Solution Accelerator: LLMs for Manufacturing

Published: September 21, 2023
by Will Block, Ramdas Murali, Nicole Lu and Bala Amavasai

Since the publication of the seminal paper on transformers by Vaswani et. al. from Google, large language models (LLMs) have come to dominate the field of generative AI. Without a doubt, the advent of OpenAI's ChatGPT has brought much needed publicity and has led to the rise of interest in the use of LLMs, both for personal use and those that fulfill the needs of the enterprise. In recent months, Google has released Bard and Meta with their Llama 2 models demonstrating intense competition by large technology companies.
The manufacturing and energy industries are challenged to deliver higher productivity compounded by rising operational costs. Enterprises that are data-forward are investing in AI, and more recently in LLMs. In essence, data-forward enterprises are unlocking huge value from these investments.
Databricks believes in the democratization of AI technologies. We believe that every enterprise should be given the ability to train their LLMs, and they should own their data and their models. Within the manufacturing and energy industries, many processes are proprietary and these processes are critical to maintaining a lead, or improving operating margins in the face of severe competition. Secret sauces are protected by withholding them as trade secrets, rather than being made available publicly through patents or publications. Many of the publicly available LLMs do not conform to this basic requirement which requires the surrender of knowledge.
In terms of use cases, the question that often arises in this industry is how to augment the current workforce without flooding them with more apps and more data. Therein lies the challenge of building and delivering more AI-powered apps to the workforce. However, with the rise of generative AI and LLMs, we believe that these LLM-powered apps can reduce the dependency of multiple apps, and consolidate knowledge-augmenting capabilities in fewer apps.
Several use cases in the industry could benefit from LLMs. These include, and are not limited to:
- Augmenting customer support agents. Customer support agents want to be able to query what open/unresolved issues exist for the customer in question and provide an AI-guided script to assist the customer.
- Capturing and disseminating domain knowledge through interactive training. The industry is dominated by deep know-how that is often described as "tribal" knowledge. With the aging workforce comes the challenge of capturing this domain knowledge permanently. LLMs could act as reservoirs of knowledge that can then be easily disseminated for training.
- Augmenting the diagnostics capability of field service engineers. Field service engineers are often challenged with accessing tons of documents that are intertwined. Having an LLM to reduce the time taken to diagnose the problem will inadvertently increase efficiencies.
In this solution accelerator, we focus on item (3) above, which is the use case on augmenting field service engineers with a knowledge base in the form of an interactive context-aware Q/A session. The challenge that manufacturers face is how to build and incorporate data from proprietary documents into LLMs. Training LLMs from scratch is a very costly exercise, costing hundreds of thousands if not millions of dollars.
Instead, enterprises can tap into pre-trained foundational LLM models (like MPT-7B and MPT-30B from MosaicML) and augment and fine-tune these models with their proprietary data. This brings down the costs to tens, if not hundreds of dollars, effectively a 10000x cost saving. The full path to fine-tuning is shown from left to right, and the path to Q/A querying is shown from right to left in Figure 1 below.
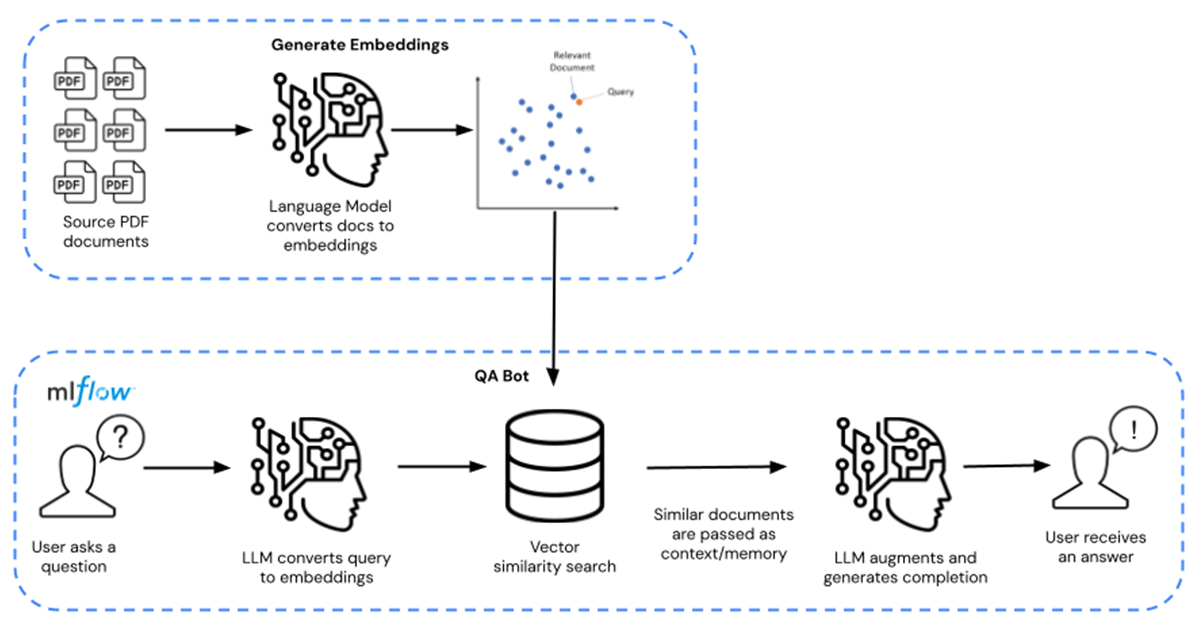
In this solution accelerator, the LLM is augmented on publicly available chemical factsheets that are distributed in the form of PDF documents. This is replaceable with any proprietary data of your choice. The fact sheets are transformed into embeddings and are used as a retriever for the model. Langchain was then used to compile the model, which is then hosted on Databricks MLflow. The deployment takes the form of a Databricks Model Serving endpoint with GPU inference capability.
Augment your enterprise today by downloading these assets here. Reach out to your Databricks representative to better understand why Databricks is the platform of choice to build and deliver LLMs.
Explore the solution accelerator here.
Never miss a Databricks post
What's next?

Manufacturing
October 1, 2024/5 min read
From Generalists to Specialists: The Evolution of AI Systems toward Compound AI

Product
November 27, 2024/6 min read