What is Spark Streaming?
How Spark Streaming processes micro-batches of real-time data with DStreams and why Structured Streaming is now the preferred engine
- Spark Streaming is the earlier streaming engine in Apache Spark that processes real time data as micro batches using DStreams.
- Spark Streaming extends the core Spark API so teams can read from sources such as Kafka, Flume or Amazon Kinesis and push processed results to files, databases or dashboards.
- Spark Streaming unified batch and streaming on one engine, but it is now a legacy project and new streaming applications should use Structured Streaming instead.
Apache Spark Streaming is the previous generation of Apache Spark’s streaming engine. There are no longer updates to Spark Streaming and it’s a legacy project. There is a newer and easier to use streaming engine in Apache Spark called Structured Streaming. You should use Spark Structured Streaming for your streaming applications and pipelines. See Structured Streaming.
What is Spark Streaming?
Apache Spark Streaming is a scalable fault-tolerant streaming processing system that natively supports both batch and streaming workloads. Spark Streaming is an extension of the core Spark API that allows data engineers and data scientists to process real-time data from various sources including (but not limited to) Kafka, Flume, and Amazon Kinesis. This processed data can be pushed out to file systems, databases, and live dashboards. Its key abstraction is a Discretized Stream or, in short, a DStream, which represents a stream of data divided into small batches. DStreams are built on RDDs, Spark’s core data abstraction. This allows Spark Streaming to seamlessly integrate with any other Spark components like MLlib and Spark SQL. Spark Streaming is different from other systems that either have a processing engine designed only for streaming, or have similar batch and streaming APIs but compile internally to different engines. Spark’s single execution engine and unified programming model for batch and streaming lead to some unique benefits over other traditional streaming systems.
The agentic AI playbook for the enterprise

Four Major Aspects of Spark Streaming
- Fast recovery from failures and stragglers
- Better load balancing and resource usage
- Combining of streaming data with static datasets and interactive queries
- Native integration with advanced processing libraries (SQL, machine learning, graph processing)
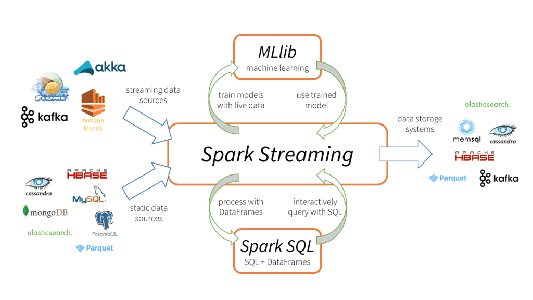
This unification of disparate data processing capabilities is the key reason behind Spark Streaming’s rapid adoption. It makes it very easy for developers to use a single framework to satisfy all their processing needs.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.