What's new with Databricks SQL, October 2024
Summary of launches from August through October 2024, including AI/BI, SQL editing, performance updates, and more

Published: November 7, 2024
by Ina Felsheim, Gaurav Saraf, Miranda Luna and Ken Wong
We are excited to share the latest features and performance improvements that make Databricks SQL simpler, faster, and more affordable than ever. Databricks SQL is an intelligent data warehouse within the Databricks Data Intelligence Platform and is built on the lakehouse architecture. In fact, Databricks SQL has over 8,000 customers today!
In this blog, we will share details for AI/BI, intelligent experiences, and predictive optimizations. We also have powerful new price/performance capabilities. We hope you like our innovative features from the last three months.

AI/BI
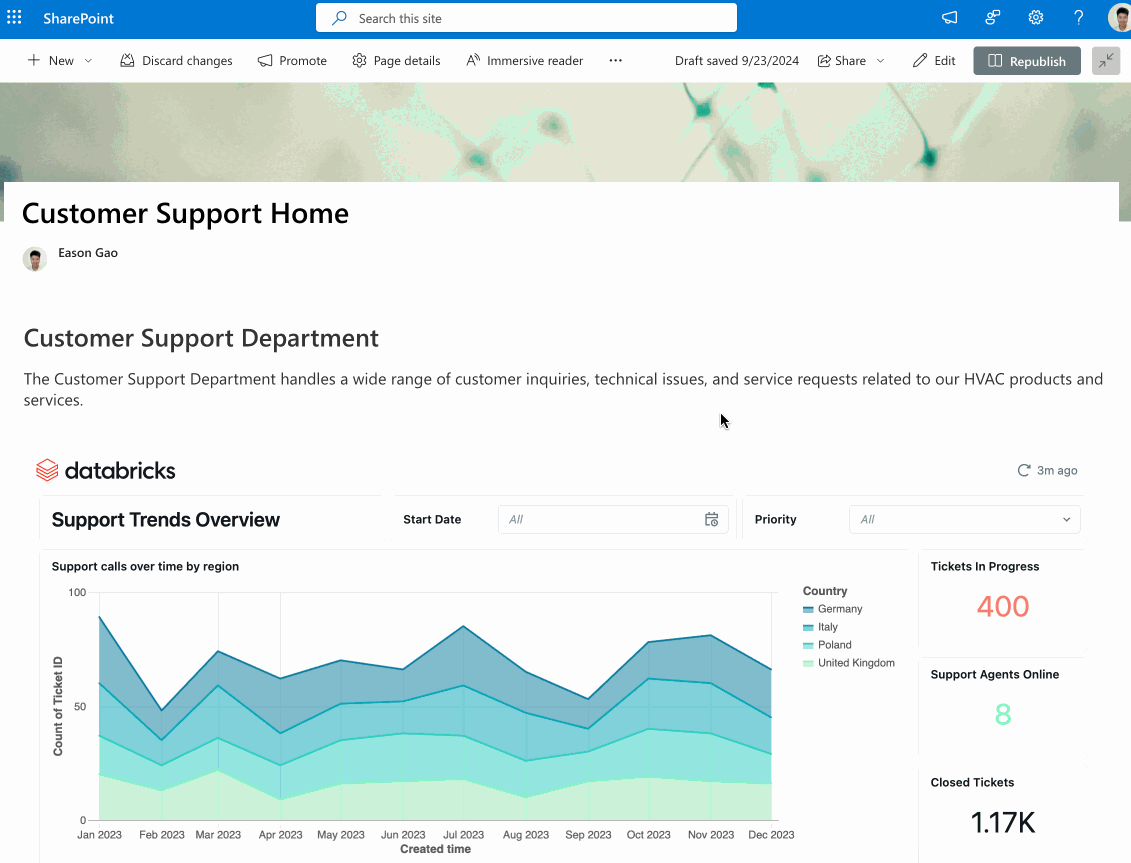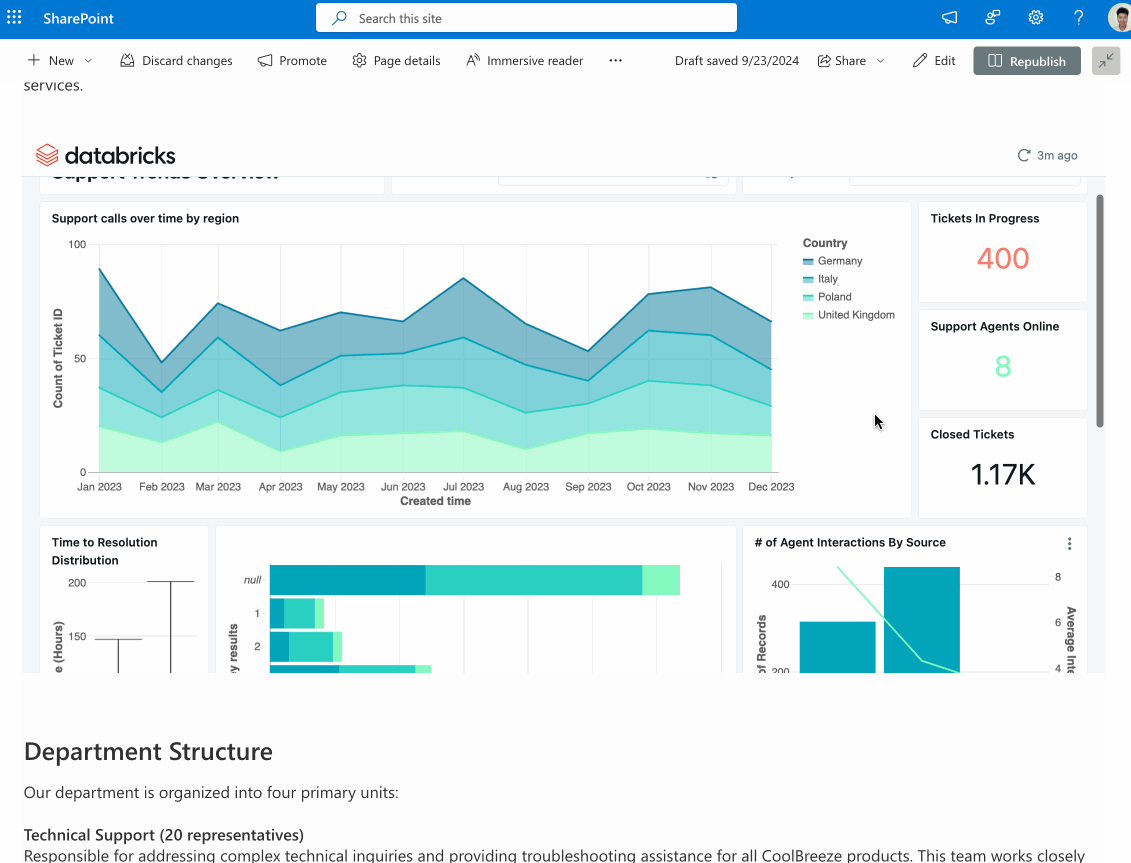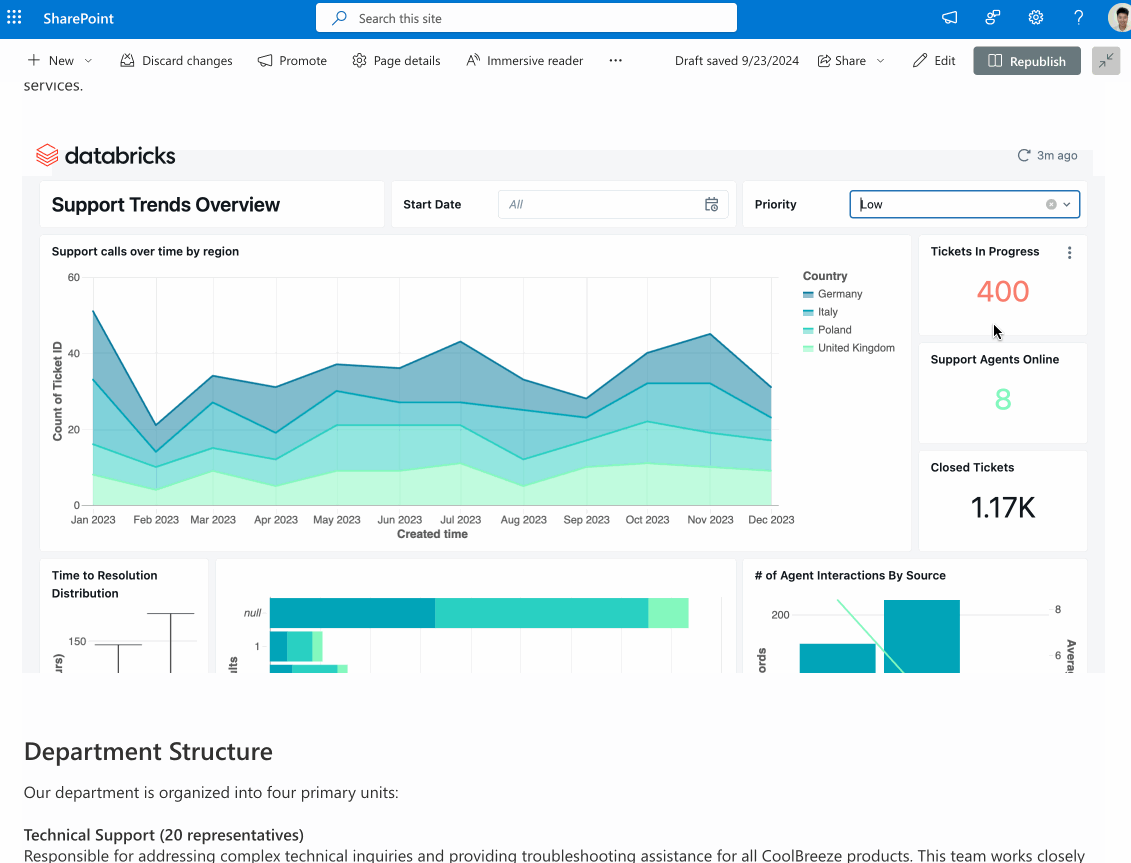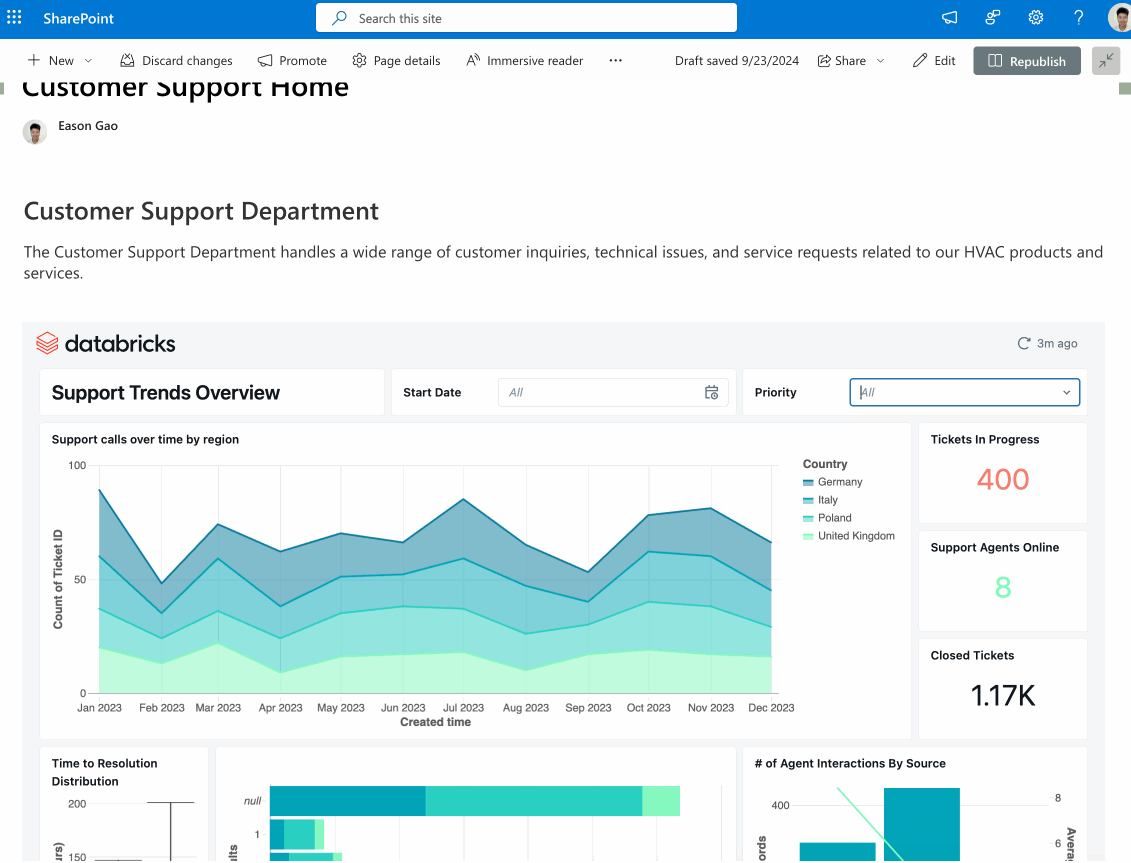
Since launching AI/BI at Data and AI Summit 2024 (DAIS), we’ve added many exciting new enhancements. If you’ve not yet tried AI/BI, you’re missing out. It is included for all Databricks SQL customers to use without the need for additional licenses. AI/BI is a new type of AI-first business intelligence product, native to Databricks SQL and built to democratize analytics and insights for everyone in your organization.
In case you missed it, we just published a What’s New in AI/BI Dashboards for Fall 2024 blog highlighting lots of new features like a new Dashboard Genie, multi-page reports, interactive point maps and more. These capabilities add to a long list of enhancements we’ve added since the summer, including next-level interactivity, the ability to share dashboards beyond the Databricks workspace, and dashboard embedding. For AI/BI Genie, we’ve been focused on helping you build trust in the answers it generates through Genie benchmarks and request a review.
Stay tuned for even more new features this year! The AI/BI release notes provide more details.
Intelligent experiences
We are infusing ML and AI throughout our products because automation helps you focus on higher-value-added work. The intelligence also helps you democratize access to data and AI with built-in natural language experiences built for your specific business and on your specific data.
SQL development gets a boost
We get it–SQL is your best friend. Check this out–a new SQL editor to blend the best aspects of the platform into a unified and streamlined SQL authoring experience. It also offers several improved features, including multiple statement results, real-time collaboration, enhanced Databricks Assistant integrations, and editor productivity features to take your SQL development to the next level. Learn more about the new SQL editor.

We have also made additional improvements to help you construct your SQL, such as using named parameter marker syntax (across the SQL editor, notebooks, and AI/BI dashboards).
AI-generated comments
Well-commented SQL is necessary for collaboration and maintainability. Instead of starting from scratch, you can use AI-generated comments for catalogs, schemas, volumes, models, and functions. You can even use Assistant for inline chat to help edit your comments.

New features and improvements
Finally, we have a long list of smaller improvements that will make your experience smoother. For that extensive list, check the Databricks SQL Release Notes.
Predictive optimization of your platform
We are continuously striving to optimize all of your workloads. One method is to use AI/ML to handle some details for you automatically. We have a few new features for you.
Automated statistics
Query planning gets smarter by using statistics, but that requires you to know how to run the ANALYZE command. However, fewer than 5% of customers run ANALYZE. And, because tables can have hundreds of columns (or more) and query patterns change over time, you may need help optimally running workloads.
Specifically, you may have these situations:
- Data Engineers have to manage “optimization” jobs to maintain statistics
- Data Engineers have to determine which tables need to have statistics updated and how often
- Data Engineers have to ensure that the key columns are in the first 32
- Data Engineers have to potentially rebuild tables if query patterns change or new columns are added
With these new intelligent statistics enabled, statistics are managed in two phases. First, statistics are collected for all new data written with Photon-enabled compute. This is faster and cheaper because the data is read only once (compared to running ANALYZE after ingestions). Then, as statistics become stale (due to UPDATE and DELETE statements), this process runs ANALYZE in the background to ensure the statistics are always fresh.
To sign up for the Gated Public Preview of Predictive Optimization for statistics, use this form.
Query profiler
We also launched new capabilities for the query history and profiler, which are available in Private Preview. Databricks SQL materialized views and streaming tables now have better plans and query insights.
Query History and Query Profile now cover queries executed through a DLT pipeline. Moreover, query insights for Databricks SQL materialized views (MVs), and streaming tables (STs) have been improved. These queries can be found on the Query History page alongside queries executed on SQL Warehouses and Serverless Compute. They are also listed in the context of the Pipeline UI, Notebooks, and the SQL editor.
This demo also shows you materialized views and streaming tables, which are now generally available. See the section below for details.

World-class price/performance
The query engine continues to be optimized to scale compute costs with near linearity to data volume. Our goal is ever-better performance in a world of ever-increasing concurrency–with ever-decreasing latency.
Performance updates
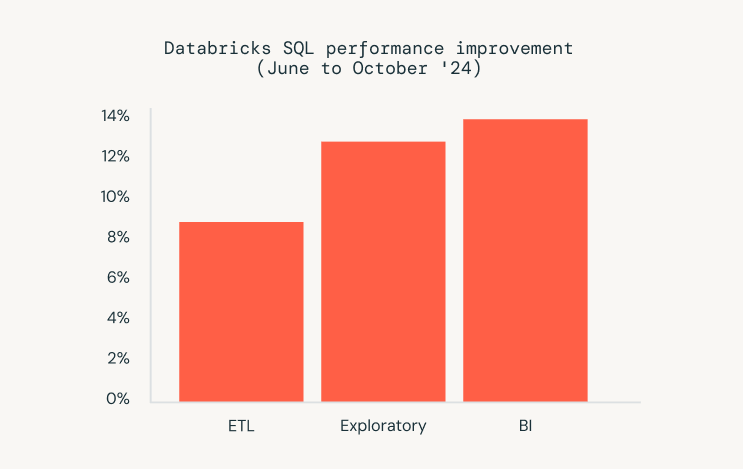
In the past five months, we also have launched new advancements in Databricks SQL that enhance performance and reduce your total cost of ownership (TCO). We understand that performance is paramount for delivering a seamless user experience and optimizing costs. At Data and AI Summit 2024 (DAIS), we announced that we had improved performance for the same interactive BI queries by 73% since Databricks SQL’s launch in 2022. That is 4x faster! A little over five months later, we're happy to announce that we are now 77% faster, as calculated by the Databricks Performance Index (DPI)!
These aren't just benchmarks. We track millions of real customer queries that run repeatedly over time. Analyzing these similar workloads allows us to observe a 77% speed improvement, reflecting the cumulative impact of our continued optimizations. Teaser alert: We have also made Extract, Transform, and Load (ETL) workloads 9% more efficient, BI workloads 14% more performant, and exploratory workloads 13% faster. Check out the performance updates blog for details.
System tables
System tables are the recommended way to observe essential details about your Databricks account, including cost information, data access, workload performance and more. Specifically, they are Databricks-owned tables that you can access from a variety of surfaces, usually with low latency.
The Databricks system tables platform is now generally available, including system.billing.usage, and system.billing.list_price tables. The billing schema is enabled automatically for every metastore. The billing system tables will remain available at no additional cost across clouds, including one year of free retention.
Learn how to monitor usage with system tables. You can see an example of how the system tables are used in the Cost and Usage Dashboard section.
Cost and Usage Dashboard powered by AI/BI
To understand your Databricks costs and identify expensive workloads, we launched the new Cost and Usage Dashboard powered by AI/BI. With the dashboard, you can see the context of your spending and understand which project your costs are originating from. Finally, you can find your most expensive jobs, clusters, and endpoints.
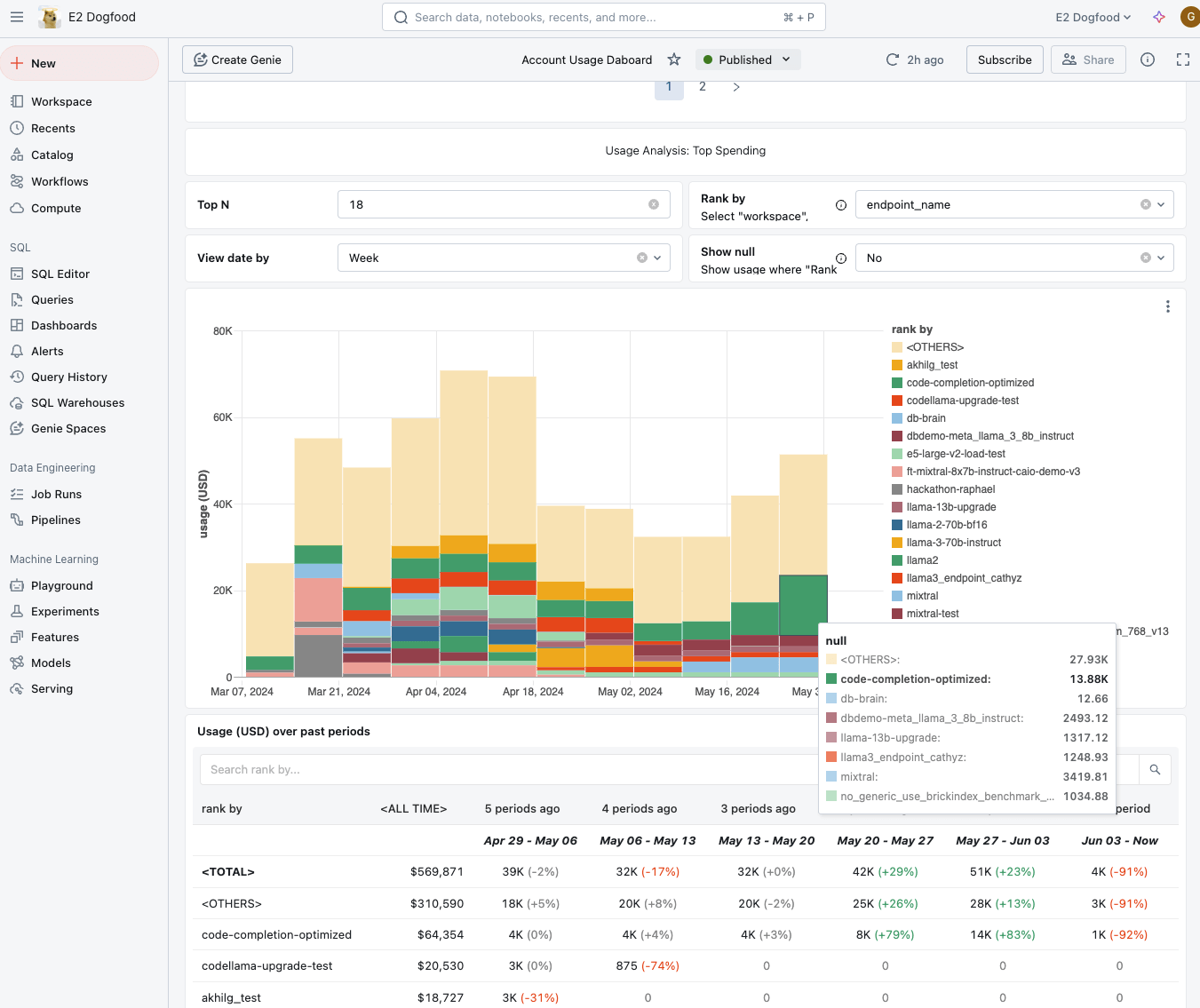
To use the dashboard, set them up in the Account Console. The dashboards are available in AWS non-govcloud, Azure, and GCP. You own and manage the dashboards, so customize them to fit your business. To learn more about these dashboards in Public Preview, check out the documentation.
Databricks SQL Serverless warehouses
We continue expanding availability, compliance, and more for our Databricks SQL Serverless warehouses. Databricks SQL Warehouses are serverless warehouses with instant and elastic compute (decoupled from storage). The compute is managed by Databricks.
- New regions:
- Google Cloud Platform (GCP) is available across the existing seven regions.
- AWS adds the eu-west-2 region for London.
- Azure adds four regions for France Central, Sweden Central, Germany West Central, and UAE North.
- HIPAA: HIPAA compliance is available in all regions and all clouds (Azure, AWS, and GCP). HIPAA compliance was also added to AWS us-east-1 and ap-southeast-2.
- Private Link: Private link helps you use a private network from your users to your data and back again. It is now generally available.
- Secure Egress: Configure egress controls on your network. Secure egress is now available in Public Preview.
- Compliance security profile: Support for serverless SQL warehouses with the compliance security profile is now available. In regions where this feature is supported, workspaces enabled for the compliance security profile now use serverless SQL warehouses as their default warehouse type. See which computing resources get enhanced security and serverless computing feature availability.
- Serverless default: Starter warehouses are now serverless by default. This setting change helps you get started quickly instead of waiting for IT to provision resources.
Materialized views and streaming tables
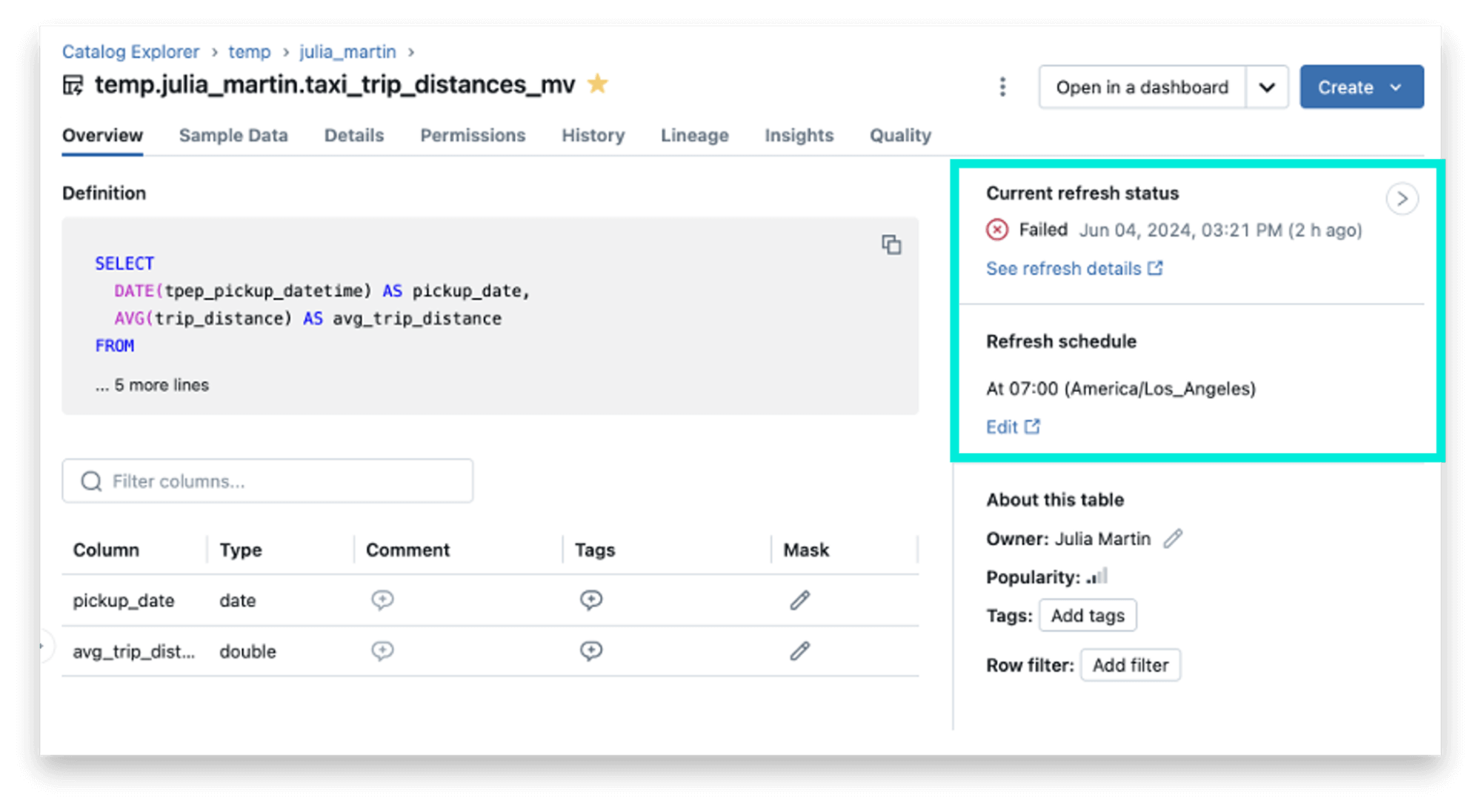
We’ve been talking about materialized views and streaming tables for a while, as they are a great way to reduce costs and improve query latency. (Fun fact: materialized views were first supported in Databricks with the launch of Delta Live Tables.) These features are now generally available (woot), but we just couldn’t help ourselves. We have added new capabilities in the general availability release, including improving observability, scheduling, and cost attribution.
- Observability: the catalog explorer includes contextual, real-time information about the status and schedule of materialized views and streaming tables.
- Scheduling: the EVERY syntax is now available for scheduling materialized view and streaming table refreshes using DDL.
- Cost attribution: the system tables can show you who is refreshing materialized view and streaming tables.
To learn more about materialized views and streaming tables, see the blog announcing the general availability of materialized views and streaming tables in Databricks SQL.
Publish to Power BI
Now, you can create semantic models from tables/schemas on Databricks and publish all of them directly to Power BI Service. Comments on a table’s columns are copied to the descriptions of corresponding columns in Power BI.

To get started, see Publish to Power BI Online from Azure Databricks.
Integration with Data Intelligence Platform
These features for Databricks SQL are part of the Databricks Data Intelligence Platform. Databricks SQL benefits from the platform's capabilities of simplicity, unified governance, and openness of the lakehouse architecture. The following are a few new platform features that are especially useful for Databricks SQL.
Compute budget policies
Compute budget policies to help manage and enforce cost allocation best practices for compute–regardless of whether you are doing interactive workloads, scheduled jobs, or event Delta Live Tables.
Vector Search native support in Databricks SQL
Vector databases and vector search use cases are multiplying. In Q3, we launched a gated Public Preview for Databricks SQL support for Vector Search. This integration means you can call Databricks MosaicML Vector Search directly from SQL. Now, anyone can use vector search to build RAG applications, generate search recommendations, or power analytics on unstructured data.

vector_search() is now available in Public Preview in regions where Mosaic AI Vector Search is supported. For more information, see vector_search function.
More details on new innovations
We hope you enjoy this bounty of new innovations in Databricks SQL. You can always check this What’s New post for the previous three months. Below is a complete inventory of launches we've blogged about over the last quarter:
- Just announced: Performance improvements
- November 2024: What's new in AI/BI Dashboards - Fall '24
- October 2024: Introducing the New SQL Editor
- October 2024: How to embed AI/BI Dashboards into your websites and applications
- September 2024: What’s new with Databricks SQL
- September 2024 (update): Five simple steps for implementing a star schema in Databricks with Delta Lake
- September 2024: Next-Level Interactivity in AI/BI Dashboards
- September 2024: How to share AI/BI Dashboards with everyone in your organization
- August 2024: Data Warehousing Trends from Data + AI Summit
- August 2024: Onboarding your new AI/BI Genie
- August 2024: Databricks SQL Serverless is now available on the Google Cloud Platform
As always, we continue to work to bring you even more cool features. Stay tuned to the quarterly roadmap webinars to learn what's on the horizon for Data Warehousing and AI/BI. It's an exciting time to be working with data, and we're excited to partner with Data Architects, Analysts, BI Analysts, and more to democratize data and AI within your organizations!
To learn more about Databricks SQL, visit our website or read the documentation. You can also check out the product tour for Databricks SQL. Suppose you want to migrate your existing warehouse to a high-performance, serverless data warehouse with a great user experience and lower total cost. In that case, Databricks SQL is the solution — try it for free.
To participate in private previews or gated public previews, contact your Databricks account team.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read