Managed MLflow
Natively manage AI models, agents and apps with MLflow in Databricks


What is Managed MLflow?
Managed MLflow on Databricks delivers state-of-the-art experiment tracking, observability, performance evaluation, and model management for the full spectrum of machine learning and AI, from classical models and deep learning to generative AI applications and agents, all natively within the Databricks Data Intelligence Platform. Managed MLflow is built on the flexible foundation of open-source MLflow and fortified with enterprise-grade reliability, security, and scalability. This empowers enterprises to confidently build high quality models and agents using their preferred tools across the entire AI & ML ecosystem, all while ensuring their AI and data assets are governed and protected.
Benefits
Unified ML and Gen AI lifecycle
Managed MLflow unifies classical ML, deep learning, and GenAI development in a single, streamlined workflow. From experiment tracking to deployment, it delivers consistent versioning, prompt management, and packaging across models and agents—eliminating the need to stitch together separate tools.
Flexible and open-source
Avoid vendor lock-in and maintain full flexibility across your stack. Built on open-source MLflow — with over 800 community contributors, 25+ million monthly package downloads, and trusted by more than 5,000 organizations worldwide — Managed MLflow seamlessly supports your choice of frameworks, languages, and tools. You get all the freedom and reliability of open source — plus the simplicity of a fully managed experience.
Enterprise-grade observability and governance
Deeply integrated within the Databricks platform, Managed MLflow provides full traceability, real-time monitoring, and unified governance across your AI workflows. With Unity Catalog, you can automatically enforce access controls, track lineage, and ensure compliance across your models, data and agents.
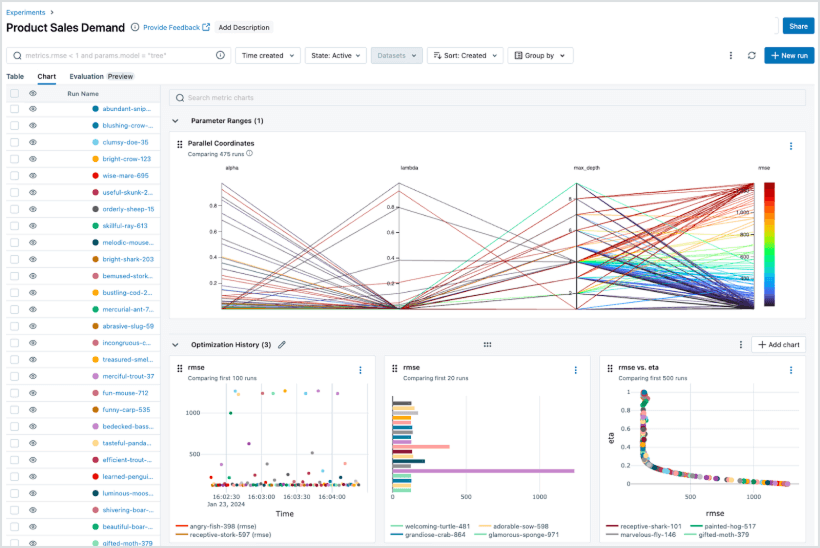
Powerful performance analytics
Analyze, compare, and visualize performance across dev, staging, and prod—all from a single place. With MLflow’s unified data model and integration with Databricks AI/BI and SQL, data scientists can uncover trends, identify regressions, and drive business impact using the same platform they use to build and deploy.
New GenAI features
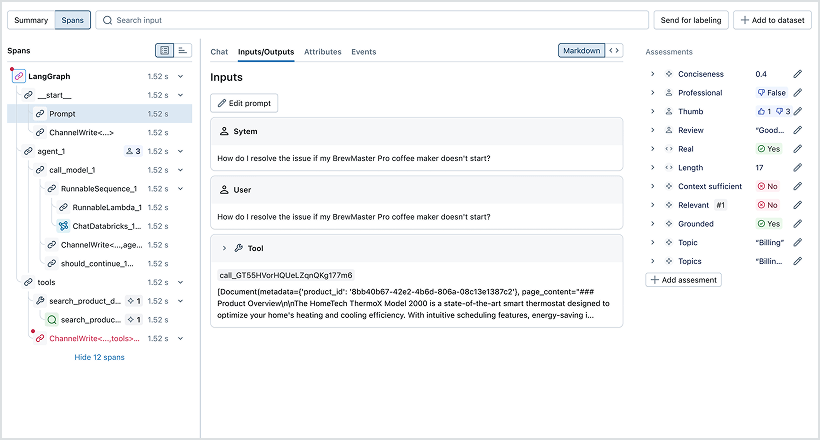
Tracing
Capture inputs, outputs, and step-by-step execution—including prompts, retrievals, and tool calls—with MLflow’s open-source, OpenTelemetry-compatible tracing. Automatically instrument popular GenAI libraries or ingest traces directly. Debug and iterate faster with interactive timeline views, side-by-side comparisons, and zero vendor lock-in.
Generative AI Evaluation
Evaluate GenAI agents using LLM-as-a-judge and human feedback—right in the MLflow UI. Build datasets from production traces, compare outputs across versions, and assess quality with prebuilt or custom metrics like hallucination or relevance. Incorporate expert feedback via web UIs or app APIs to align with human judgment and continuously improve results.
Prompt Registry and Agent Versioning
Version prompts, agents, and application code in one place with MLflow. Link traces, evaluations, and performance data to specific versions for full lifecycle lineage. Reuse and compare prompts across workflows, manage agent versions with associated metrics and parameters, and integrate with Git and CI/CD to accelerate governed iteration.
Generative AI Monitoring and Alerting
Monitor GenAI quality in real time with MLflow’s dashboards, trace explorers, and automated alerts. Track issues like PII leakage, latency spikes, or unhelpful responses using LLM-judge evaluations and custom metrics. Configure online evaluations and act quickly—before users are affected.
Core features
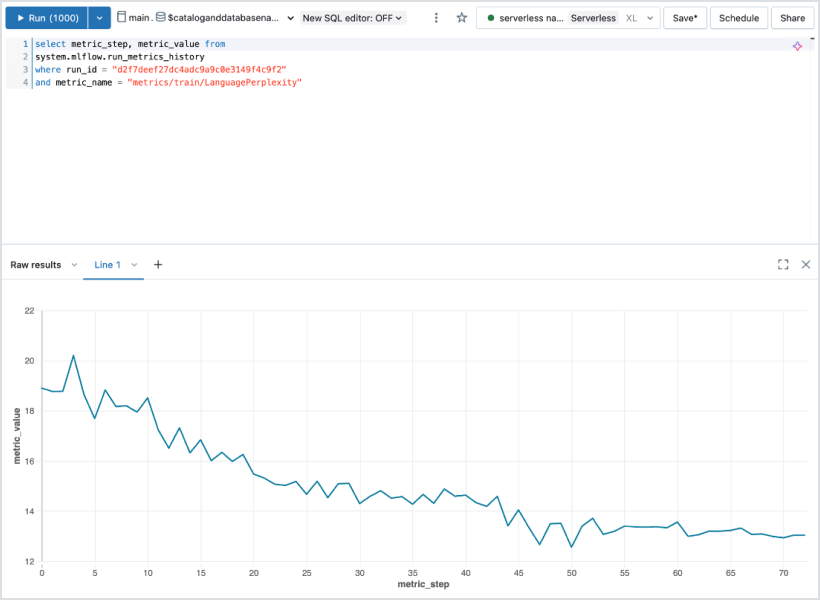
Experiment Tracking
Automatically track parameters, metrics, artifacts, and models from any ML or deep learning framework. MLflow gives you a complete audit trail and supports deep comparisons across architectures, checkpoints, and training workflows—at scale.
Model evaluation for ML and DL
Automatically log built-in and custom metrics for tasks like classification or regression. Compare results against baselines, log artifacts like ROC curves, and validate models on new datasets—before they reach production.
Effortless Model Management & Governance
Discover, share, and manage models centrally with the MLflow Model Registry—integrated with Unity Catalog for end-to-end governance. Track deployment status and collaborate across teams with full visibility into model performance across environments
Deployment at Scale
Deploy models with a reproducible packaging format that includes all code, dependencies, and weights. Serve them as REST APIs or run high-throughput batch inference with ai_query—optimized for both CPU and GPU via Databricks Model Serving.
See our Product News from Azure Databricks and AWS to learn more about our latest features.
Comparing MLflow offerings
Open Source MLflow | Managed MLflow on Databricks | |
|---|---|---|
Tracing & AI Observability | ||
Tracing APIs | ||
Notebook debugging integration | ||
Tracing for production applications | ||
Customizable observability dashboards | ||
Query trace data with SQL and AI/BI tools | ||
Production monitoring | ||
Generative AI Evaluation | ||
Evaluation APIs | ||
Human feedback UI and APIs | ||
High-quality LLM judges | ||
Versioned evaluation datasets | ||
Prompt Management | ||
MLflow Prompt Registry | ||
Prompt editor UI | ||
Experiment Tracking | ||
MLflow tracking API | ||
Rich performance & comparison dashboards | ||
Query experiment data with SQL and AI/BI tools | ||
MLflow tracking server | Self-hosted | Fully managed |
Notebooks integration | ||
Workflows integration | ||
Model Management | ||
MLflow Model Registry | ||
Model versioning | ||
Role-based approval workflows | ||
CI/CD workflow integrations | ||
Flexible Deployment | ||
Model packaging | ||
Large scale batch inference | ||
Low-latency real-time deployment | ||
Built-in streaming analytics | ||
Security and Management | ||
Enterprise governance | ||
High availability | ||
Automated updates |
Resources
Documentation
Tutorials
Blogs
Videos
eBooks
Webinars
Frequently Asked Questions
Ready to get started?