What is Tensorflow Estimator API?
TensorFlow's high-level API for model training, evaluation, and prediction, simplifying distributed ML without managing computational graphs or sessions
- The TensorFlow Estimator API is a high level interface that represents a complete model and provides simple methods to train, evaluate and generate predictions.
- Estimators support both pre made models and custom models, and they can run on local machines or distributed environments across CPUs, GPUs and TPUs without changing your model code.
- The API handles many training details for you, such as checkpointing, recovering from failures and creating TensorBoard summaries, so teams can share implementations and focus more on model design.
What is the Tensorflow Estimator API?
Estimators represent a complete model but also look intuitive enough to less user. The Estimator API provides methods to train the model, to judge the model’s accuracy, and to generate predictions. TensorFlow provides a programming stack consisting of multiple API layers like in the below image:
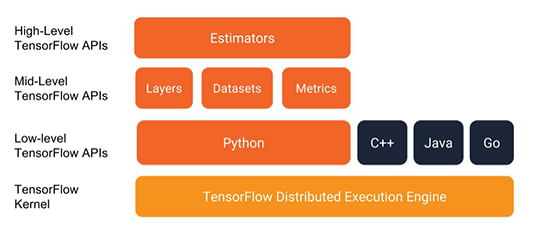
There are two types of estimators; you can either choose the pre-made Estimators, alternatively, you can write your own custom Estimators. Estimators-based models can be run on local hosts as well as on distributed multi-server environment without changing your model. In addition, you can run Estimators-based models on CPUs, GPUs, or TPUs without having to record your model.
Estimators Encapsulate Four Main Features:
- Training- they will train a model on a given input for a fixed number of steps
- Evaluation- they will evaluate the model based on a test set.
- Prediction- estimators will run inference using the trained model.
- Export your model for serving.
On top of that, the Estimator includes default behavior common to training jobs, such as saving and restoring checkpoints, creating summaries, etc. An Estimator will require you to write a model_fn and an input_fn that correspond to the model and input portions of your TensorFlow graph.
The agentic AI playbook for the enterprise

Estimators Come with Numerous Benefits:
- Estimators simplify sharing implementations between model developers.
- You can develop a great model with high-level intuitive code, as they usually are easier to use if you need to create models compared to the low-level TensorFlow APIs.
- Estimators are themselves built on tf.keras.layers, that makes customization a lot easier.
- Estimators will make your life easier by building the graph for you.
- Estimators provide a safely distributed training loop that controls how and when to:
- build the graph
- initialize variables
- load data
- handle exceptions
- create checkpoint files and recover from failures
- save summaries for TensorBoard
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.