What are Spark Applications?
Learn how driver and executor processes work together to run distributed computations on a cluster
- Spark applications are programs that use a Spark cluster to process data in parallel across multiple machines. Each Spark application consists of a driver that coordinates work and executors that run tasks on distributed data. Teams use Spark applications for workloads like ETL, SQL analytics, streaming and machine learning on large datasets.
Spark Applications consist of a driver process and a set of executor processes. The driver process runs your main() function, sits on a node in the cluster, and is responsible for three things: maintaining information about the Spark Application; responding to a user’s program or input; and analyzing, distributing, and scheduling work across the executors (defined momentarily). The driver process is absolutely essential - it’s the heart of a Spark Application and maintains all relevant information during the lifetime of the application. The executors are responsible for actually executing the work that the driver assigns them. This means, each executor is responsible for only two things: executing code assigned to it by the driver and reporting the state of the computation, on that executor, back to the driver node.
The agentic AI playbook for the enterprise

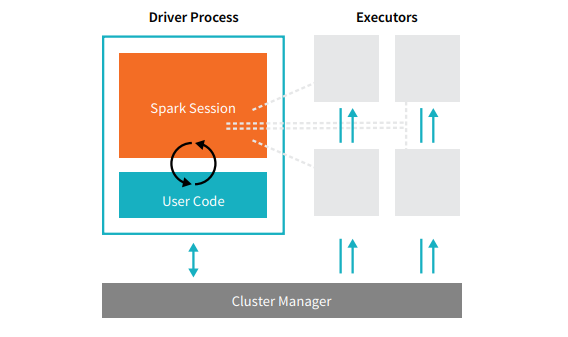
The cluster manager controls physical machines and allocates resources to Spark Applications. This can be one of several core cluster managers: Spark’s standalone cluster manager, YARN, or Mesos. This means that there can be multiple Spark Applications running on a cluster at the same time. We will talk more in depth about cluster managers in Part IV: Production Applications of this book. In the previous illustration we see on the left, our driver and on the right the four executors on the right. In this diagram, we removed the concept of cluster nodes. The user can specify how many executors should fall on each node through configurations. [glossary-cta]
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.