Unlocking FHIR for Data and AI in a Meaningful Way

Discover how the Databricks and XponentL partnership is allowing customers to unlock their FHIR needs. Learn more about dbignite.
Imagine you’re feeling under the weather. As a patient, you want your ailment addressed with the least amount of friction so that you can get back to full health quickly.
No matter which healthcare location you choose (urgent care, primary care physician’s office, hospital), or which provider you see, the care team’s ability to access your holistic patient journey data has never been more critical to ensuring efficient and effective treatment.
Healthcare sits on a tremendous amount of data. In fact, healthcare as an industry is said to generate 30% of the world’s data. Each encounter you have with a provider generates breadcrumbs of your health story. Given the number of systems your provider uses to capture this data, accessing your holistic health story poses a significant challenge.
With the emergence of interoperable healthcare standards, combined with big data platforms, healthcare organizations are positioned today more than ever to build a complete view of the patient.
The Potential of Interoperable Healthcare Standards - HL7 and FHIR
Today, healthcare leverages interoperable interfacing standards like HL7 v2 and Fast Healthcare Interoperability Resources (FHIR) to facilitate better ways to exchange data and see the individual holistically, no matter where their care team may be, or where the data is captured.
FHIR is designed to represent all permutations in healthcare with resource-specific data in a complex nested structure. The nature of such a vast representation makes it difficult to both write FHIR from and read FHIR into internally formatted custom schemas. dbignite, an open-source solution built on Databricks, makes FHIR easy to work with, cementing itself as the next big development combating inefficiencies in healthcare data sharing.
XponentL Data co-developed dbignite as a FHIR converter and its capabilities far exceed expectations such as:
- Writing to any FHIR resource from custom schemas, with minimal data mapping and code exercises
- Reading FHIR into custom schemas, utilizing low code
- Supporting real-time streaming and analytics
- Extendability to utilize custom FHIR resources
The cherry on top is that all of the dbignite capabilities run on pySpark and SQL, eliminating the need to learn additional languages as other FHIR converters require and democratizing access to FHIR data to empower larger audiences of users.
Using FHIR has never been faster thanks to dbignite, and this new-found efficiency unlocks the utilization of our toolkit at a scale other FHIR conversion tools cannot match.
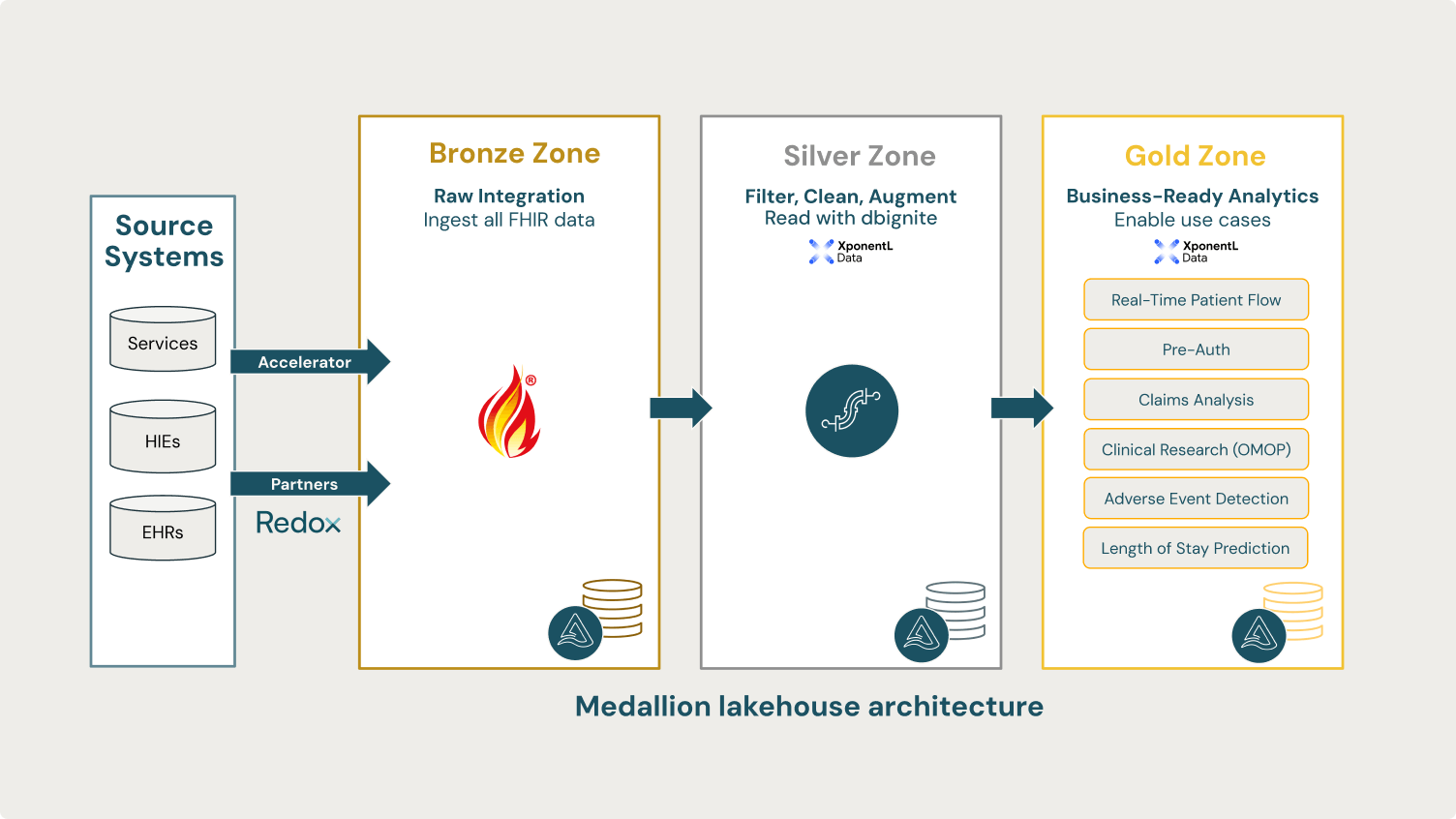
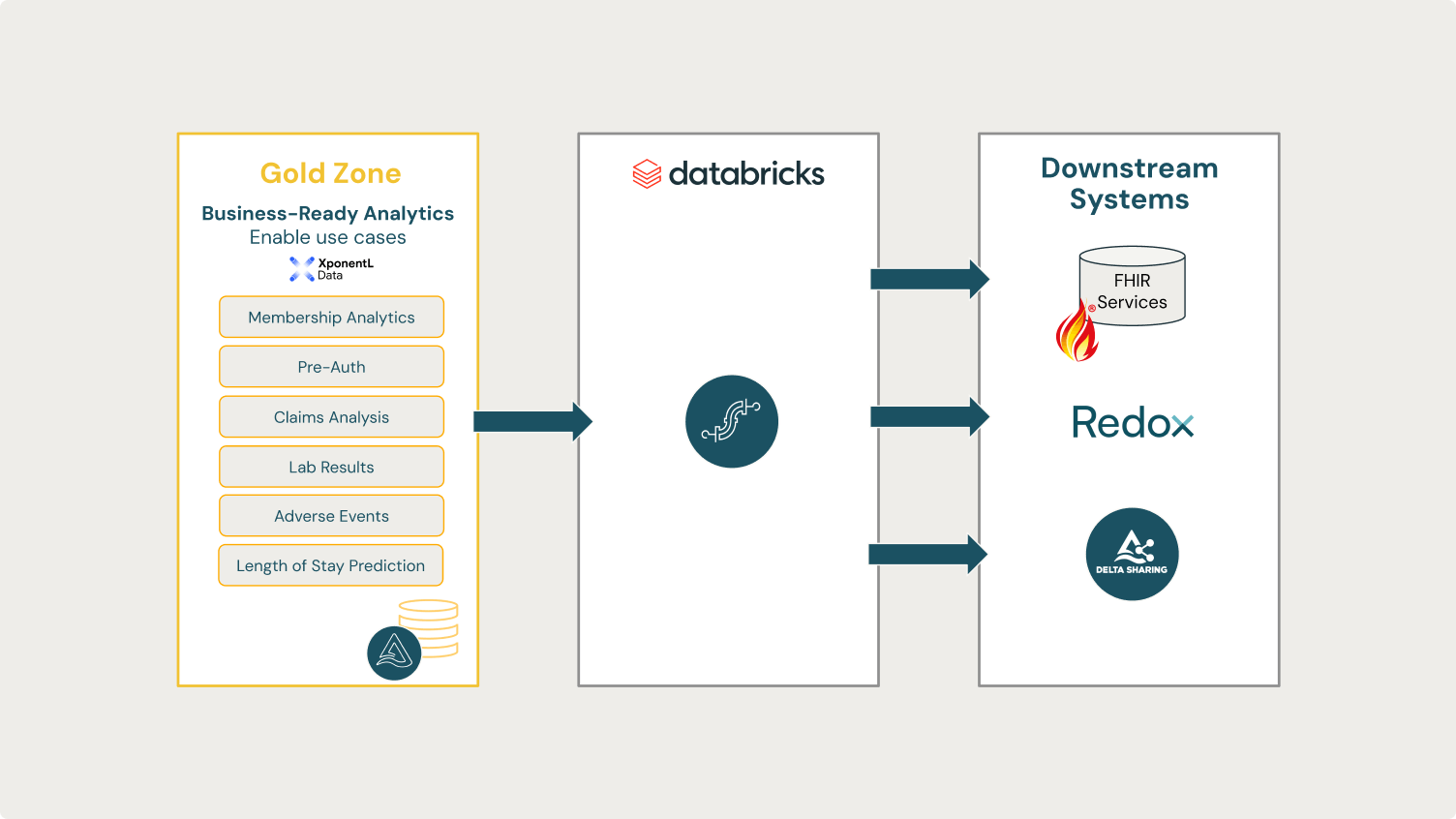
FHIR in Action
Let’s take the example of a large integrated delivery network (IDN) organization. Presumably, many of their clinics will need to read and write FHIR. dbignite can be applied in these instances at scale.
However, the organization may also have the desire to view data from the different arms from a centralized hub. An architecture can be orchestrated to have dbignite write FHIR from the multiple branches and then read the data into the specified format within the hub. Additionally, dbignite can be leveraged to modernize any legacy data into the hub through the same methodology.
Further development slated for the near future includes:
- Reducing the need to map resources between a FHIR schema and custom schema by utilizing GenAI and Databricks Unity Catalog, which auto-describes tables and columns and can infer industry-specific meaning
- Expanding to include HL7 v2 and CCDA in the conversion to FHIR capabilities
Let’s Get Started
Unlock the full potential of FHIR for seamless, secure healthcare data access. Request a demo today to see dbignite in action and transform your data interoperability.
About XponentL
We are innovators dedicated to driving your business forward. Our mission is to transform complex Data & AI challenges into powerful solutions that provide you with a competitive advantage. Join us on the journey to transformation.
Never miss a Databricks post
What's next?

Healthcare & Life Sciences
November 14, 2024/2 min read
Providence Health: Scaling ML/AI Projects with Databricks Mosaic AI

Product
November 27, 2024/6 min read