Sunstone: Data-Powered Customer Success

Bringing Data+AI to Customer Success
At Databricks, we want to bring data and AI to all parts of our organization. This year, the Customer Success organization has partnered with our in-house data scientists to create data-powered tools that enhance the way we guide our customers on their journey to the Lakehouse. One of these projects is Sunstone, our internal recommendation platform.
Sunstone enables us to understand how a customer is leveraging the Databricks platform and customize recommendations among four different areas:
- Data engineering
- Machine learning
- Data analysis
- Platform administration
In this blog, we will talk about the history and motivation for Sunstone, how we build our recommendations, and how we've used it to make data-powered impacts for many of our customers. We will conclude with a brief section on our future plans for the project. We hope this will be an inspiration for other data-driven customer success teams looking to implement data products for their own customers.
Why we created Sunstone
Previously, helping our customers adopt best practices required multiple cycles of information gathering and discovery sessions. From these discovery sessions, we would engage with individuals to learn what role they are in, what features they are using, and how they are implementing their use cases. We relied on these engagements to glean information about where we could effectively help customers. It took on average 2-4 weeks to complete the cycle from scheduling a session to the customer implementing the recommendations. We needed to find a way to speed up the engagement and widen the breadth of recommendations and surface insights through telemetry.
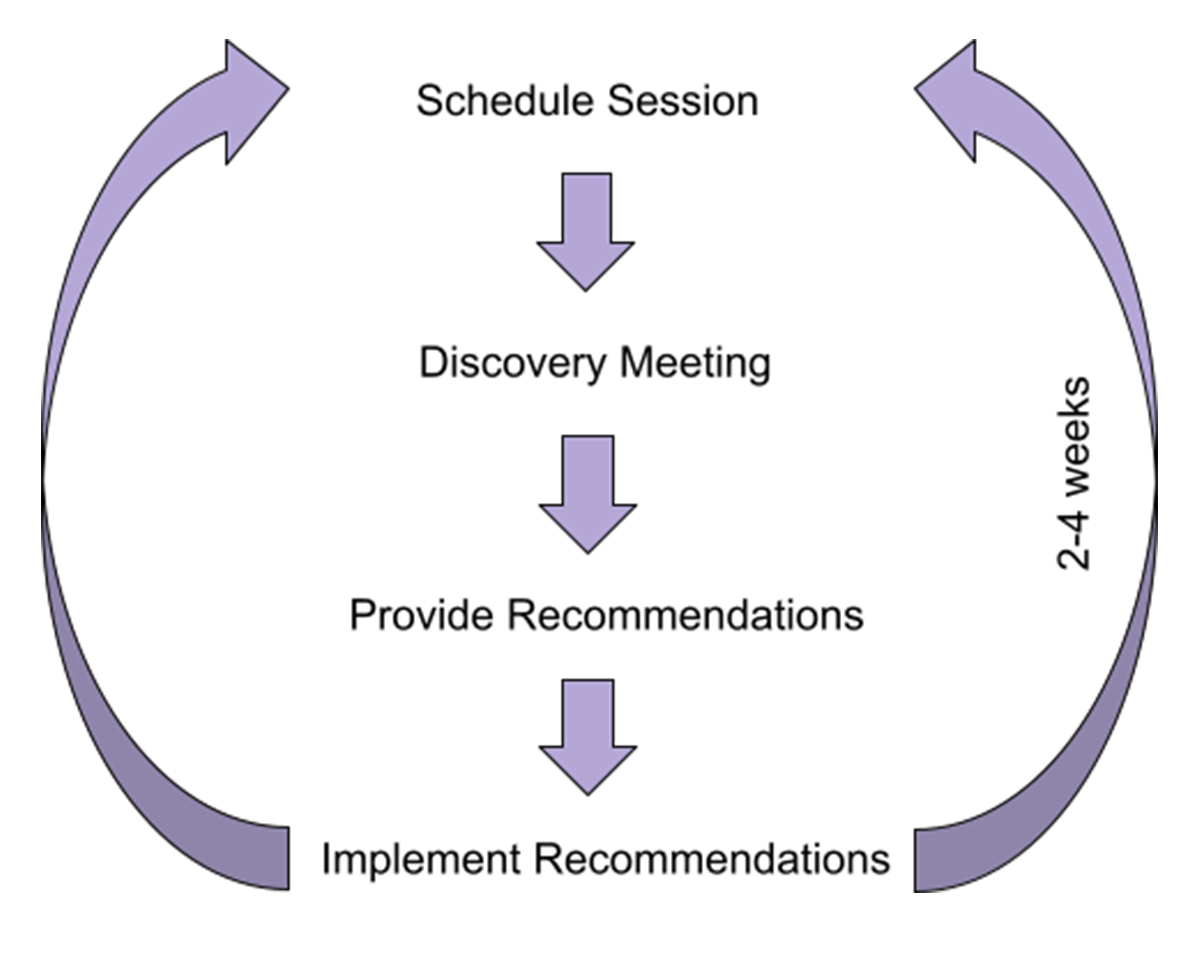
We started with developing a rule that helped us identify the workloads running on older runtimes. It's important for our customers to stay current in order to unlock the frequent enhancements we're making to the Databricks runtime. Our data scientists used our internal Lakehouse platform to instrument the feature needed to fuel the recommendation. We then materialized this recommendation on internal dashboards, allowing our customer facing teams to give this recommendation with their own customers. We've since expanded our suite to include many other recommendations, extending this capability to our other core groups of users including, Data Engineers and Data Scientists, with recommendations on Delta, Structured Streaming, ML Flow, and more. Sunstone has positively impacted our customers as they are implementing their use cases and we will explore more on that in the next section.
Big benefits for our customers at scale
By building a recommendation platform, we are able to serve our customers a consistent means of ensuring they are getting the most value out of the Databricks platform. In the past, it would have taken multiple discovery sessions to learn that the customer didn't have IP access lists configured to restrict access to workspaces or weren't using cluster policies to enforce cluster creation constraints across their organization. Now with Sunstone, we can generate this diagnostic before we even meet our customers for the first time. This approach has enabled the Customer Success team to onboard a customer faster, as well as enable our customers to develop their use cases faster, leading to an earlier and more efficient go-live.
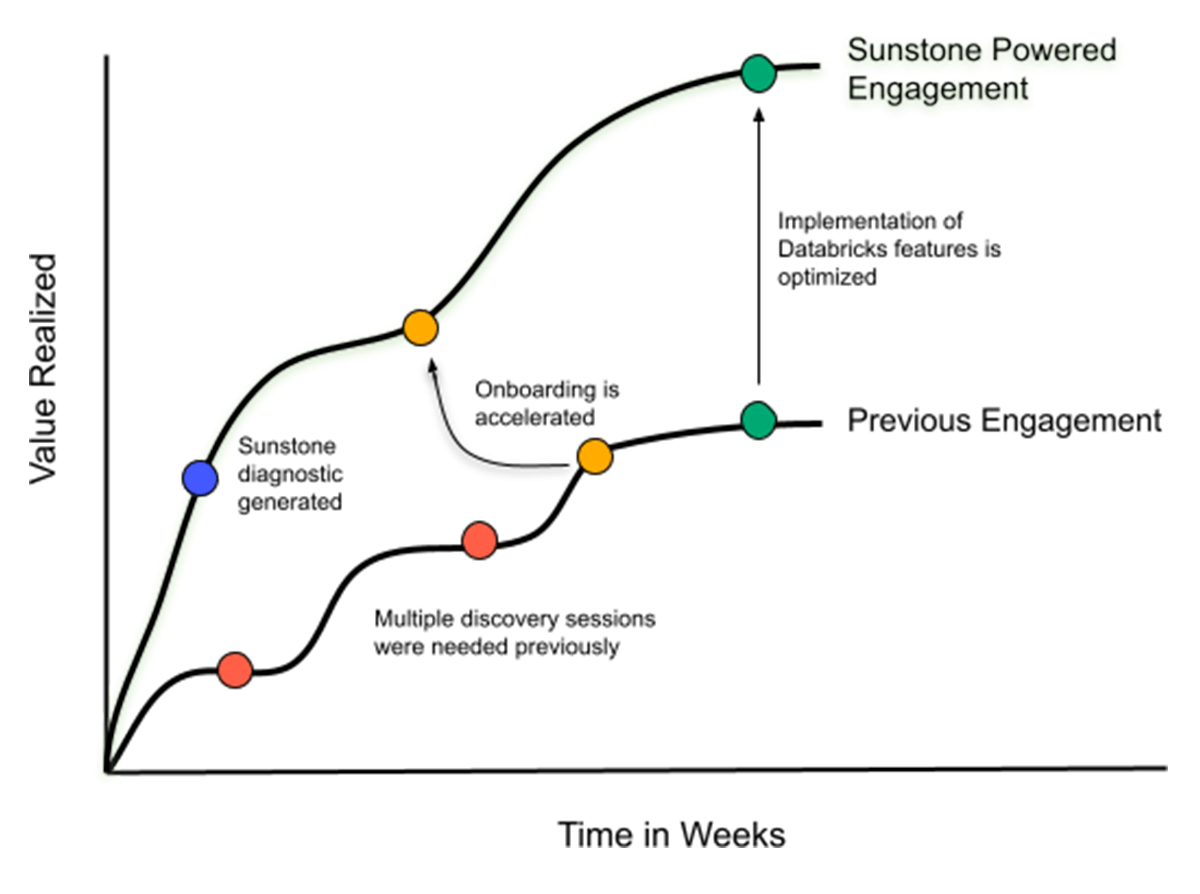
Let's convert data into actions
In this section, we will discuss our learnings on working with telemetry data and influencing human behavior. Telemetry data in its raw form is not actionable. In order to render the data to our purpose, we take the telemetry data and blend in best practices to create a human readable score. We wanted the score to be easily interpreted as good or bad, so we designed the score to be on a scale of 0 to 100 with 0 being least optimal and 100 being the most optimal. A good score (higher than 80) is a positive reinforcement that shows the customer is leveraging all the recommended features. A less optimal score (lower than 50) prompts the customer to investigate what is causing it and opens the door to implementing changes.
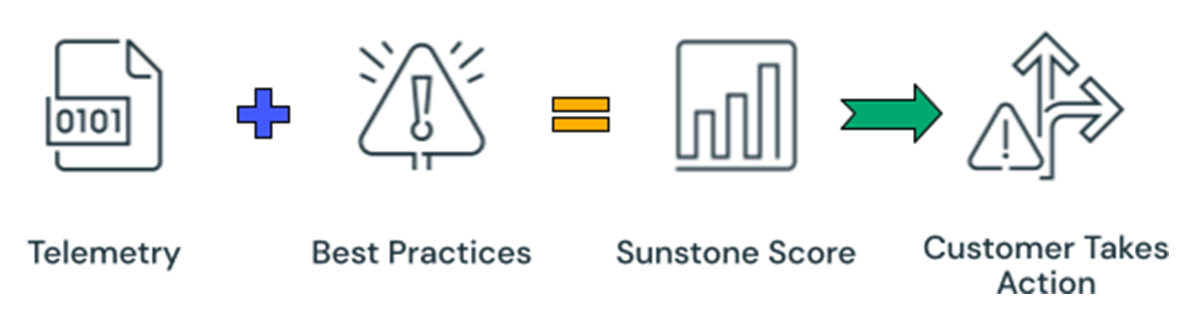
Our best practices are compiled from years of trial and error from customer facing teams interacting with customers. They are informed, intelligent, and far from arbitrary. We take best practices from the customer teams and refine them further with Product Manager and Product Specialist input. When we are developing a new recommendation, it's not uncommon that we see this rule development phase debated over many iterations.
| Bad Recommendation | Good Recommendation |
|---|---|
| Cluster 1 = Runtime 7.3 Cluster 2 = Runtime 9.1 Cluster 3 = Runtime 10.4 Cluster 4 = Runtime 11.2 Recommended Action: Keep your clusters updated. |
Your score is 75/100. DBR 7.3 is coming up to the end of support while 11.3 enables Unity Catalog and numerous other enhancements to the Databricks platform. Recommended Action: Upgrade Cluster 1 to Runtime 11.3 LTS. |
Figure 4. The difference between a bad recommendation and a good recommendation is being specific and prescriptive.
It's important to provide recommendations only when an action can be taken as a result of it. A bad recommendation states the facts and presents little direction on what to do with the information. A good recommendation will give you an idea of the severity of the problem and intuitively communicates what you need to do to increase the score.
Furthermore, recommendations should be bucketed and filtered based on whether it is relevant to them. A data engineer may not care about Audit Logging so we don't give them that recommendation. Instead, we give the data engineer recommendations on using Vacuum when creating tables in their data pipelines.
| Role | Recommended Action | Benefits |
|---|---|---|
| All | The customer should be using the latest Runtime version. | Users will have access to the latest features and security updates. |
| Platform Administration | The customer should turn on Audit Logging on all of their workspaces. | Customers will be able to audit user activity on their workspace. |
| Platform Administration | The customer should be making Secrets API calls to all of their workspaces in the last 28 days. | Users can hide sensitive credentials like passwords in notebooks. |
| Data Engineer | The customer should be running Vacuum commands on their tables. | Use Delta Vacuum to remove old files to not incur unnecessary cloud storage costs. |
Figure 5. Recommended actions are given to relevant roles and benefits are clearly articulated.
How a customer recently benefited from Sunstone
In working with one of our customers, our Customer Success Engineers consulted Sunstone to identify a set of recommendations. They realized immediately that there were several important features that they could recommend. These were:
- Secrets: The workspaces listed here have jobs and other workflows that are not utilizing the secrets API, which prevents the exposure of sensitive credential information in Databricks notebooks and jobs. Using the secrets API is an easy way to ensure you're securely utilizing credential and similar information in your Databricks workflows.
- Audit Logging: This score measures the implementation of the audit logging feature across workspaces. Audit logging is a service customers can activate which sends low-latency logs in JSON format for any workspace in which it's been configured. Every 15 minutes, Databricks will pipe customer workspace-level metrics to a desired cloud storage location. They contain a rich schema of information including details on accounts, secrets, dbfs, secrets, and more.
In their regular syncs with the customer, they addressed our recommendations. Over the next few months, the customers' use of both Secrets and Audit Logs hit the top of the mark.
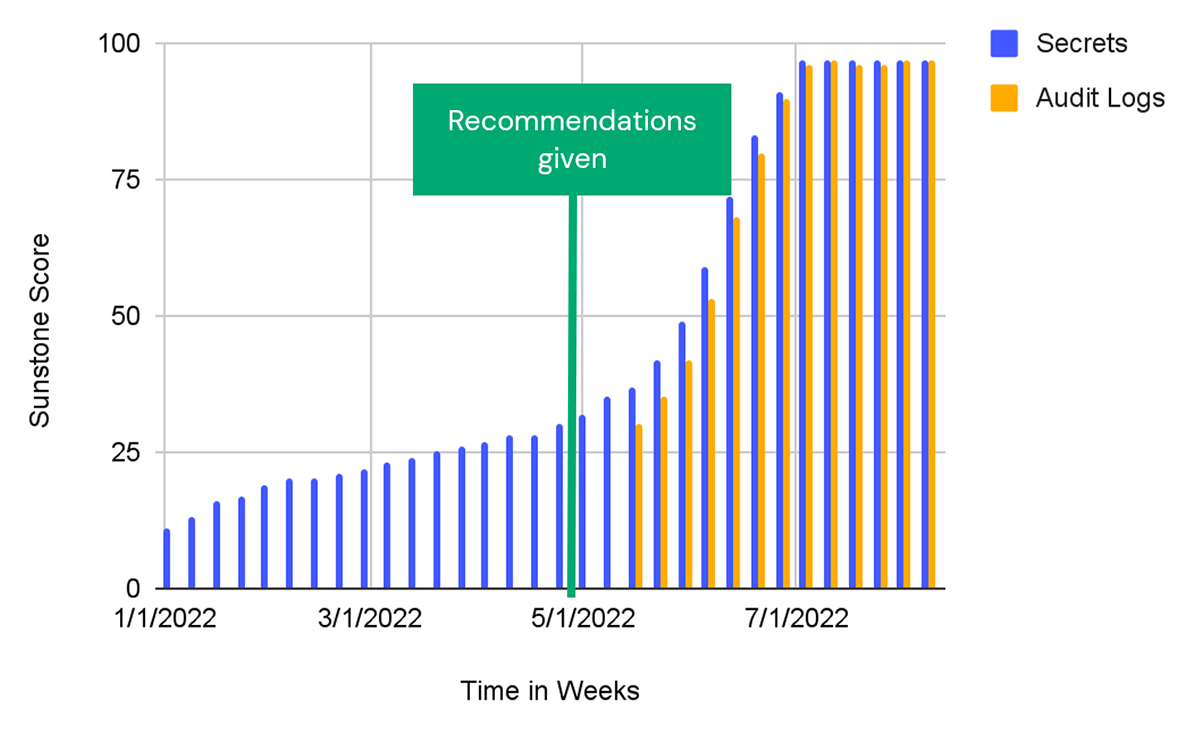
generated by Sunstone.
By implementing these features, the customers increased their security and reduced their compliance risk.
What's next?
In conclusion, Sunstone has enabled our customer teams to better understand and serve their customers with a diagnostic that intelligently qualifies and provides actionable recommendations. We're building data-powered tools to make it easier for our customers to be successful on Databricks. On the horizon is a move away from our current self-serve model to one that directly makes recommendations to customers.
Sunstone has been adopted broadly across the Customer Success organization. It is leveraged on a daily basis to provide over 100,000 actionable recommendations so far this year. On average, we have also seen a 60% reduction in ramp up time for our customers.
If you are interested in building or leveraging tools like Sunstone, we are hiring! If you are interested in how the Databricks platform can enable your use cases, please email us at [email protected].
Acknowledgements
We would like to thank our data heroes Francois Callewaert and Catherine Ta from the Data Science team for creating Sunstone with us and accommodating Customer Success' many feature requests. Also, thank you to Ravi Dharnikota and Francois Callewaert for helping review this blog post. Finally, thank you Manish Bharti for providing a great case study to walk through!
Never miss a Databricks post
What's next?

Best Practices
May 6, 2024/14 min read
Building High-Quality and Trusted Data Products with Databricks

Best Practices
July 30, 2024/4 min read