Reliable data pipelines made easy
Simplify batch and streaming ETL with automated reliability and built-in data quality.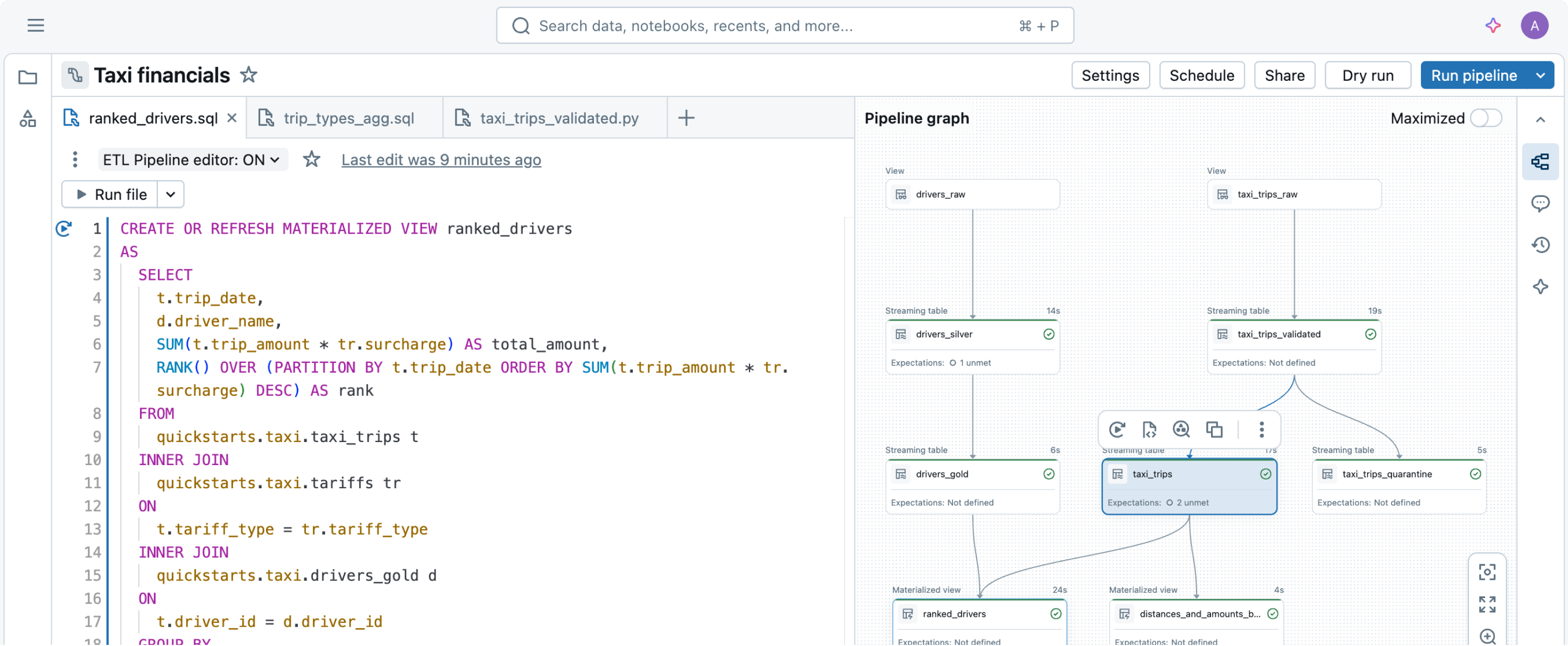
TOP TEAMS SUCCEED WITH INTELLIGENT DATA PIPELINES
Data pipeline best practices, codified
Simply declare the data transformations you need — let Spark Declarative Pipelines handle the rest.Efficient ingestion
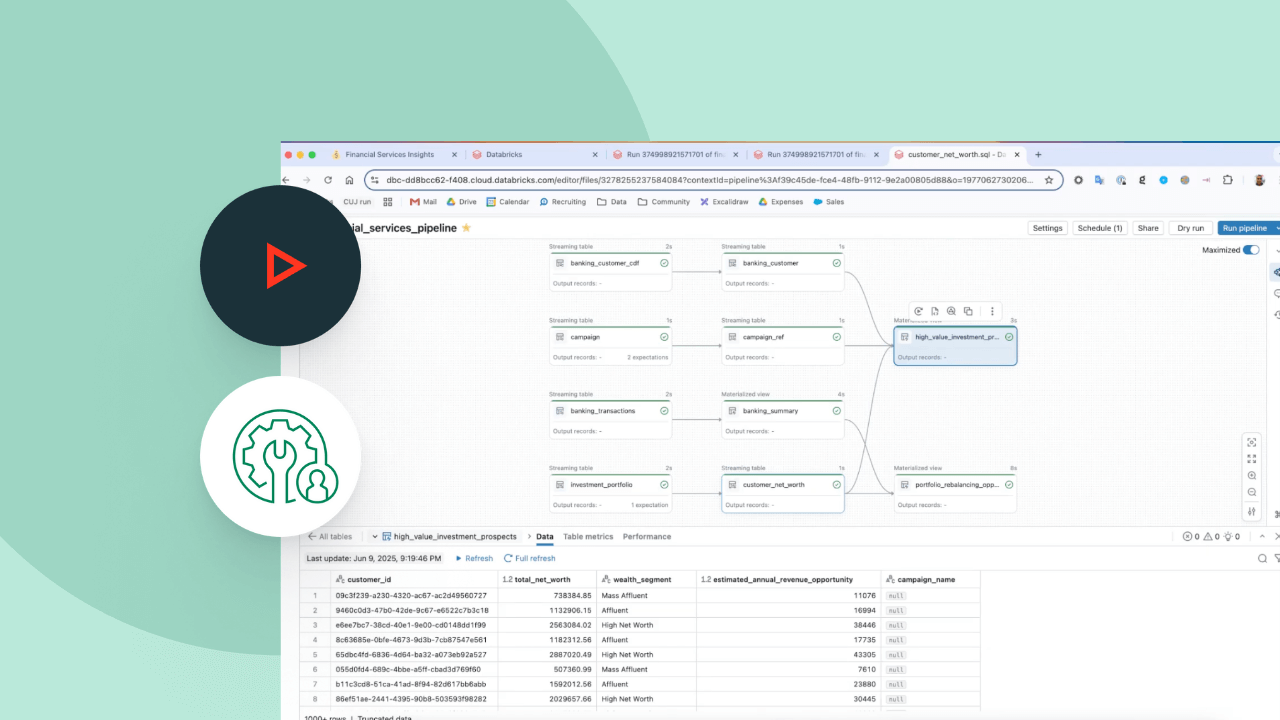
Building production-ready data pipelines starts with ingestion. Spark Declarative Pipelines enables efficient ingestion for data engineers, Python developers, data scientists and SQL analysts. Load data from any Apache Spark™-supported source on Databricks, whether batch, streaming or CDC.
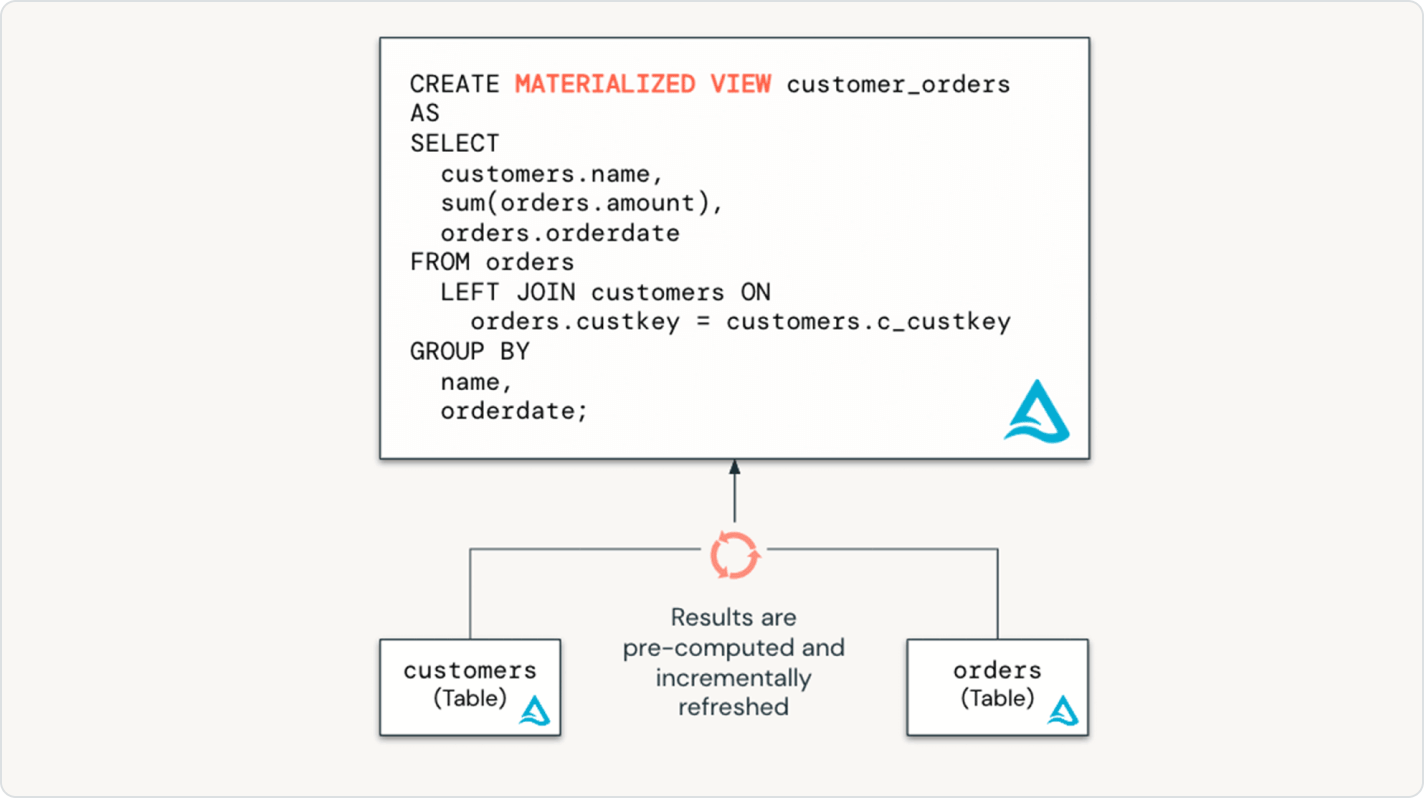
Intelligent transformation
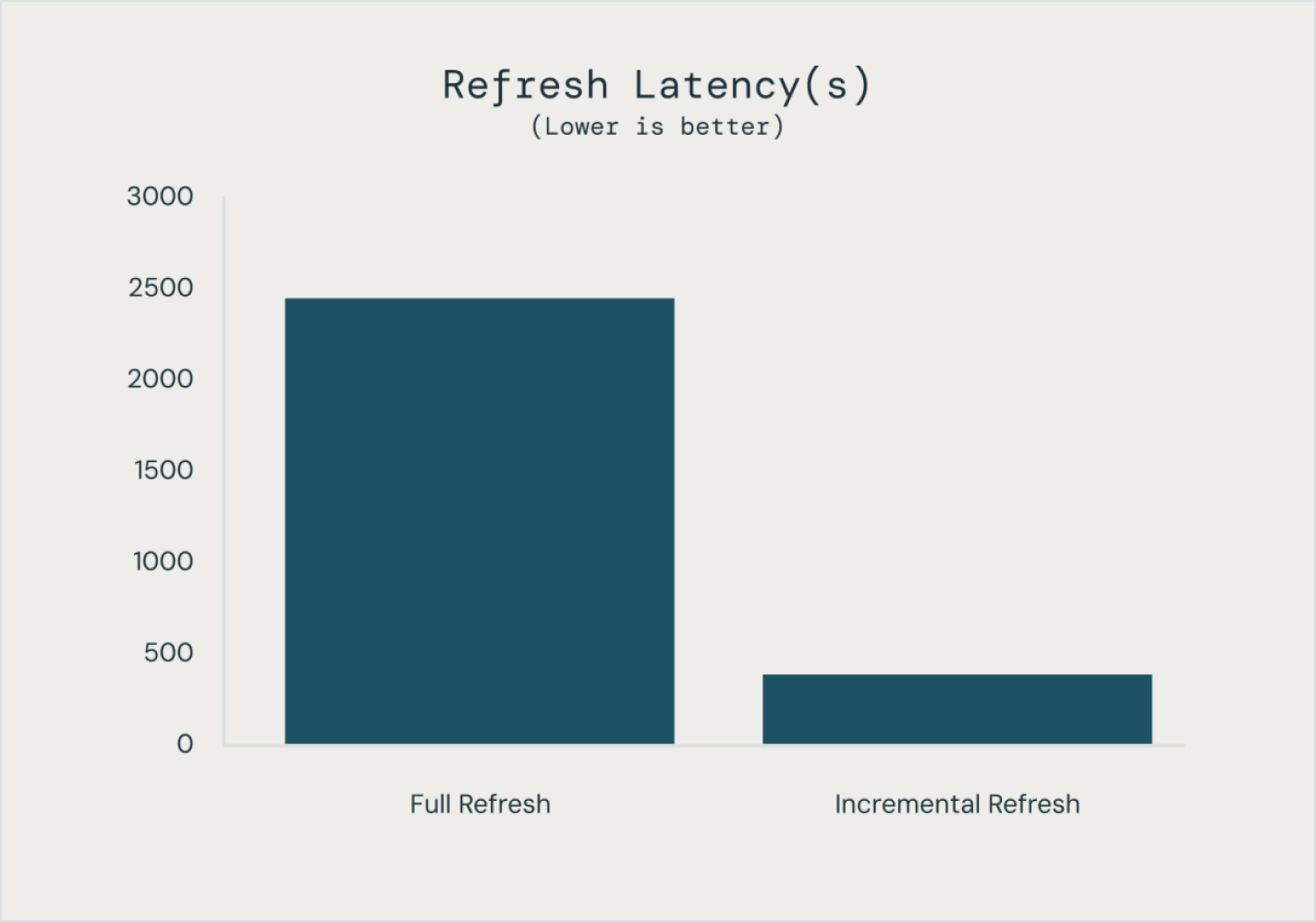
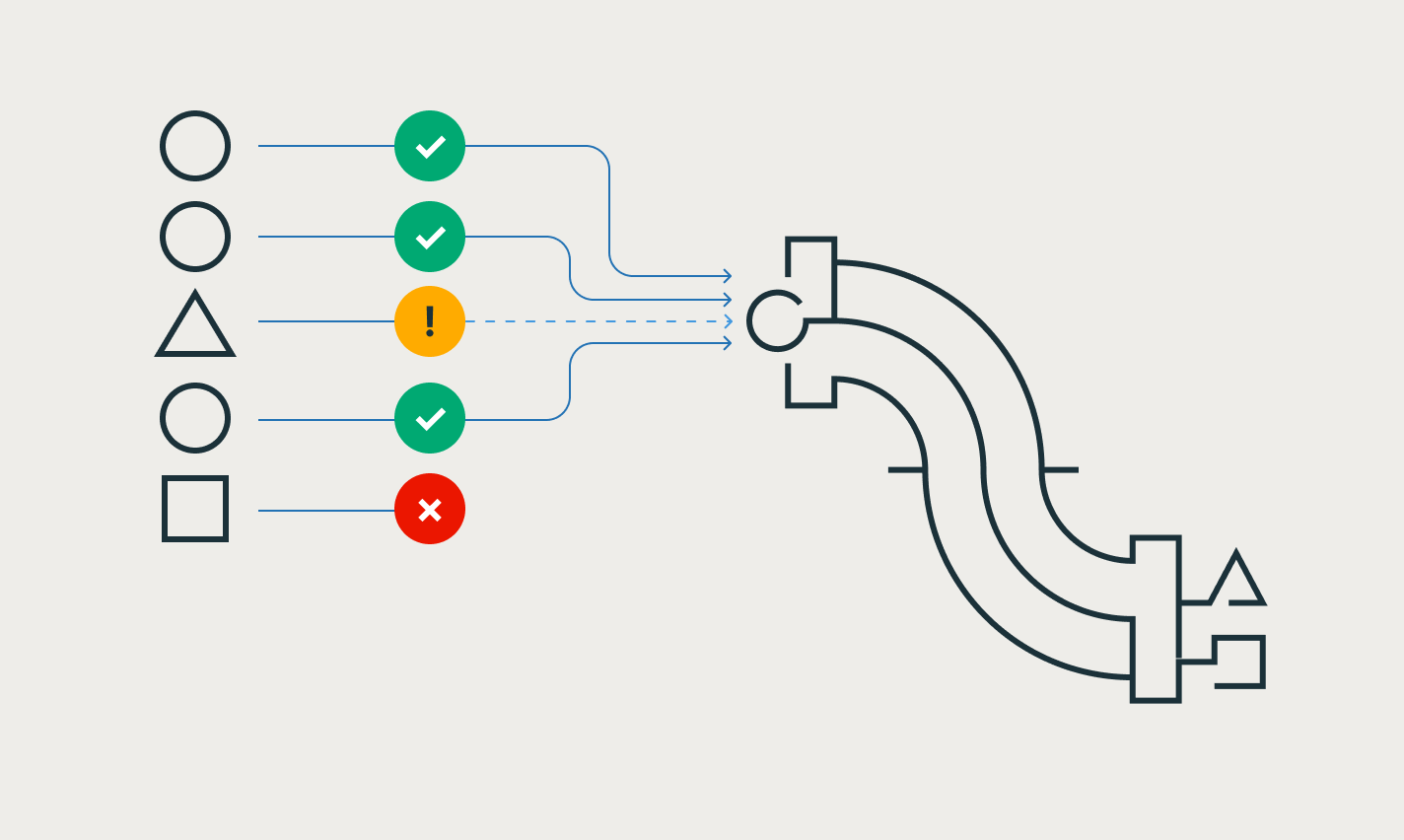
From just a few lines of code, Spark Declarative Pipelines determines the most efficient way to build and execute your batch or streaming data pipelines, automatically optimizing for cost or performance while minimizing complexity.
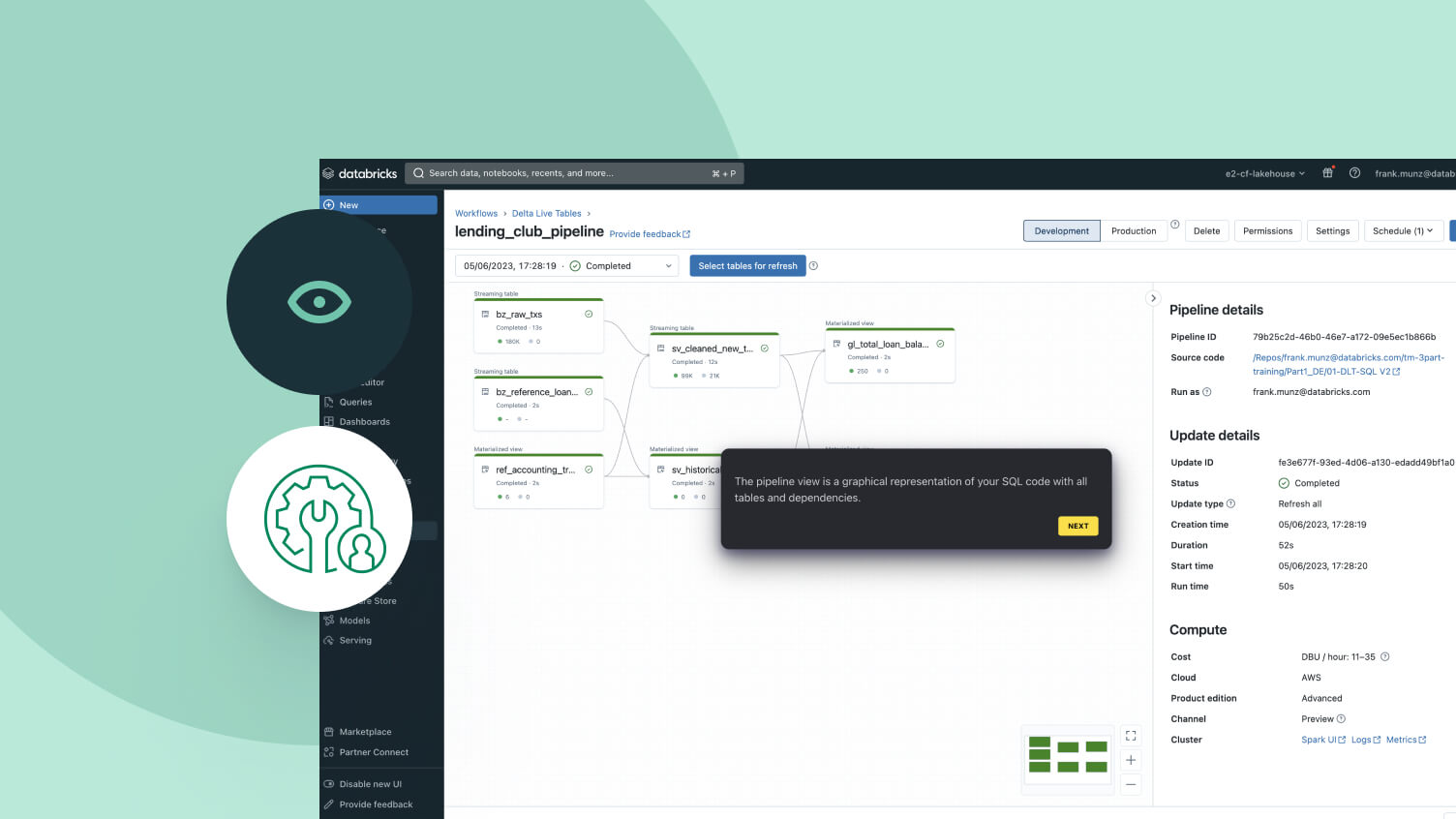
Automated operations
Spark Declarative Pipelines simplifies pipeline development by codifying best practices out of the box, automating dependency management, scaling and recovery, data quality rules and more. With Spark Declarative Pipelines, engineers can focus on delivering high-quality data rather than operating and maintaining pipeline infrastructure.
Built to simplify data pipelining
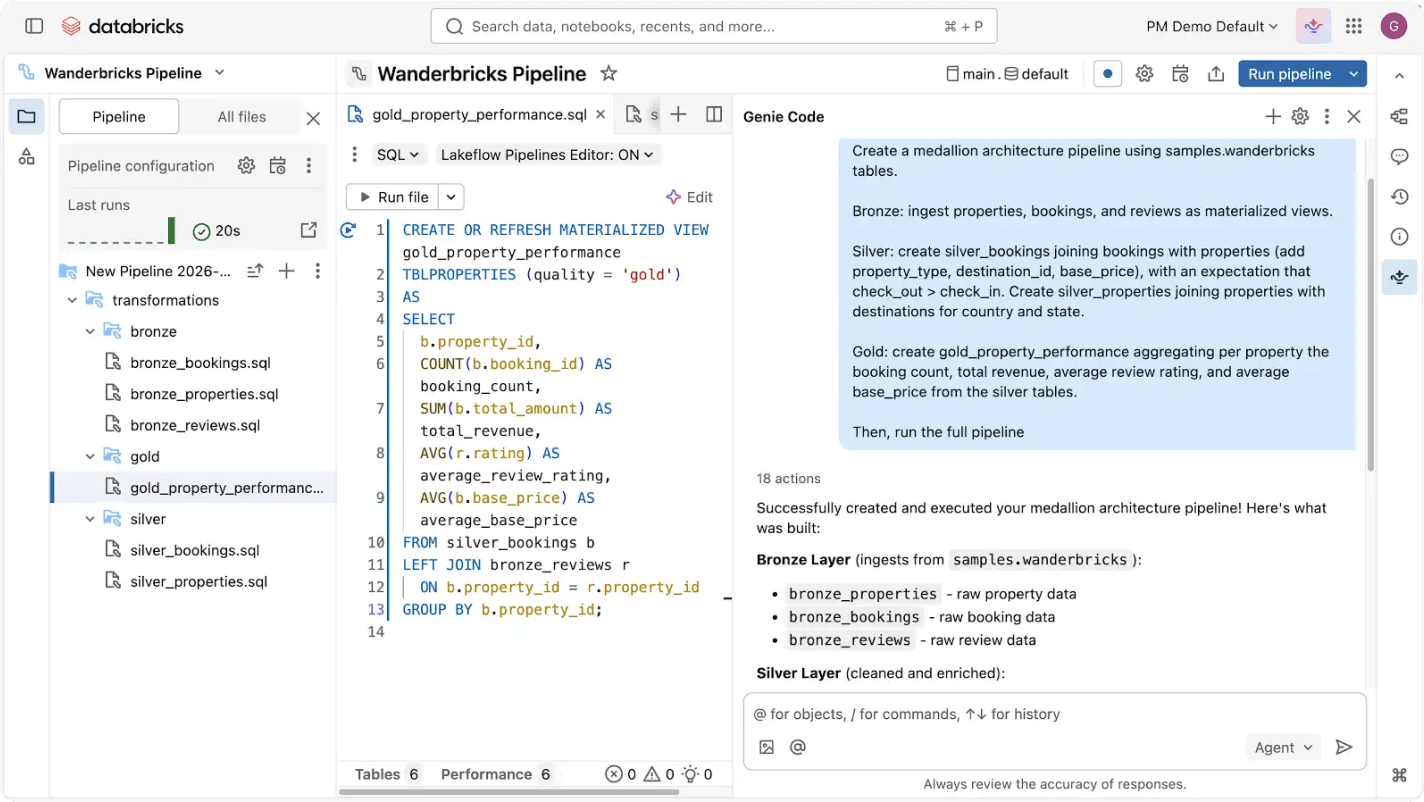
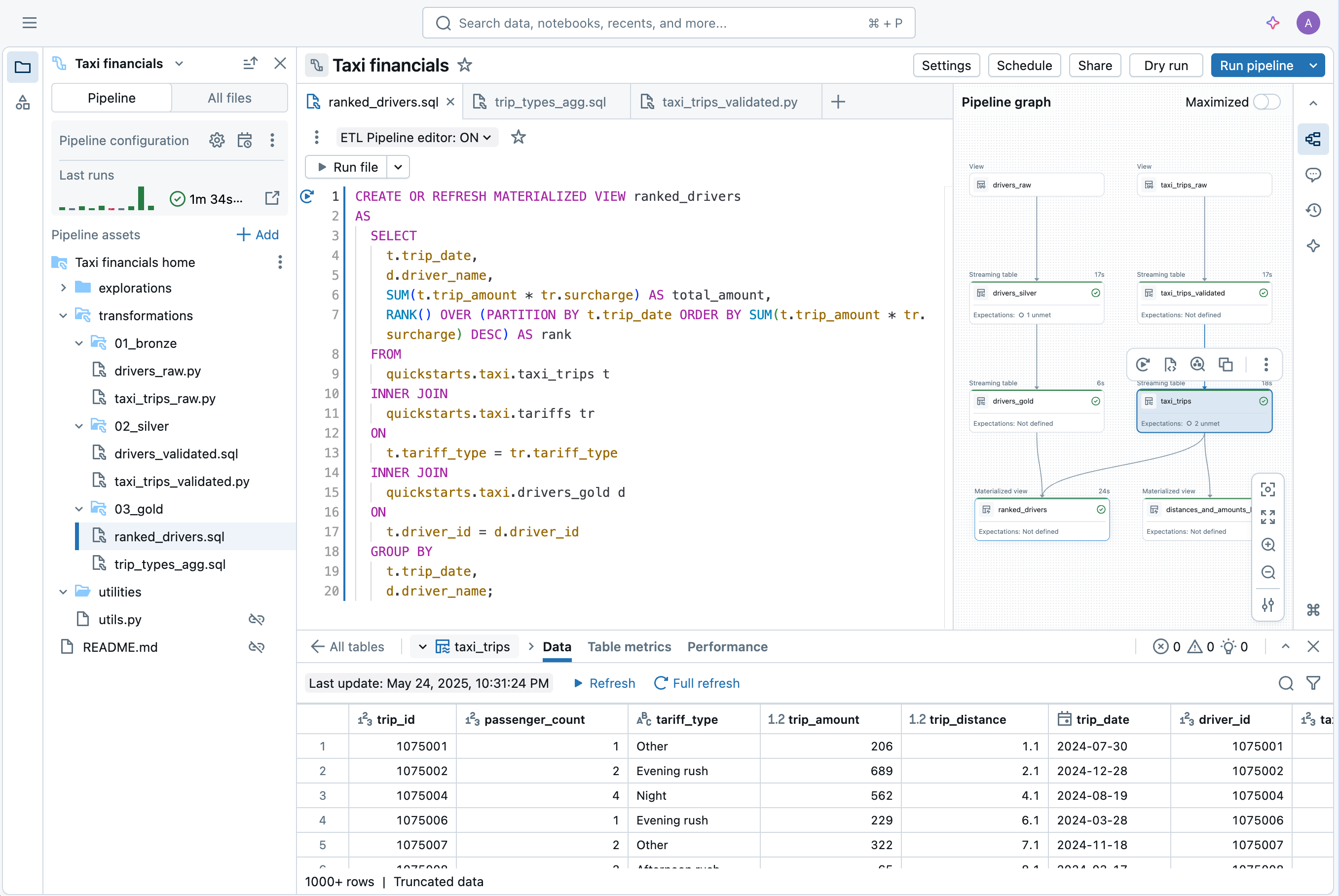
Building and operating data pipelines can be hard — but it doesn’t have to be. Spark Declarative Pipelines is built for powerful simplicity, so you can perform robust ETL with just a few lines of code.Use Genie Code to automate ETL workloads, optimize queries and build pipelines through natural conversation.

More features
Streamline your data pipelines

Make sources, transformations and destinations simple
Declarative programming means you get to harness the power of ETL on Databricks with just a few lines of code.
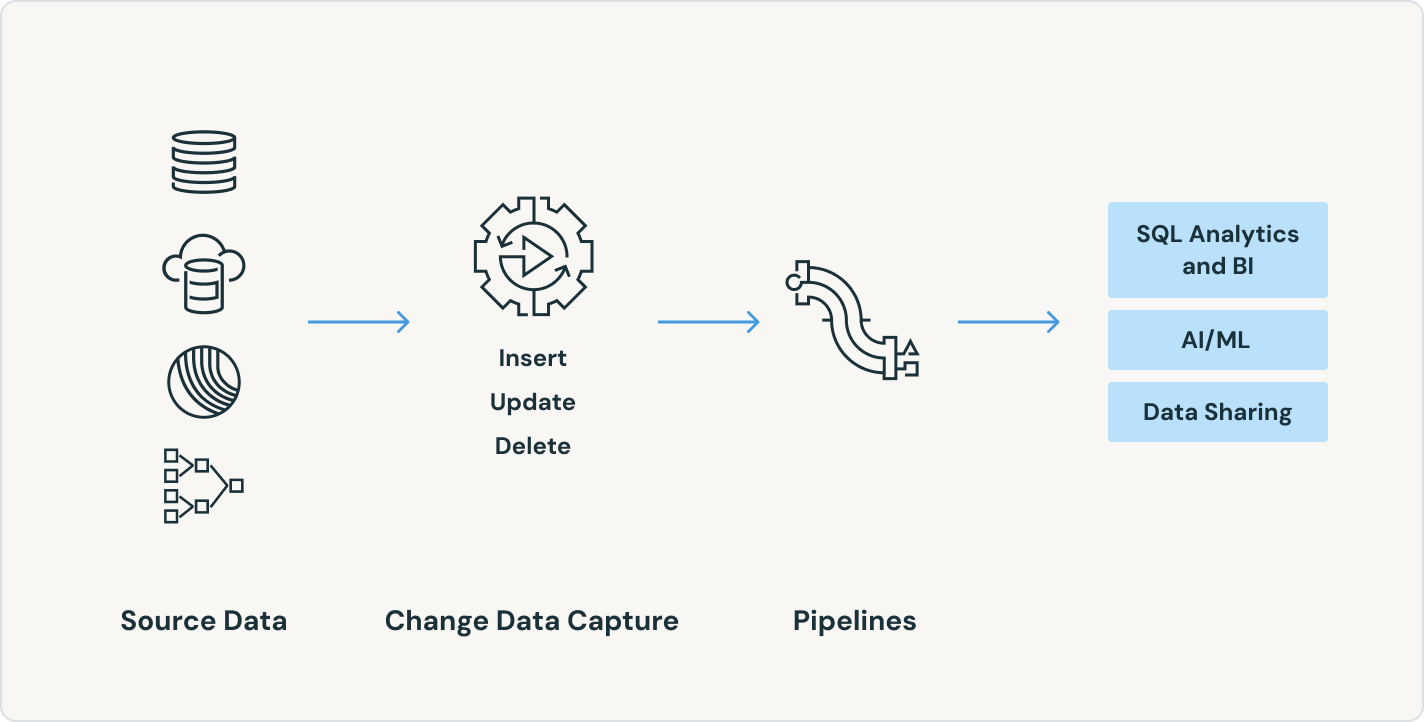
Usage-based pricing keeps spending in check
Only pay for the products you use at per-second granularity.Discover more
Explore other integrated, intelligent offerings on Databricks.
Lakeflow Connect
Efficient data ingestion connectors from any source and native integration with the Data Intelligence Platform unlock easy access to analytics and AI, with unified governance.

Lakeflow Jobs
Easily define, manage and monitor multitask workflows for ETL, analytics and machine learning pipelines. With a wide range of supported task types, deep observability capabilities and high reliability, your data teams are empowered to better automate and orchestrate any pipeline and become more productive.

Genie Code
Your autonomous AI partner for data work.

Lakehouse Storage
Unify the data in your lakehouse, across all formats and types, for all your analytics and AI workloads.

Unity Catalog
Seamlessly govern all your data assets with the industry’s only unified and open governance solution for data and AI, built into the Databricks Data Intelligence Platform.
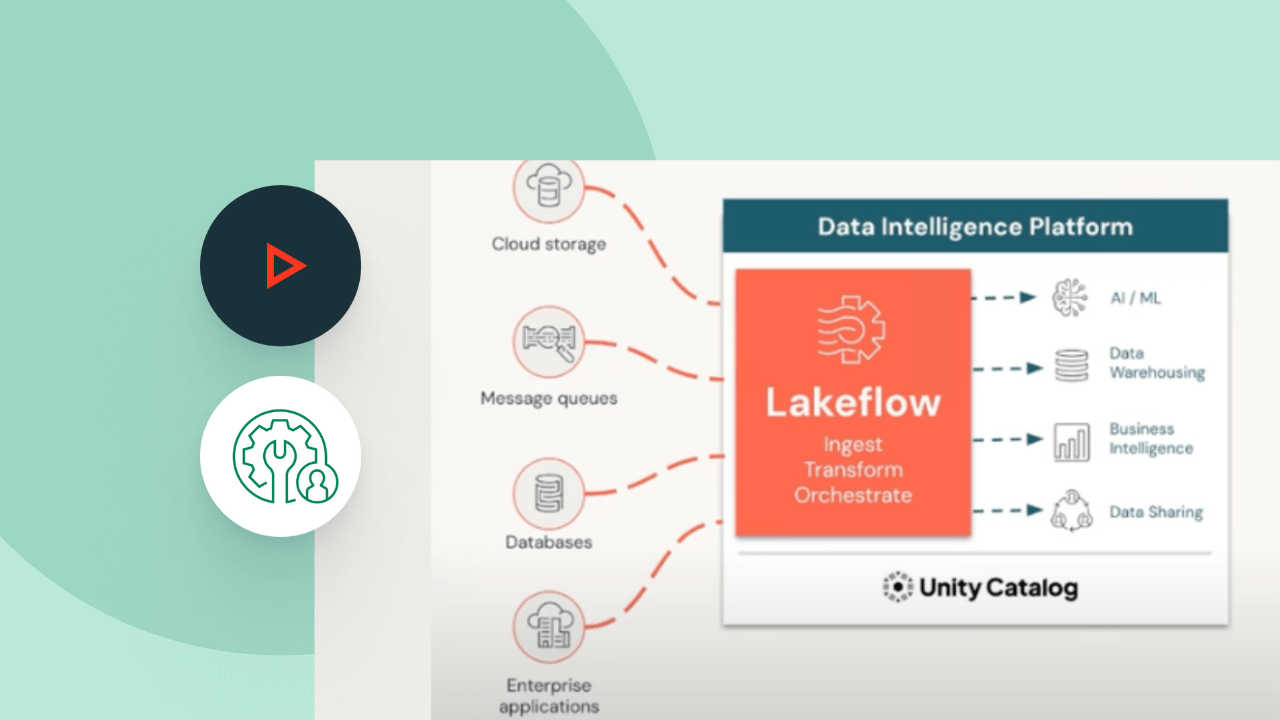
The Data Intelligence Platform
Find out how the Databricks Data Intelligence Platform enables your data and AI workloads.
Take the next step




Spark Declarative Pipelines FAQ
Ready to become a data + AI company?
Take the first steps in your transformation