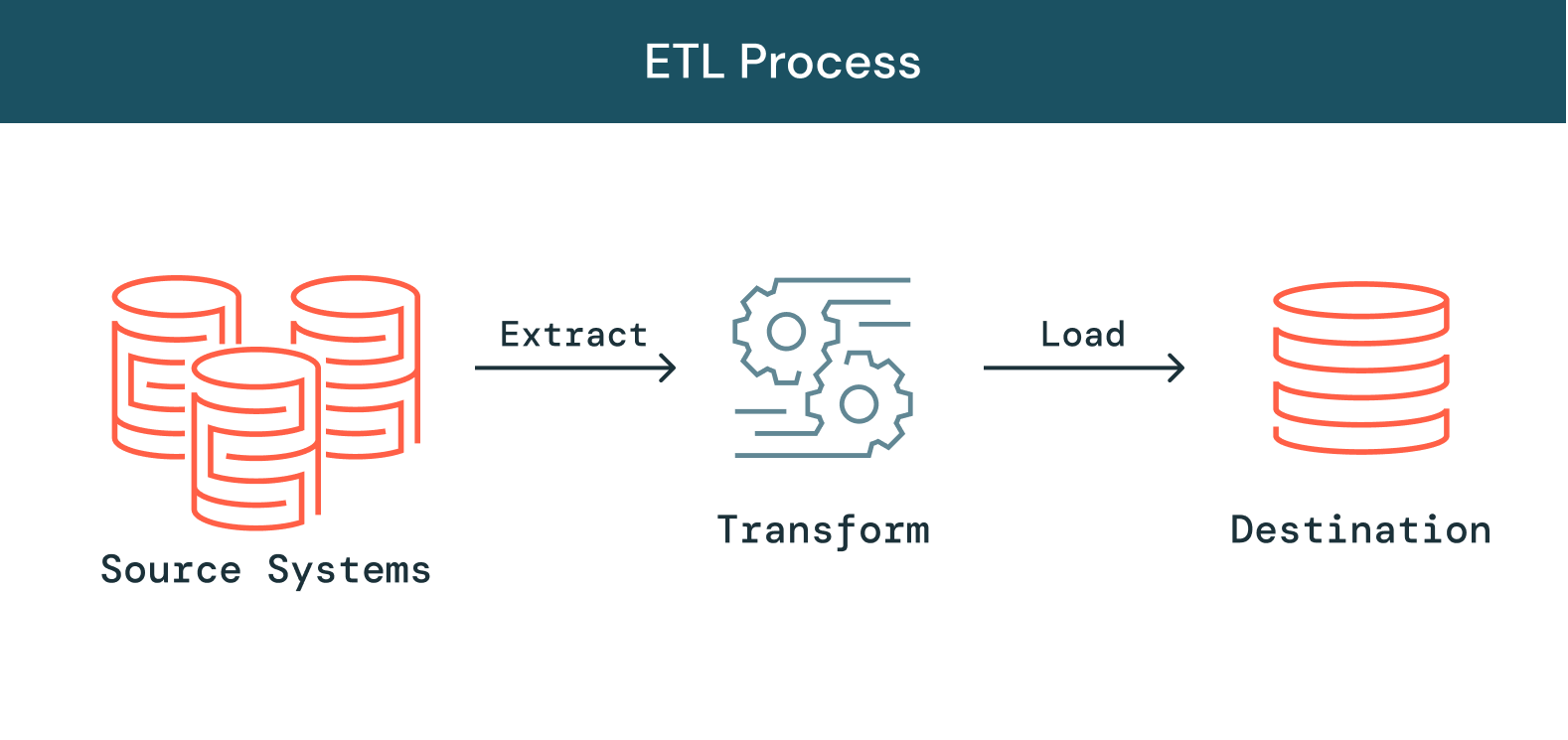
Extract Transform Load (ETL)

What is ETL?
As the amount of data, data sources, and data types at organizations grow, the importance of making use of that data in analytics, data science and machine learning initiatives to derive business insights grows as well. The need to prioritize these initiatives puts increasing pressure on the data engineering teams because processing the raw, messy data into clean, fresh, reliable data is a critical step before these initiatives can be pursued. ETL, which stands for extract, transform, and load, is the process data engineers use to extract data from different sources, transform the data into a usable and trusted resource, and load that data into the systems end-users can access and use downstream to solve business problems.
Here’s more to explore



How does ETL work?
Extract
The first step of this process is extracting data from the target sources that are usually heterogeneous such as business systems, APIs, sensor data, marketing tools, and transaction databases, and others. As you can see, some of these data types are likely to be the structured outputs of widely used systems, while others are semi-structured JSON server logs. There are different ways to perform the extraction:
- Partial Extraction: The easiest way to obtain the data is if the source system notifies you when a record has been changed.
- Partial Extraction (with update notification): Not all systems can provide a notification in case an update has taken place; however, they can point to those records that have been changed and provide an extract of such records.
- Full extract: There are certain systems that cannot identify which data has been changed at all. In this case, a full extract is the only possibility to extract the data out of the system. This method requires having a copy of the last extract in the same format so you can identify the changes that have been made.
Transform
The second step consists of transforming the raw data that has been extracted from the sources into a format that can be used by different applications. In this stage, data gets cleansed, mapped and transformed, often to a specific schema, so it meets operational needs. This process entails several types of transformation that ensure the quality and integrity of data Data is not usually loaded directly into the target data source, but instead it is common to have it uploaded into a staging database. This step ensures a quick roll back in case something does not go as planned. During this stage, you have the possibility to generate audit reports for regulatory compliance, or diagnose and repair any data issues.
Load
Finally, the load function is the process of writing converted data from a staging area to a target database, which may or may not have previously existed. Depending on the requirements of the application, this process may be either quite simple or intricate. Each of these steps can be done with ETL tools or custom code.
What is an ETL pipeline?
An ETL pipeline (or data pipeline) is the mechanism by which ETL processes occur. Data pipelines are a set of tools and activities for moving data from one system with its method of data storage and processing to another system in which it can be stored and managed differently. Moreover, pipelines allow for automatically getting information from many disparate sources, then transforming and consolidating it in one high-performing data storage.
Challenges with ETL
While ETL is essential, with this exponential increase in data sources and types, building and maintaining reliable data pipelines has become one of the more challenging parts of data engineering. From the start, building pipelines that ensure data reliability is slow and difficult. Data pipelines are built with complex code and limited reusability. A pipeline built in one environment cannot be used in another, even if the underlying code is very similar, meaning data engineers are often the bottleneck and tasked with reinventing the wheel every time. Beyond pipeline development, managing data quality in increasingly complex pipeline architectures is difficult. Bad data is often allowed to flow through a pipeline undetected, devaluing the entire data set. To maintain quality and ensure reliable insights, data engineers are required to write extensive custom code to implement quality checks and validation at every step of the pipeline. Finally, as pipelines grow in scale and complexity, companies face increased operational load managing them which makes data reliability incredibly difficult to maintain. Data processing infrastructure has to be set up, scaled, restarted, patched, and updated - which translates to increased time and cost. Pipeline failures are difficult to identify and even more difficult to solve - due to lack of visibility and tooling. Regardless of all of these challenges, reliable ETL is an absolutely critical process for any business that hopes to be insights-driven. Without ETL tools that maintain a standard of data reliability, teams across the business are required to blindly make decisions without reliable metrics or reports. To continue to scale, data engineers need tools to streamline and democratize ETL, making the ETL lifecycle easier, and enabling data teams to build and leverage their own data pipelines in order to get to insights faster.
Automate reliable ETL on Delta Lake
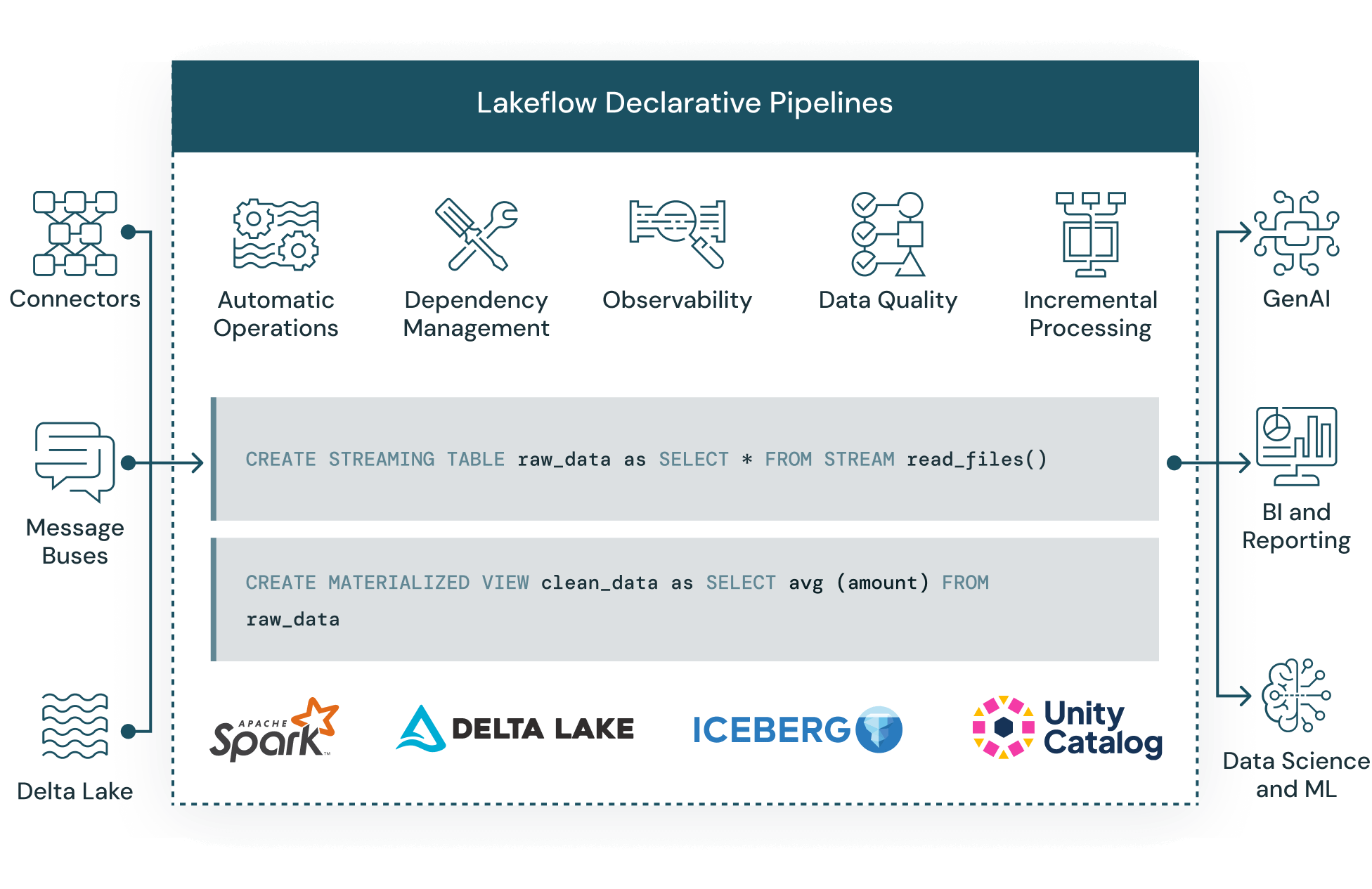
Spark Declarative Pipelines makes it easy to build and manage reliable data pipelines that deliver high quality data on Delta Lake. It helps data engineering teams simplify ETL development and management with declarative pipeline development, automatic testing, and deep visibility for monitoring and recovery.