What is a Hadoop Ecosystem?
A comprehensive suite of open-source tools including HDFS, MapReduce, YARN, Hive, and Spark that work together to store, process, and analyze massive datasets
- The Hadoop ecosystem is a collection of open source projects built around Hadoop to store, process and manage big data.
- Key components include HDFS for storage, YARN for resource management and tools like Hive, Pig, Spark and Kafka for querying and streaming.
- While newer cloud native platforms and lakehouses have reduced reliance on classic Hadoop stacks, the ecosystem shaped many of the patterns used in modern data architectures.

What is the Hadoop Ecosystem?
Apache Hadoop ecosystem refers to the various components of the Apache Hadoop software library; it includes open source projects as well as a complete range of complementary tools. Some of the most well-known tools of the Hadoop ecosystem include HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Oozie, Sqoop, Zookeeper, etc. Here are the major Hadoop ecosystem components that are used frequently by developers:
What is HDFS?
Hadoop Distributed File System (HDFS), is one of the largest Apache projects and primary storage system of Hadoop. It employs a NameNode and DataNode architecture. It is a distributed file system able to store large files running over the cluster of commodity hardware.
What is Hive?
Hive is an ETL and Data warehousing tool used to query or analyze large datasets stored within the Hadoop ecosystem. Hive has three main functions: data summarization, query, and analysis of unstructured and semi-structured data in Hadoop. It features a SQL-like interface, HQL language that works similar to SQL and automatically translates queries into MapReduce jobs.
What is Apache Pig?
This is a high-level scripting language used to execute queries for larger datasets that are used within Hadoop. Pig's simple SQL-like scripting language is known as Pig Latin and its main objective is to perform the required operations and arrange the final output in the desired format.
The agentic AI playbook for the enterprise

What is MapReduce?

This is another data processing layer of Hadoop. It has the capability to process large structured and unstructured data as well as to manage very large data files in parallel by dividing the job into a set of independent tasks (sub-job).
What is YARN?
YARN stands for Yet Another Resource Negotiator, but it's commonly referred to by the acronym alone. It is one of the core components in open source Apache Hadoop suitable for resource management. It is responsible for managing workloads, monitoring, and security controls implementation. It also allocates system resources to the various applications running in a Hadoop cluster while assigning which tasks should be executed by each cluster nodes. YARN has two main components:
- Resource Manager
- Node Manager
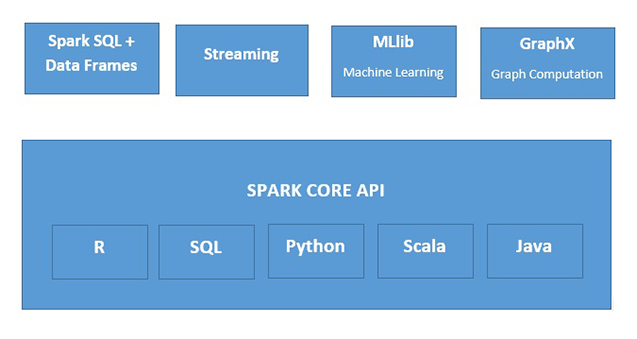
What is Apache Spark?
Apache Spark is a fast, in-memory data processing engine suitable for use in a wide range of circumstances. Spark can be deployed in several ways, it features Java, Python, Scala, and R programming languages, and supports SQL, streaming data, machine learning, and graph processing, which can be used together in an application.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.