What is Apache Spark?
A unified analytics engine for large-scale distributed data processing with APIs in Java, Scala, Python, and R for batch, streaming, ML, and graphs
- Apache Spark is an open source, distributed computing engine designed for fast processing of large scale data across clusters of machines.
- Apache Spark supports multiple workloads including batch processing, SQL, streaming, machine learning and graph analytics through a unified engine.
- Spark provides APIs in languages such as Python, SQL, Scala and Java so developers and analysts can work with big data using familiar tools.
What Is Apache Spark?
Apache Spark is an open source analytics engine used for big data workloads. It can handle both batches as well as real-time analytics and data processing workloads. Apache Spark started in 2009 as a research project at the University of California, Berkeley. Researchers were looking for a way to speed up processing jobs in Hadoop systems. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. Spark provides native bindings for the Java, Scala, Python, and R programming languages. In addition, it includes several libraries to support build applications for machine learning [MLlib], stream processing [Spark Streaming], and graph processing [GraphX]. Apache Spark consists of Spark Core and a set of libraries. Spark Core is the heart of Apache Spark and it is responsible for providing distributed task transmission, scheduling, and I/O functionality. The Spark Core engine uses the concept of a Resilient Distributed Dataset (RDD) as its basic data type. The RDD is designed so it will hide most of the computational complexity from its users. Spark is intelligent on the way it operates on data; data and partitions are aggregated across a server cluster, where it can then be computed and either moved to a different data store or run through an analytic model. You will not be asked to specify the destination of the files or the computational resources that need to be used in order to store or retrieve files. 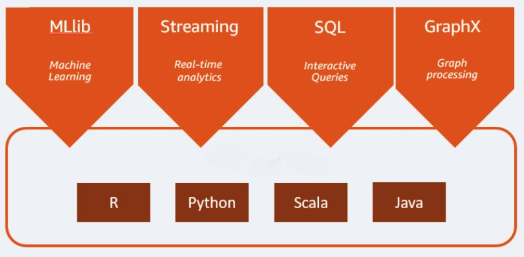
The agentic AI playbook for the enterprise

What Are the Benefits of Apache Spark?
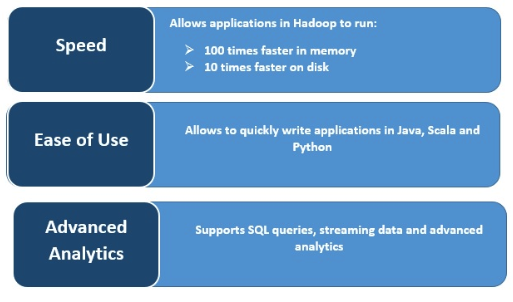
Speed
Spark executes very fast by caching data in memory across multiple parallel operations. The main feature of Spark is its in-memory engine that increases the processing speed; making it up to 100 times faster than MapReduce when processed in-memory, and 10 times faster on disk, when it comes to large scale data processing. Spark makes this possible by reducing the number of reading/writing to disk operations.
Real-time stream processing
Apache Spark can handle real-time streaming along with the integration of other frameworks. Spark ingests data in mini-batches and performs RDD transformations on those mini-batches of data.
Supports Multiple Workloads
Apache Spark can run multiple workloads, including interactive queries, real-time analytics, machine learning, and graph processing. One application can combine multiple workloads seamlessly.
Increased Usability
The ability to support several programming languages makes it dynamic. It allows you to quickly write applications in Java, Scala, Python, and R; giving you a variety of languages for building your applications.
Advanced Analytics
Spark supports SQL queries, machine learning, stream processing, and graph processing.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.