Streamline AI Agent Evaluation with New Synthetic Data Capabilities

Summary
- Generate evaluation datasets, the GenAI equivalent of software test suites, in minutes.
- Evaluate agent quality without waiting for subject matter experts to label data.
- Quickly identify and fix low-quality outputs.
Our customers continue to shift from monolithic prompts with general-purpose models to specialized agent systems to achieve the quality needed to drive ROI with generative AI. Earlier this year, we launched the Mosaic AI Agent Framework and Agent Evaluation, which are now used by many enterprises to build agent systems capable of complex reasoning over enterprise data and performing tasks like opening support tickets and responding to emails.
Today, we’re excited to announce a significant enhancement to Agent Evaluation: a synthetic data generation API. Synthetic data generation involves creating artificial datasets that mimic real-world data – but it’s important to note that this isn’t “made-up” information. Our API leverages your proprietary data to generate evaluation sets tailored based on that proprietary data and your unique use cases. Evaluation data, akin to a test suite in software engineering or validation data in traditional ML, enables you to assess and improve agent quality.
This allows you to quickly generate evaluation data – skipping the weeks to months of labeling evaluation data with subject matter experts (SMEs). Customers are already having success with these capabilities, accelerating their time to production and increasing their agent quality while reducing development costs:
"The synthetic data capabilities in Databricks MLflow have significantly accelerated our process of improving AI agent response quality. By pre-generating high-quality synthetic questions and answers, we minimized the time our subject matter experts spent creating ground truth evaluation sets, allowing them to focus on validation and minor modifications. This approach enabled us to improve relative model response quality by 60% even before involving the experts.”— Chris Nishnick, Director of Artificial Intelligence at Lippert
Introducing the Synthetic Data Generation API
Evaluating and improving agent quality is critical for delivering better business outcomes, yet many organizations struggle with the bottlenecks of creating high-quality evaluation datasets to measure and improve their agents. Time-consuming labeling processes, limited availability of (SMEs), and the challenge of generating diverse, meaningful questions often delay progress and stifle innovation.
Agent Evaluation's synthetic data generation API solves these challenges by empowering developers to create a high-quality evaluation set based on their proprietary data in minutes, enabling them to assess and enhance their Agent's quality without needing to block on SME input. Think of an evaluation set as akin to the validation set in traditional ML or a test suite in software engineering. The synthetic generation API is tightly integrated with Agent Evaluation, MLflow, Mosaic AI, and the rest of the Databricks Data Intelligence Platform , allowing you to use the data to quickly evaluate and improve the quality of your agent’s responses. To get started, see the quickstart notebook.

How does it work?
We’ve designed the API to be simple to use. First, call the API with the following input:
- A Spark or Pandas data frame containing the documents/enterprise knowledge that your agent will use
- The number of questions to generate
- Optionally, a set of plain language guidelines to guide the synthetic generation.
- For example, you might explain the agent’s use case, the persona of the end user, or the desired style of questions
Based on this input, the API generates a set of <question, synthetic answer, source document> based on your data in Agent Evaluation’s schema. You then pass this generated evaluation set to mflow.evaluate(...), which runs Agent Evaluation’s proprietary LLM judges to assess your agent’s quality and identify the root cause of any quality issues so you can quickly fix them.
You can review the results of the quality analysis using the MLflow Evaluation UI, make changes to your agent to improve quality, and then verify that those quality improvements worked by re-running mlflow.evaluate(...).
Optionally, you can share the synthetically generated data with your SMEs to review the accuracy of the questions/answers. Importantly, the generated synthetic answer is a set of facts that are required to answer the question rather than a response written by the LLM. This approach has the distinct benefit of making it faster for an SME to review and edit these facts vs. a full, generated response.
Boost Agent Performance in Five Minutes
To dive deeper, you can follow along in this example notebook that demonstrates how developers can improve the quality of their agent with the following steps:
- Generate a synthetic evaluation dataset
- Build and evaluate a Baseline agent
- Compare the Baseline agent across multiple configurations (prompts, etc) and foundational models to find the right balance of quality, cost, and latency
- Deploy the agent to a web UI to allow stakeholders to test and provide additional feedback

The Synthetic Data Generation API
To synthesize evaluations for an agent, developers can call the generate_evals_df method to generate a representative evaluation set from their documents.
Caption: An example usage of the Synthetic Data Generation API.
Customization and control
Through our conversations with customers, we’ve discovered that developers want to provide more than just a list of documents—they’re looking for greater control over the question-generation process. To address this need, our API includes optional features that empower developers to create high-quality questions tailored to their specific use cases.
agent_descriptionthat describe the task of the agentquestion_guidelinesthat control the style and type of questions.
Caption: Example agent_description and question_guidelines for a Databricks RAG chatbot.
Gartner®: Databricks Cloud Database Leader

Output of the synthetic generation API
To explain the outputs of the API, we passed this blog post as an input document to the API with the following question guidelines:
Only create questions about the content and not the code. Questions are those that would be asked by a developer trying to understand if this is a good product for them. Questions should be short, like a search engine query to find specific results.
Example questions:
- what is synthetic data used for?
- how do I customize synthetic data?
The output of the synthetic data generation API is a table that follows our Agent Evaluation schema. Each row of the dataset contains a single test case, used by Agent Evaluation’s answer correctness judge to evaluate if your agent can generate a response to the question that includes all of the expected facts.
| Field name | Description | Example from this blog post |
request | A question the user is likely to ask your agent | How can I customize question generation with the synthetic data API? |
expected_retrieved_context | The specific passage from the source document from which the request and expected_facts are synthesized. | Through our conversations with customers, we’ve discovered that developers want to provide more than just a list of documents—they’re looking for greater control over the question-generation process. To address this need, our API includes optional features that empower developers to create high-quality questions tailored to their specific use cases.
|
expected_facts | A list of facts, synthesized from the expected_retrieved_context, that a correct agent response must contain. | - Use - Use |
source_id | The unique ID of the source document from where this test case originated. | https://blog.databricks.com/blog/streamline-ai-agent-evaluation-with-new-synthetic-data-capabilities |
Caption: The output fields of the synthetic eval generation API and a sample row produced by the API based on the contents of this blog.
Below we include a sample of a few other requests and expected_facts generated by the above code.
request | expected_facts |
| What benefits do customers get from using synthetic data capabilities in Databricks MLflow? | - Accelerating time to production - Increasing agent quality - Reducing development cost |
| What inputs are required to use the synthetic data generation API? | - A Spark or Pandas data frame is required - The data frame should contain documents or enterprise knowledge - The number of questions to generate must be specified. |
| What is an evaluation set compared to in traditional machine learning and software engineering? | - An evaluation set is compared to a validation set in traditional machine learning - An evaluation set is compared to a test suite in software engineering. |
Caption: Sample of additional row produced by the API based on the contents of this blog.
Integration with MLflow and Agent Evaluation
The generated evaluation dataset can be used directly with mlflow.evaluate(..., model_type=”databricks-agent”) and the new MLflow Evaluation UI. In a nutshell, the developer can quickly measure the quality of their agent using built-in and custom LLM judges, inspect the quality metrics in the MLflow Evaluation UI, identify the root causes behind low-quality outputs, and determine how to fix the underlying issue. After fixing the issue, the developer can run an evaluation on the new version of the agent and compare quality against the previous version directly in the MLflow Evaluation UI.
Deployment via Agent Framework
Once you have an agent that reaches your business requirements for quality, cost, and latency, you can quickly deploy a production-ready, scalable REST API and a web-based chat UI using 1-line of code via Agent Framework: agents.deploy(...).
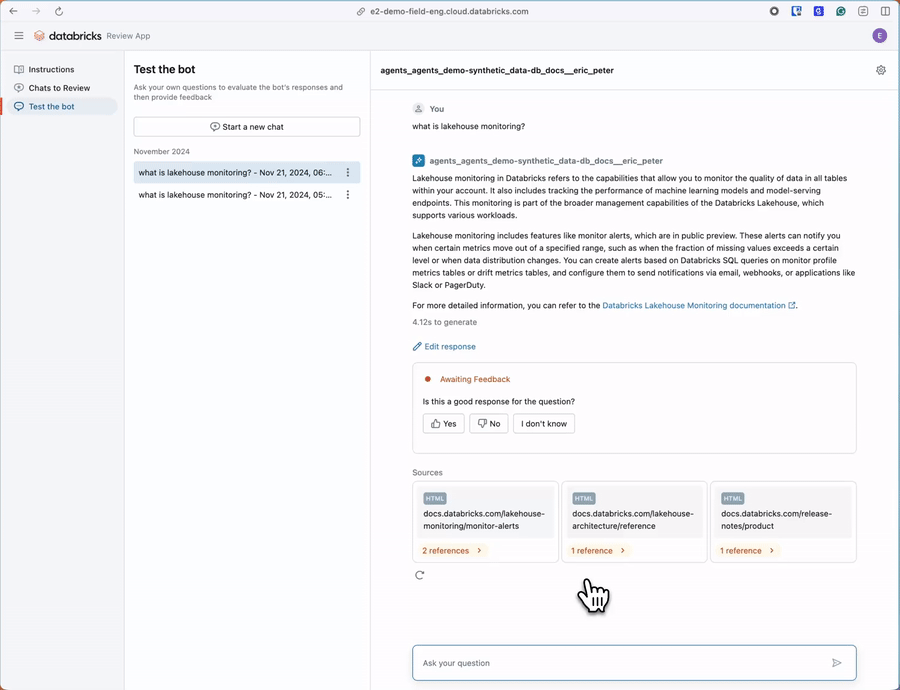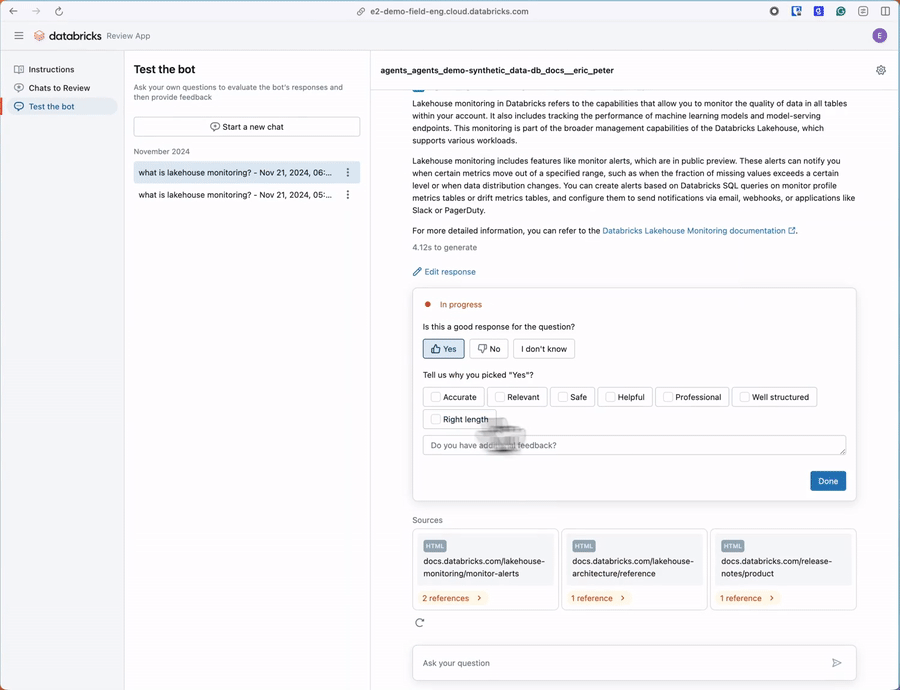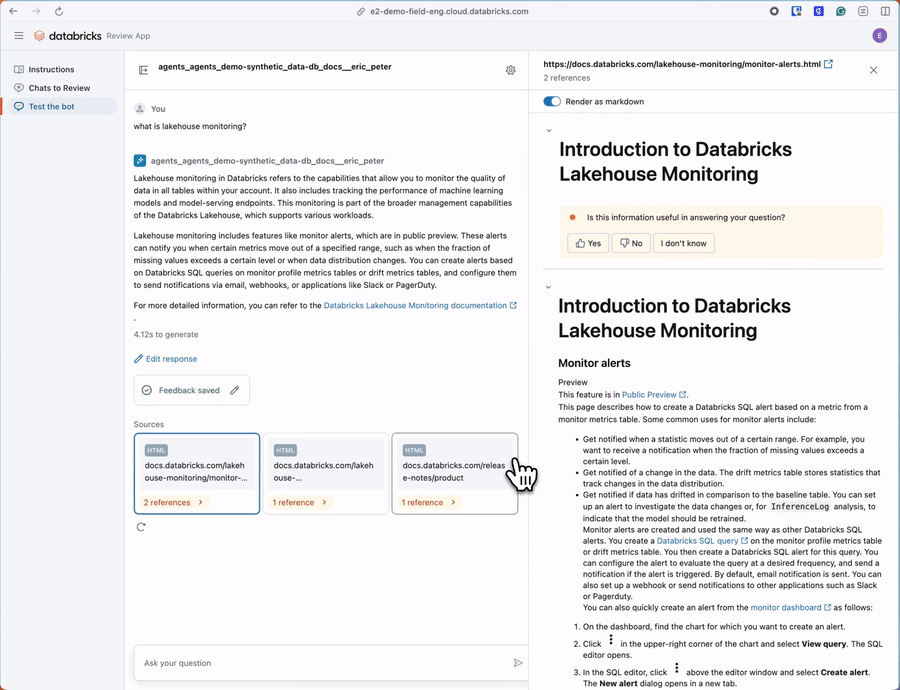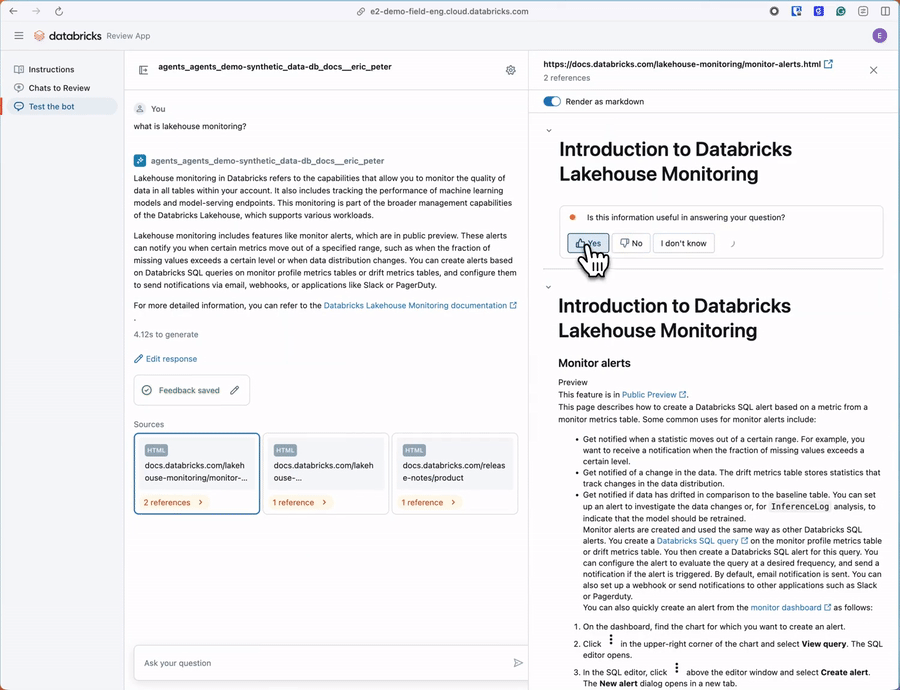
Get Started with Synthetic Data Generation
- To learn more and to run a demo notebook, visit Databricks documentation
- Watch the video demo.
What’s coming next?
We’re working on several new features to help you manage evaluation datasets and collect input from your SMEs.
The subject matter expert review UI is a new feature that enables your SMEs to quickly review the synthetically generated evaluation data for accuracy and optionally add additional questions. These UIs are designed to make business experts efficient in the review process, ensuring they only spend minimal time away from their day jobs.

The managed evaluation dataset is a service designed to help manage the lifecycle of your evaluation data. The service provides a version-controlled Delta Table that allows developers and SMEs to track the version history of your evaluation records e.g., the questions, ground truth, and metadata such as tags:
- Added new evaluation record
- Changed evaluation record e.g., question, ground truth, etc
- Deleted evaluation record
Select customers already have access to a preview of these features. To sign up for these features and other Agent Evaluation and Agent Framework previews, either talk to your account team or fill out this form.