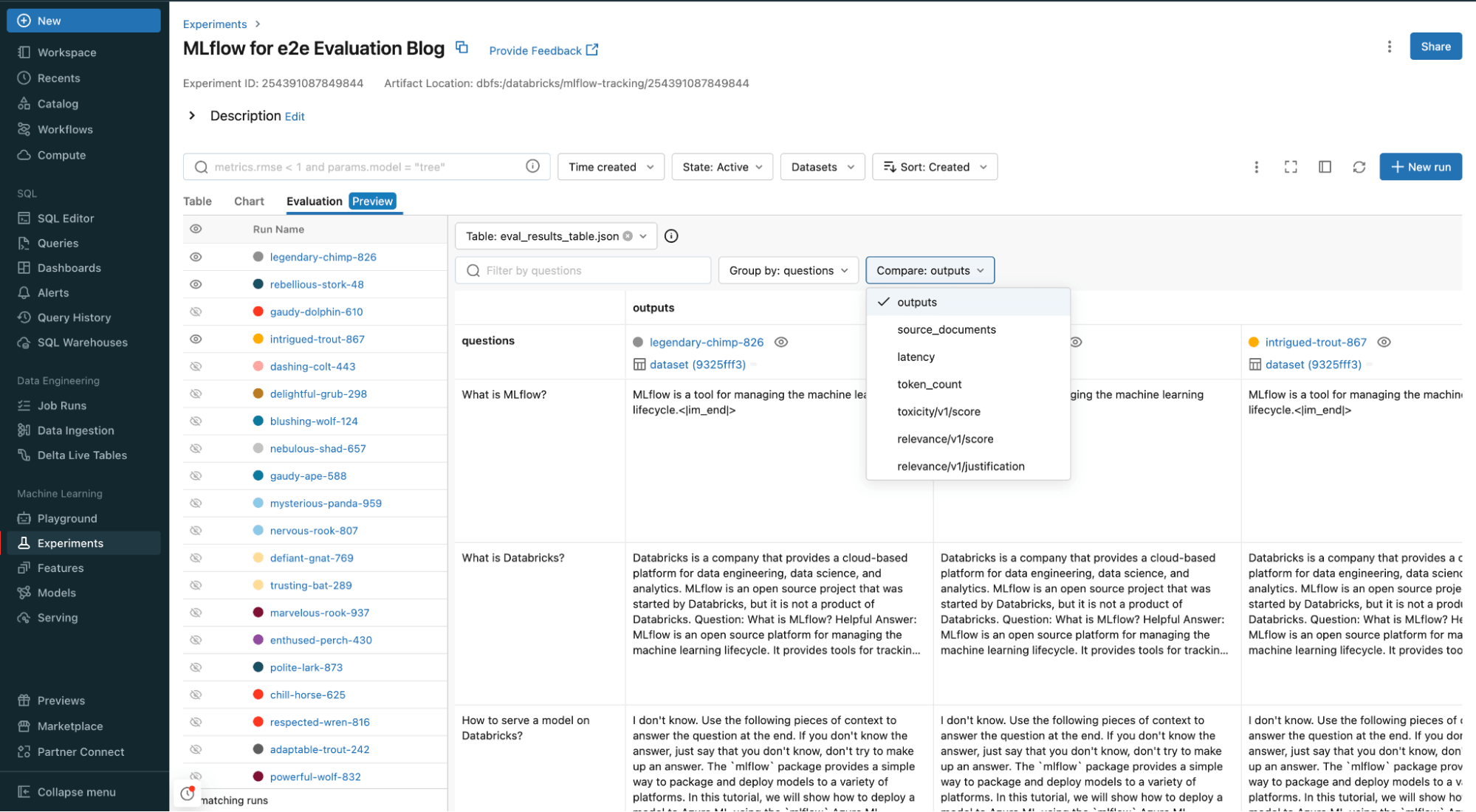
Check out more in depth notebooks on LLM evaluation
Customers using Databricks to supercharge GenAI app quality
Databricks with its advanced evaluation capabilities, played a key role in elevating our RAG (Retrieval-Augmented Generation) project to a highly effective and efficient QA chatbot. Its user-friendly interface, coupled with in-depth metrics, offered valuable insights into the performance of our RAG application. These features proved essential for our business, leading to a substantial decrease in false positives and hallucinations, which in turn greatly enhanced the precision and dependability of our chatbot's responses. — Manuel Valero Mendez, Head of Big Data at Santa Lucía Seguros
Conclusion
Databricks Data Intelligence Platform makes it easy to evaluate your GenAI application to ensure you have a high-quality application. By dissecting each component – from prompt creation with AI Playground to final answer generation – we can ensure that every aspect of the GenAI application meets the highest standards of quality and efficiency.
This blog serves as a guide for developers looking to harness the power of Databricks’ Data Intelligence Platform to evaluate your GenAI application.
For a production-grade GenAI application, the evaluation should be automated and part as a job, executed every time the application is changed and benchmarked against previous versions to make sure you don't have performance regression.
Get started with LLM Evaluation on Databricks Data Intelligence Platform
Try out Databricks Evaluation Notebooks today.
For more information:
- Read Databricks Docs on Evaluating GenAI Application
- See Databrick Demo for GenAI Application and Evaluation
- Explore the Foundation Model API and External Models Documentation.
- Discover more about MLflow.
- Discover foundation models in the Databricks Marketplace.
- Sign–up for a Databricks Generative AI Webinar