Efficient data ingestion into your lakehouse
Take the first step to unlock innovation with data intelligence.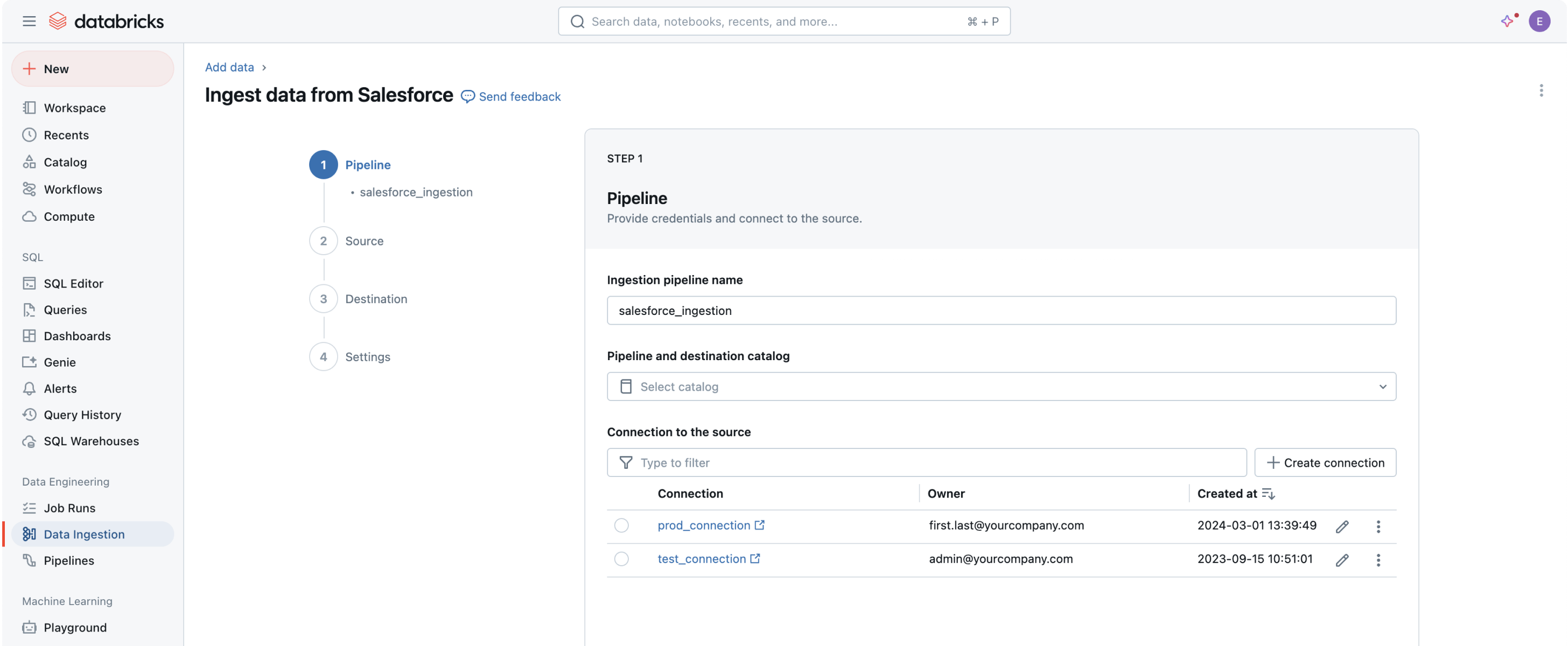
Unlock value from your data in just a few easy steps
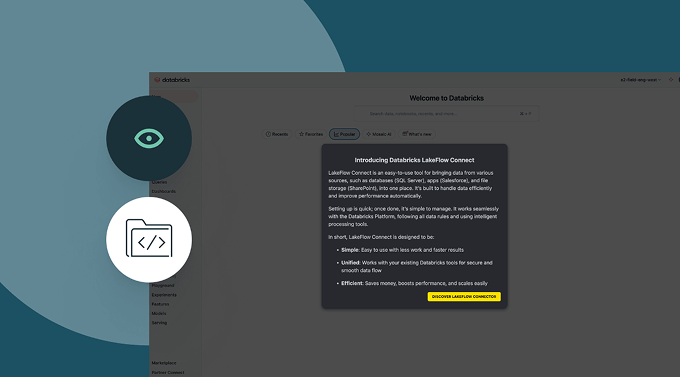
Built-in data connectors are available for popular enterprise applications, file sources and databases.Flexible and easy
Fully managed connectors provide a simple UI and API for easy setup and democratize data access. Automated features also help simplify pipeline maintenance with minimal overhead.
Built-in connectors
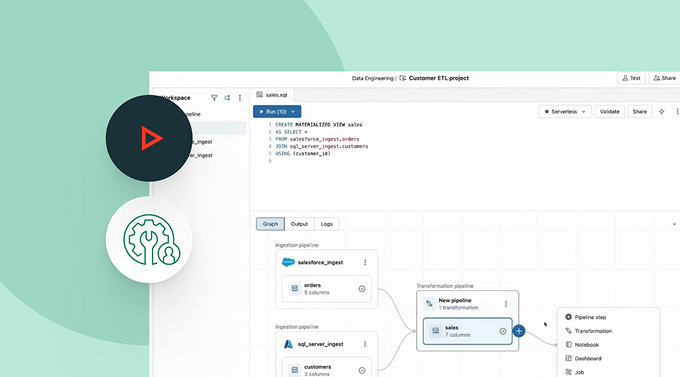
Data ingestion is fully integrated with the Data Intelligence Platform. Create ingestion pipelines with governance from Unity Catalog, observability from Lakehouse Monitoring, and seamless orchestration with workflows for analytics, machine learning and BI.
Efficient ingestion
Increase efficiency and accelerate time to value. Optimized incremental reads and writes and data transformation help improve the performance and reliability of your pipelines, reduce bottlenecks, and reduce impact to the source data for scalability.

Robust ingestion capabilities for popular data sources
Bringing all your data into the Data Intelligence Platform is the first step to extracting value and helping solve your organization’s most challenging data problems.No-code user interface (UI) or a simple API empowers data professionals to self-serve, saving hours of programming.
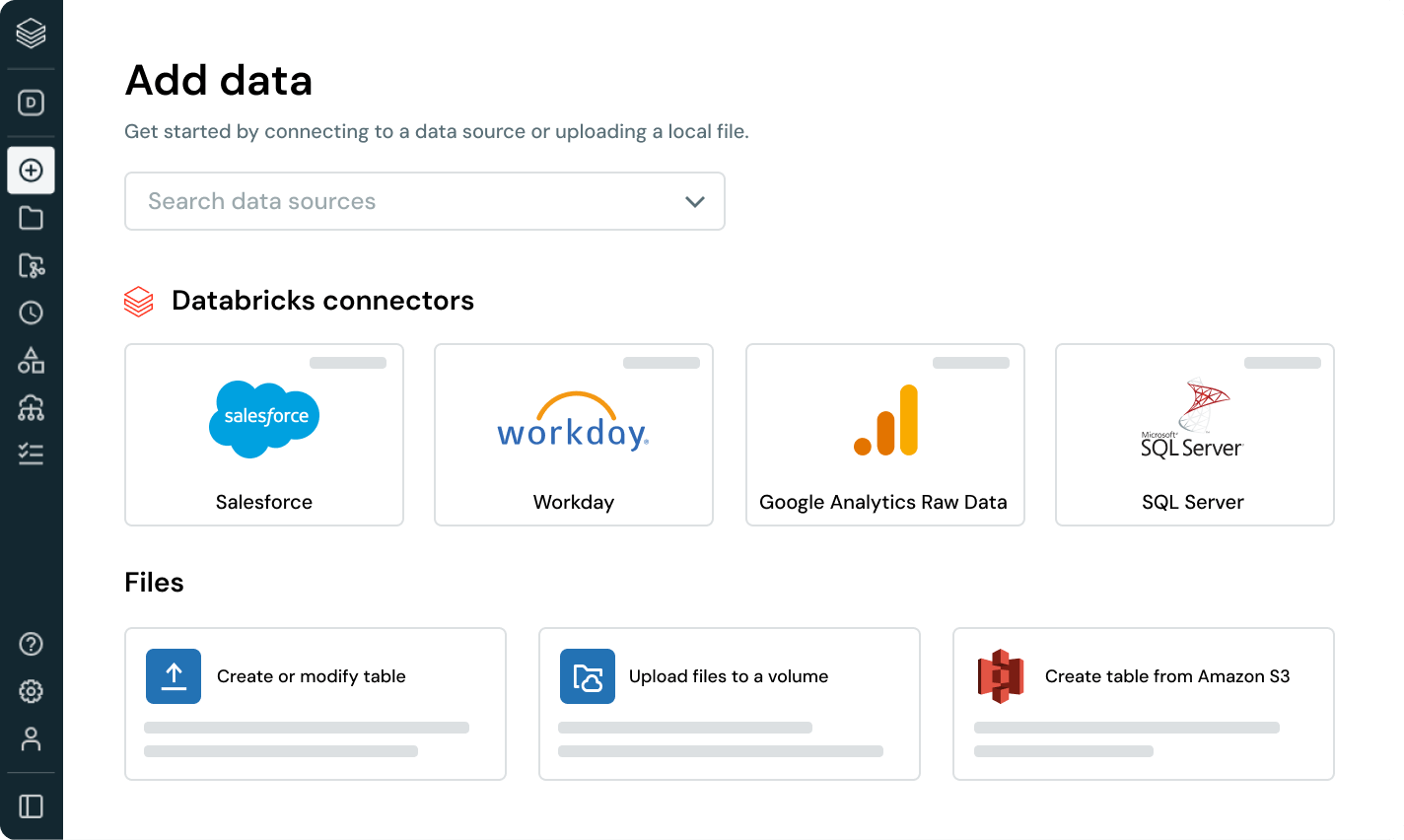



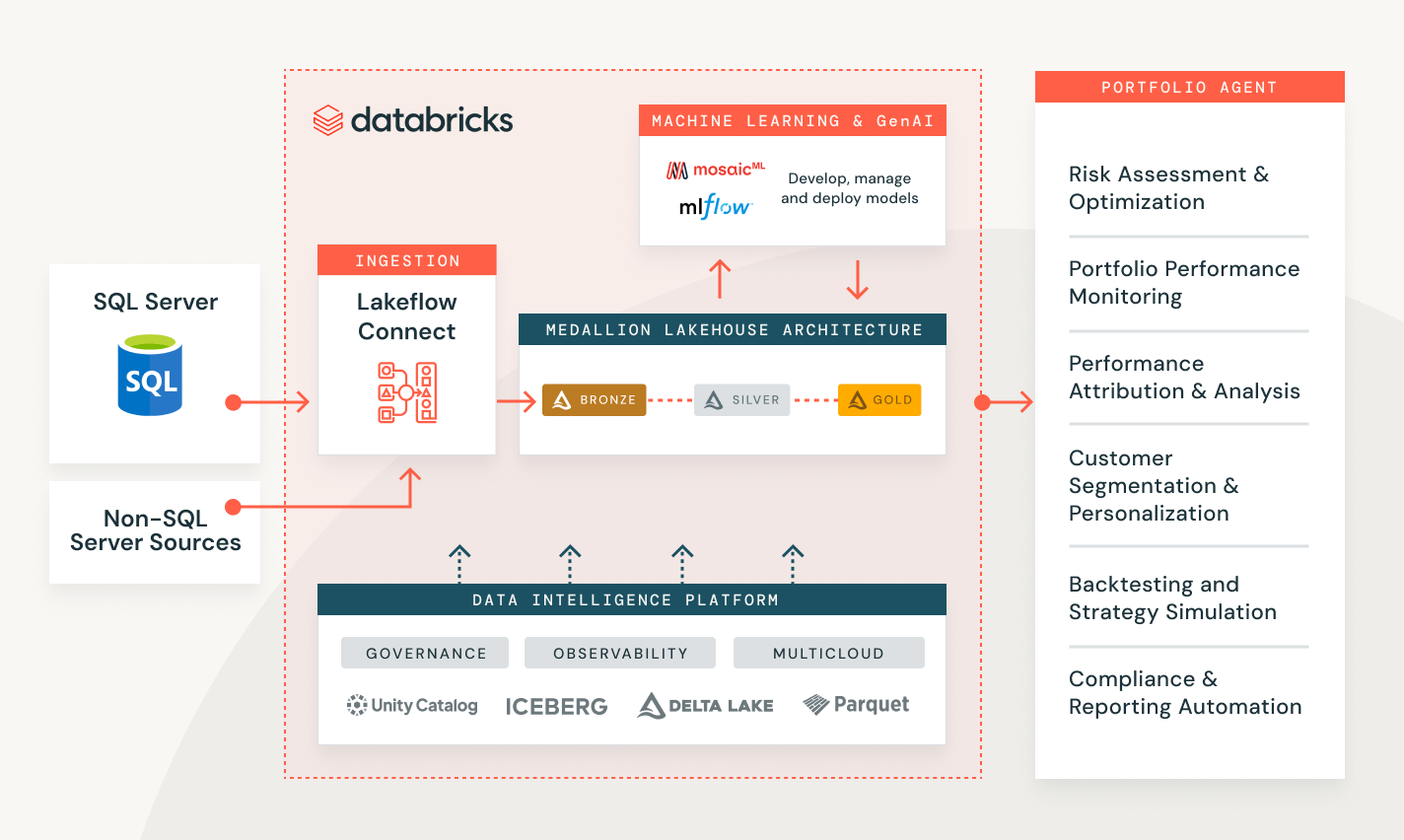
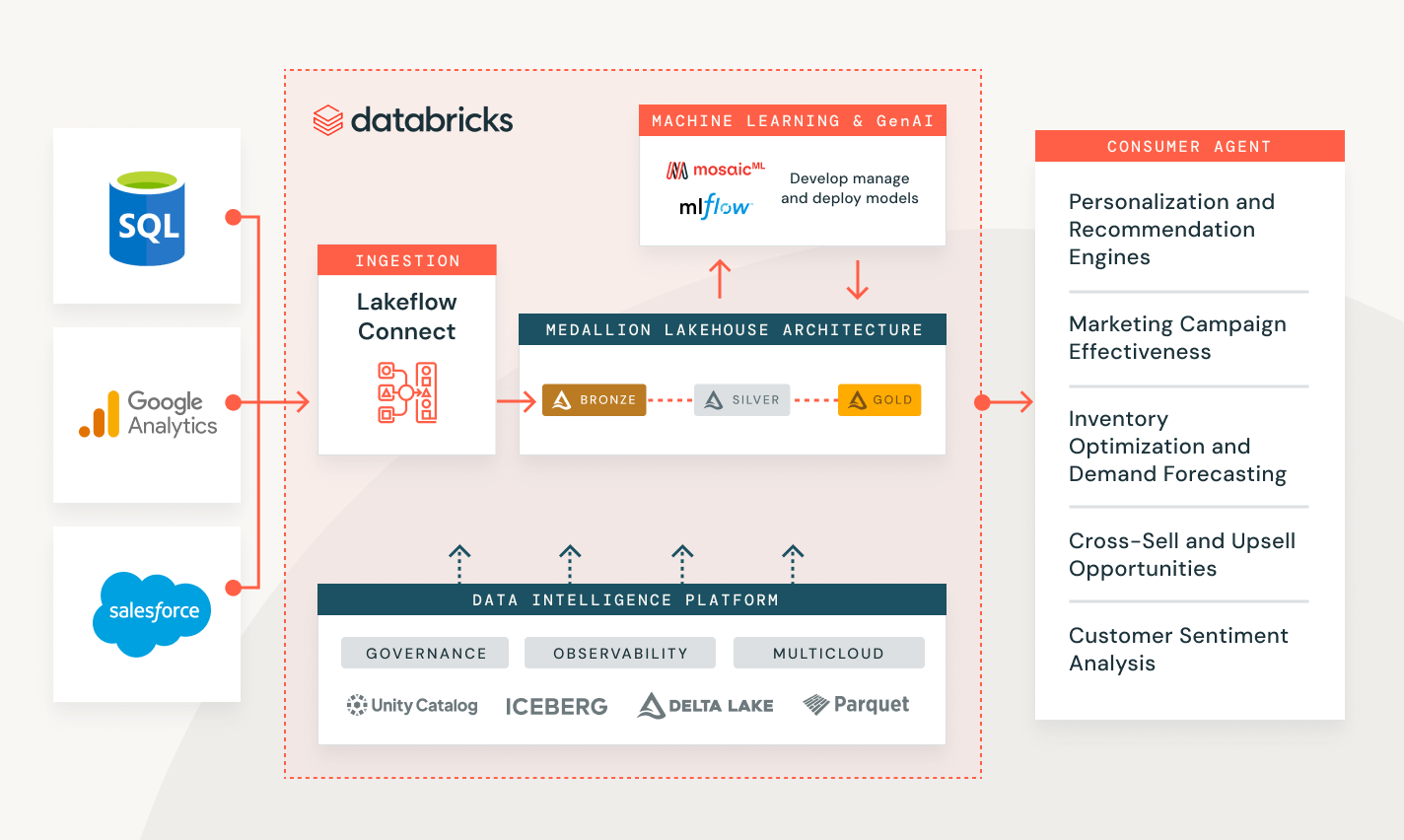
Data ingestion with Databricks
Solving customer problems across a range of industries

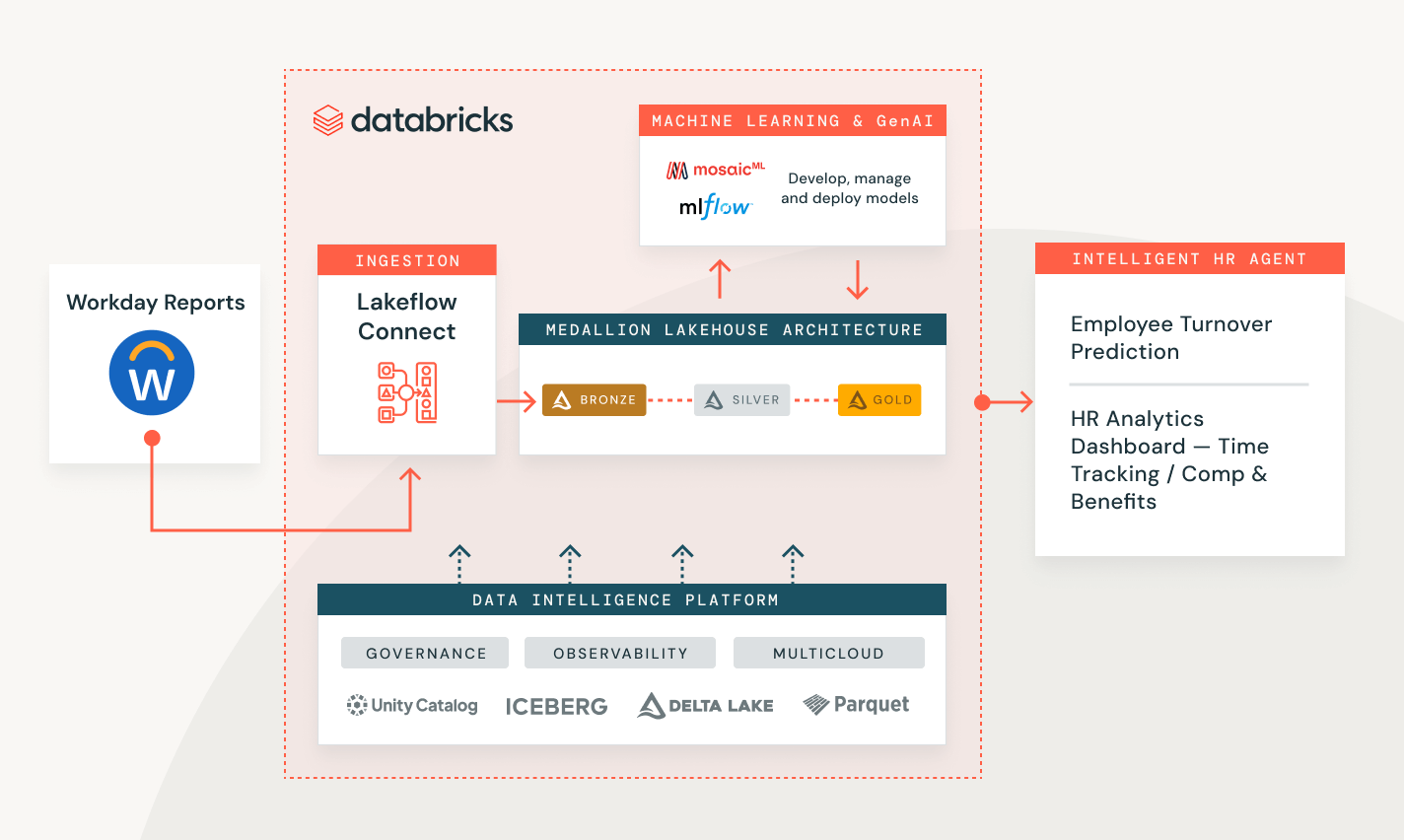
Measure campaign performance and customer lead scoring
Create an end-to-end solution to transform, secure and analyze your customer data and help predict future behavior.
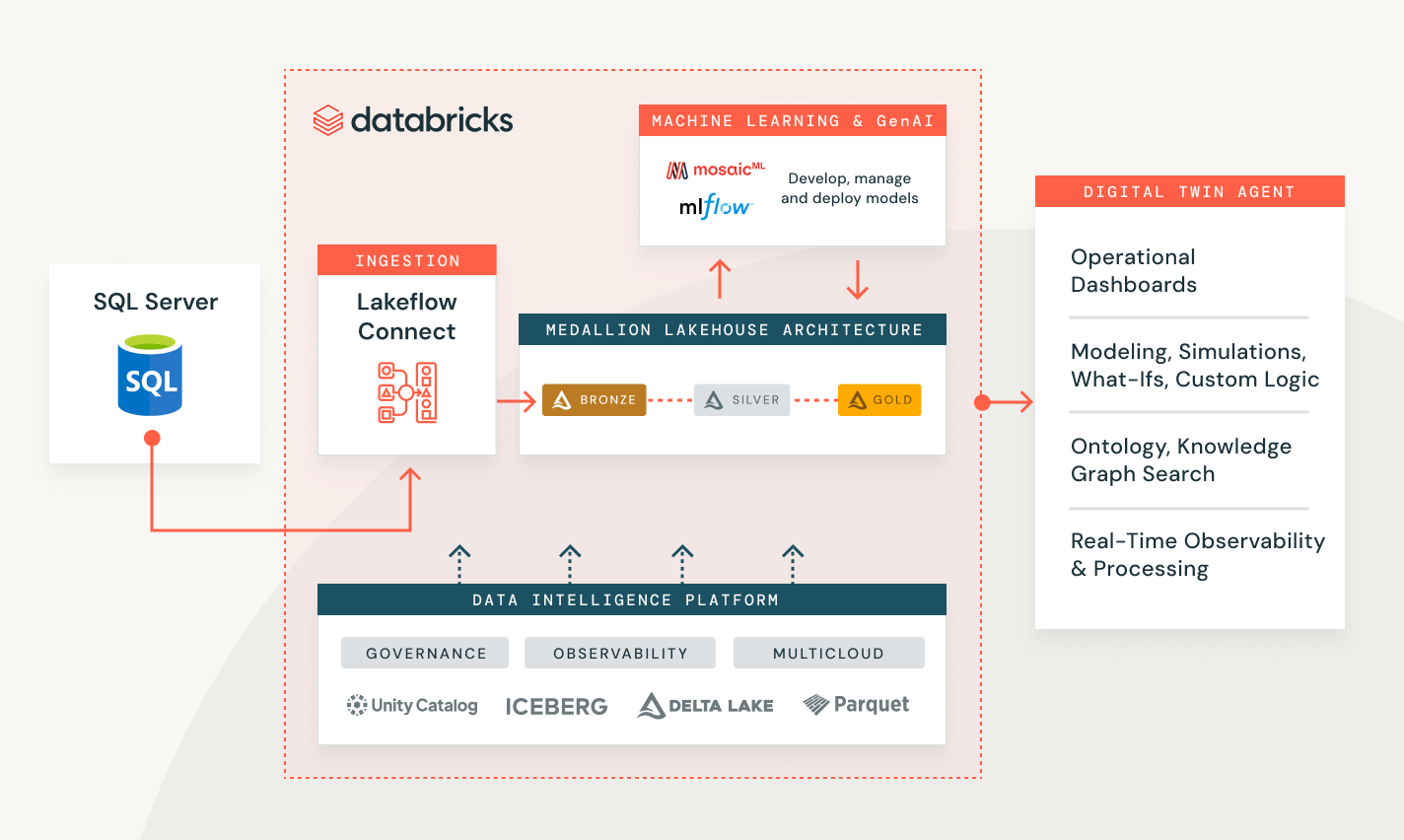


Usage-based pricing keeps spending in check
Only pay for the products you use at per-second granularity.Discover more
Explore other integrated, intelligent offerings on the Data Intelligence Platform.
Lakeflow Jobs
Equip teams to better automate and orchestrate any ETL, analytics, and AI workflow with deep observability, high reliability, and broad task type support.
Spark Declarative Pipelines
Simplify batch and streaming ETL with automated data quality, change data capture (CDC), data ingestion, transformation and unified governance.

Unity Catalog
Seamlessly govern all your data assets with the industry’s only unified and open governance solution for data and AI, built into the Databricks Data Intelligence Platform.

Delta Lake
Unify the data in your lakehouse, across all formats and types, for all your analytics and AI workloads.
Getting Started



Data Ingestion FAQ
Ready to become a data + AI company?
Take the first steps in your data transformation