Santalucía Seguros: Enterprise-level RAG for Enhanced Customer Service and Agent Productivity

In the insurance sector, customers demand personalized, fast, and efficient service that addresses their needs. Meanwhile, insurance agents must access a large amount of documentation from multiple locations and in different formats. To improve customer service and agent productivity, Santalucía Seguros, a Spanish company that has supported families for over 100 years, implemented a GenAI-based Virtual Assistant (VA) capable of supporting agents’ queries about products, coverages, procedures and more.
Watch the video: how Santalucía Seguros revolutionizes customer service with an AI chatbot
The VA is accessed within Microsoft Teams and is able to answer agent questions in natural language on any mobile device, tablet, or computer, in real-time, with 24/7 availability. This access makes insurance agents’ daily work much easier. For example, whenever a customer asks about coverage they can get an answer in seconds. The speed of the response not only positively impacts customer satisfaction, it accelerates the sale of products by providing immediate and accurate answers.
The solution architecture is based on a Retrieval Augmented Generation (RAG) framework running on Santalucía’s Advanced Analytics Platform that is powered by Databricks and Microsoft Azure, offering flexibility, privacy, security, and scalability. This architecture enables the continuous ingestion of up-to-date documentation into embedding-based vector stores, which provide the ability to index information for rapid search and retrieval. The RAG system is set up as a pyfunc model in MLflow, an open source LLMOps solution from Databricks. We also used Databricks Mosaic AI Model Serving endpoints to host all LLM models for queries.
It can be challenging to support the continuous delivery of new releases while maintaining good LLMOps practices and response quality, as it requires the seamless integration of newly ingested documents into the RAG system. Ensuring the quality of responses is critical for our business, and we cannot afford to modify any part of the solution’s code without guaranteeing that it will not negatively impact the quality of previously delivered releases. This requires thorough testing and validation processes to keep our answers accurate and reliable. We relied on the RAG tools available in the Databricks Data Intelligence Platform to ensure our releases always have the latest data, with governance and guardrails around their output.
Next, we will delve into the critical elements essential for the successful development of a GenAI-based Virtual Assistant that is high-quality, scalable, and sustainable. These elements have made it easier to develop, deploy, evaluate, monitor, and deliver the solution. Here are two of the most important ones.
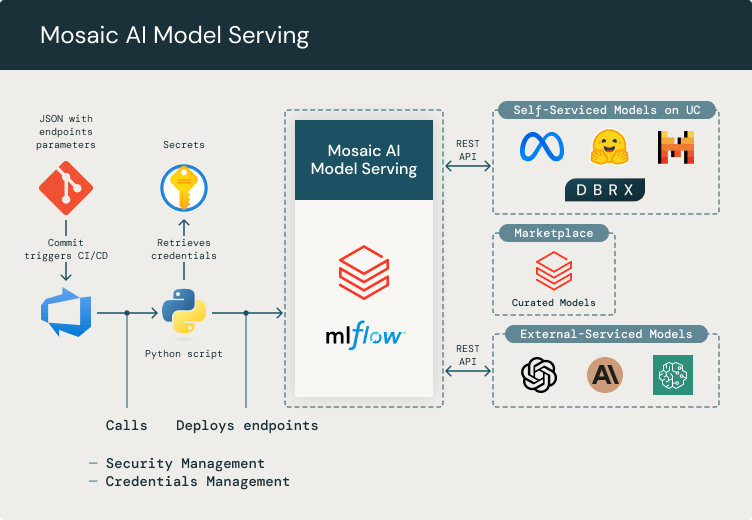
Mosaic AI Model Serving
Mosaic AI Model Serving makes it easy to integrate external LLMs, such as GPT-4 or other models available in the Databricks Marketplace, into our platform. Mosaic AI Model Serving manages the configuration, credentials, and permissions of these third-party models, allowing access to them through REST API. This ensures that any application or service will use it in a unified way, and provides an abstract layer that makes it easy for development teams to add new models, eliminating the need for third-party API integrations. Model Serving is crucial for us as it enables the management of token consumption, credentials, and security access. We have built a straightforward method for creating and deploying new endpoints upon request, using a simple git repository with a CI/CD process that deploys the endpoint in the appropriate Databricks workspace.
Developers can interact with LLM models (for example, external services like Azure OpenAI API or any other third-party model, self-hosted that can be deployed from the Databricks Marketplace) indirectly through a Databricks endpoint. We deploy new models on our platform through a git repository, where we define a configuration JSON to parameterize credentials and endpoints. We keep these credentials safe in an Azure Key vault and use MLflow to deploy models in Databricks with CI/CD pipelines for model serving.
LLM as a Judge for Evaluation of New Releases
Evaluating the quality of the RAG responses is critical for Santalucía. Each time we ingest new documents into the VA, we must review the assistant's performance before releasing the updated version. This means we cannot wait for users to evaluate the quality of the responses; instead, the system itself must be able to assess the quality before scaling to production.
Our proposed solution uses a high-capacity LLM as a judge within the CI/CD pipeline. To track how good the VA’s answers are, we must first create a ground truth set of questions that have been validated by professionals. For example, if we want to include a new product’s coverages in the VA, we must get the documentation and (either manually or aided by a LLM) develop a set of questions regarding the documentation and the expected answer to each question. Here, it is important to realize that with each release, the set of questions/answers in the ground truth increases model robustness.
The LLM-as-a-judge consists of natural-language-based criteria for measuring accuracy, relevance, and coherence between expected answers and those provided by the VA. Thus, for each question/answer pair in the ground truth, the judge oversees scoring the quality. For example, we might design a criterion as follows:
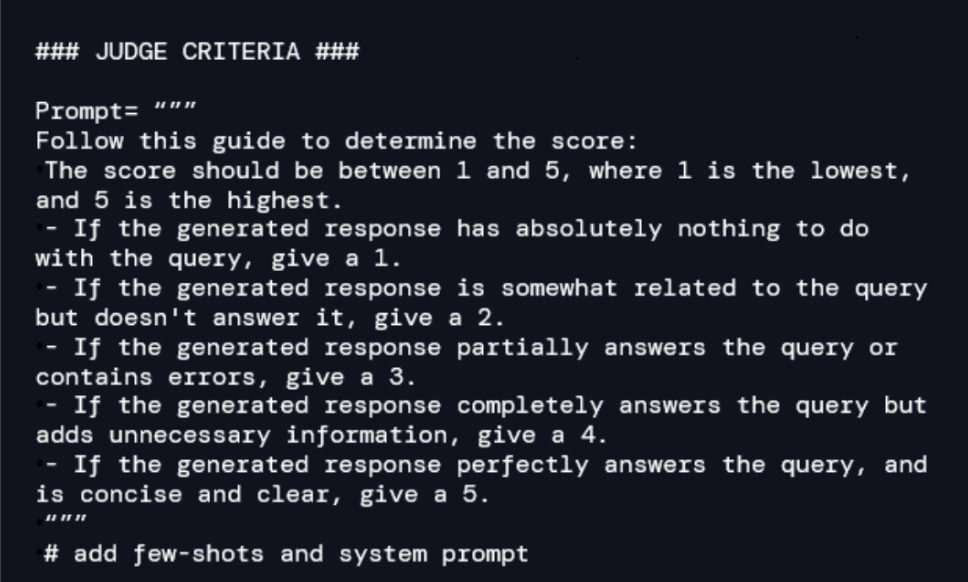
We establish an evaluation process within the CI/CD pipeline. The VA answers each question using the ground truth, and the judge assigns a score by comparing the expected answer with the one provided by the VA. Here is an example with two questions:
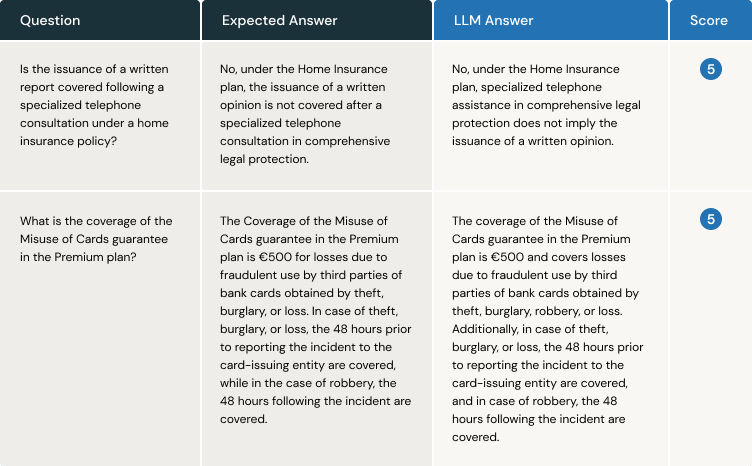
The first advantage is obvious: we don't need to wait for the user to inform us that the VA is malfunctioning in retrieving information and generating responses. Additionally, we often need to make minor adjustments to some parts of the code, such as a prompt. An evaluation system like this, based on ground truth and LLM-as-a-judge, allows us to detect whether any changes made to a prompt to enhance the user experience are impacting the quality of responses from previously delivered releases.
Conclusion
Santa Lucia has implemented a strong and adaptable architecture using a RAG framework for a GenAI-based Virtual Assistant. Our solution combines external LLM models with our Advanced Analytics Platform, ensuring privacy, security and control of the data and models. The speed and quality of the responses are critical for business and customer satisfaction. By using Mosaic AI Model Serving and LLM-as-a-judge, the Virtual Assistant has exceeded the expectations of users while demonstrating best practices for LLM deployment. We are committed to improving our solution further in terms of response quality, performance, and cost and look forward to more collaboration with the Databricks Mosaic AI team.
This blog post was jointly authored by Eduardo Fernández Carrión (Santalucía Seguros), Manuel Valero Méndez (Santalucía Seguros) and Luis Herrera (Databricks).
Never miss a Databricks post
What's next?

Data Science and ML
June 12, 2024/8 min read
Mosaic AI: Build and Deploy Production-quality AI Agent Systems

Data Science and ML
October 1, 2024/10 min read