Using 3rd Party Libraries in Databricks: Apache Spark Packages and Maven Libraries
by Burak Yavuz
In an earlier post, we described how you can easily integrate your favorite IDE with Databricks to speed up your application development. In this post, we will show you how to import 3rd party libraries, specifically Apache Spark packages, into Databricks by providing Maven coordinates.
Background on Spark Packages
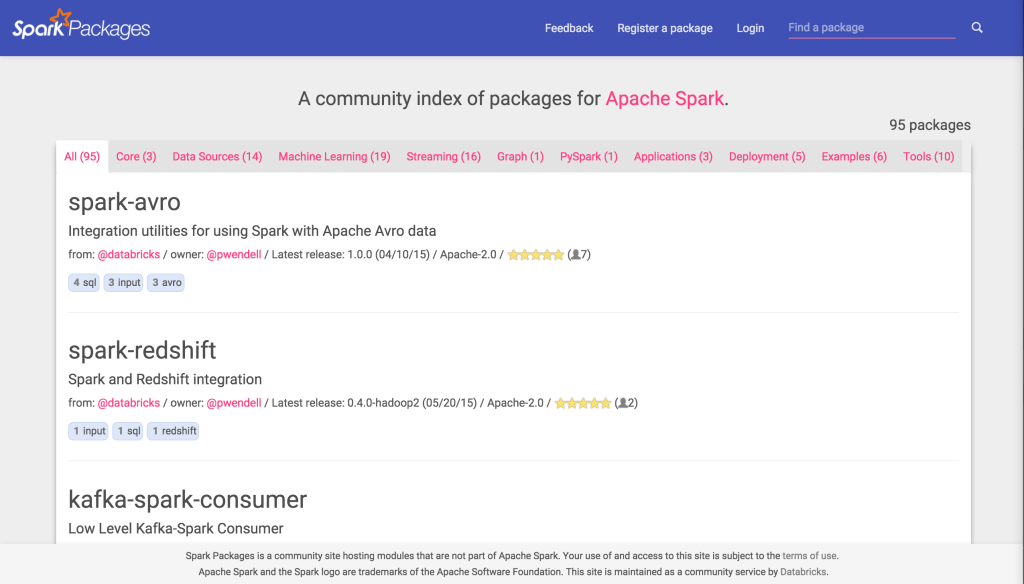
Spark Packages (http://spark-packages.org) is a community package index for libraries built on top of Apache Spark. The purpose of Spark Packages is to bridge the gap between Spark developers and users. Without Spark Packages, you need to to go multiple repositories, such as GitHub, PyPl, and Maven Central, to find the libraries you want. This makes the search for a package that fits your needs a pain - the goal of Spark Packages is to simplify this process for you by becoming the one-stop-shop for your search.
At the time of this writing, there are 95 packages on Spark Packages, with a number of new packages appearing daily. These packages range from pluggable data sources and data formats for DataFrames (such as spark-csv, spark-avro, spark-redshift, spark-cassandra-connector, hbase) to machine learning algorithms, to deployment scripts that enable Spark deployment in cloud environments.
Support for Spark Packages and Maven libraries in Databricks
Did you know that you could download libraries from any public Maven repository, including all its dependencies, with a few clicks to Databricks? Databricks provides you with a browser that allows you to search both Spark Packages and Maven Central. Here’s how it all works:
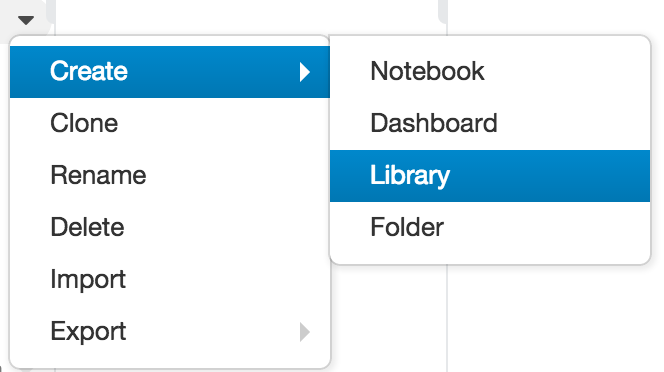
Select where you would like to create the library in the Workspace, and open the Create Library dialog:
From the Source drop-down menu, select Maven Coordinate:
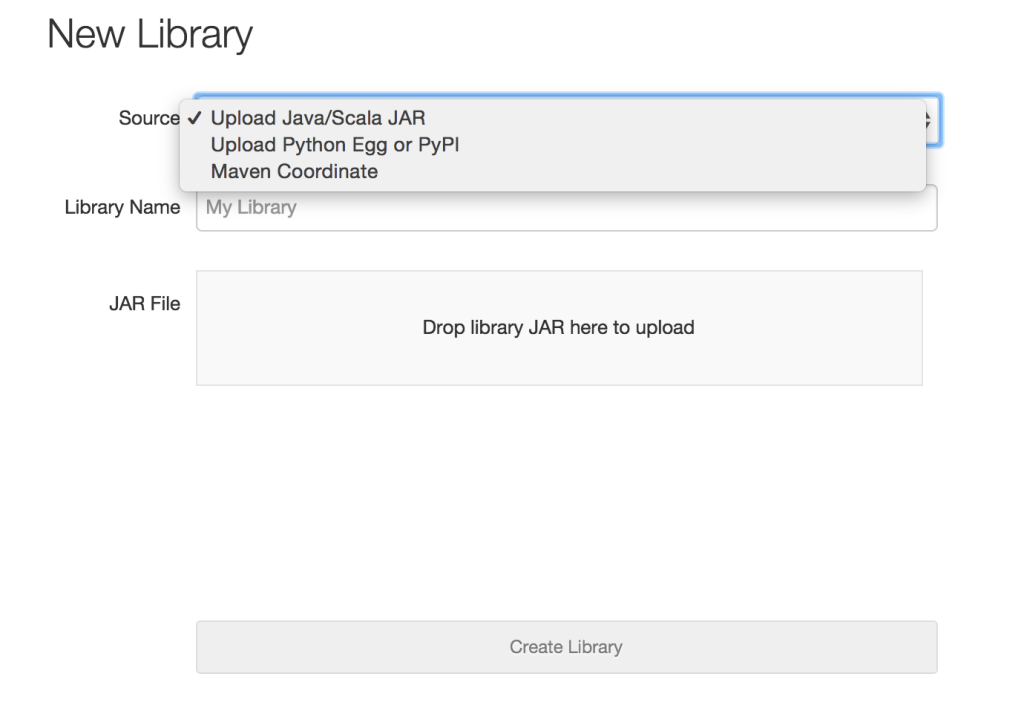
If you already know the Maven coordinate, you can enter it directly to create the library in Databricks instantly. Alternatively, you can also browse Maven libraries and Spark Packages to look through your options by clicking the Search Spark Packages and Maven Central button without entering a coordinate.
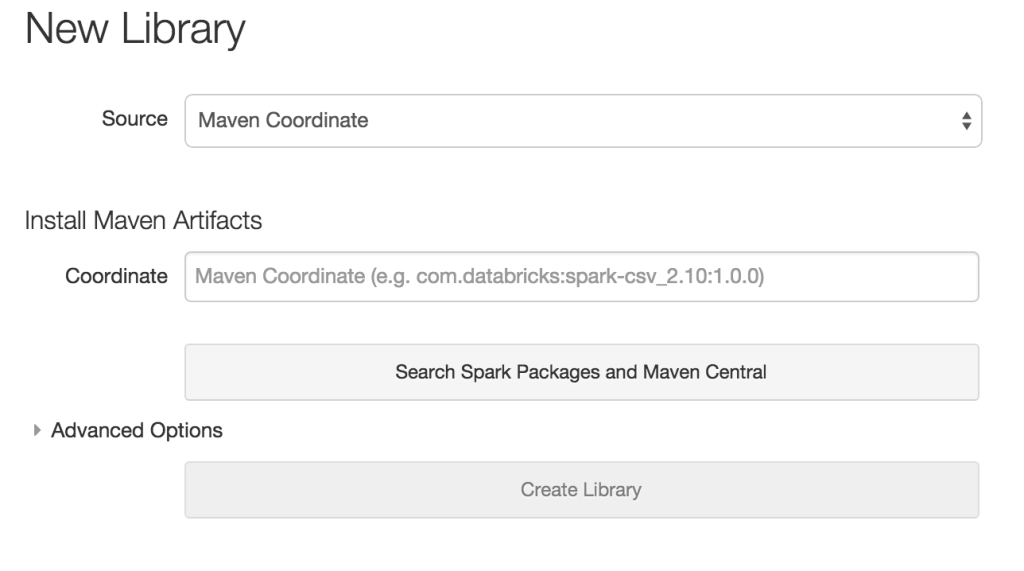
Now, all available Spark Packages are at your fingertips! You can sort packages by name, organization, and rating. You can also filter the results by writing a query in the search bar. The results will automatically refresh.
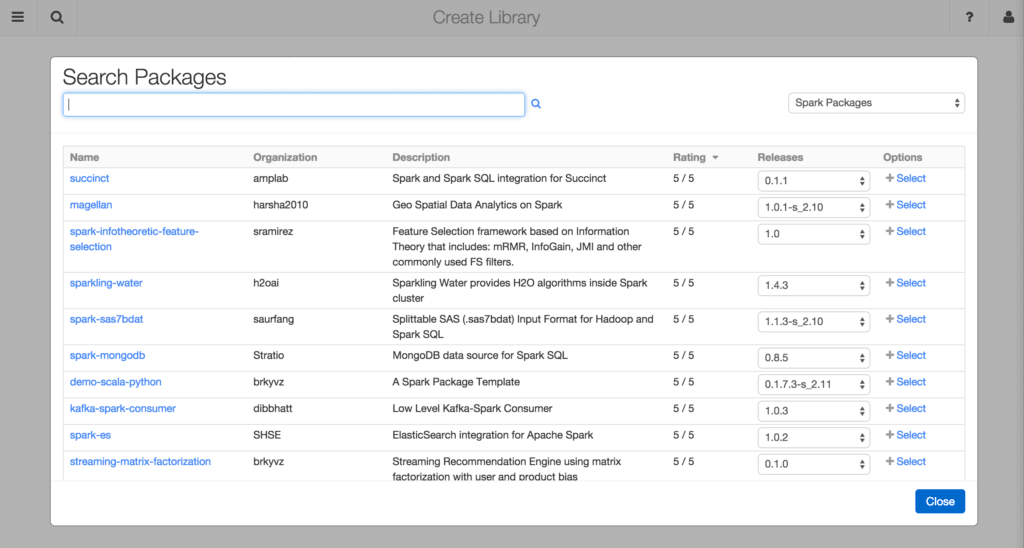
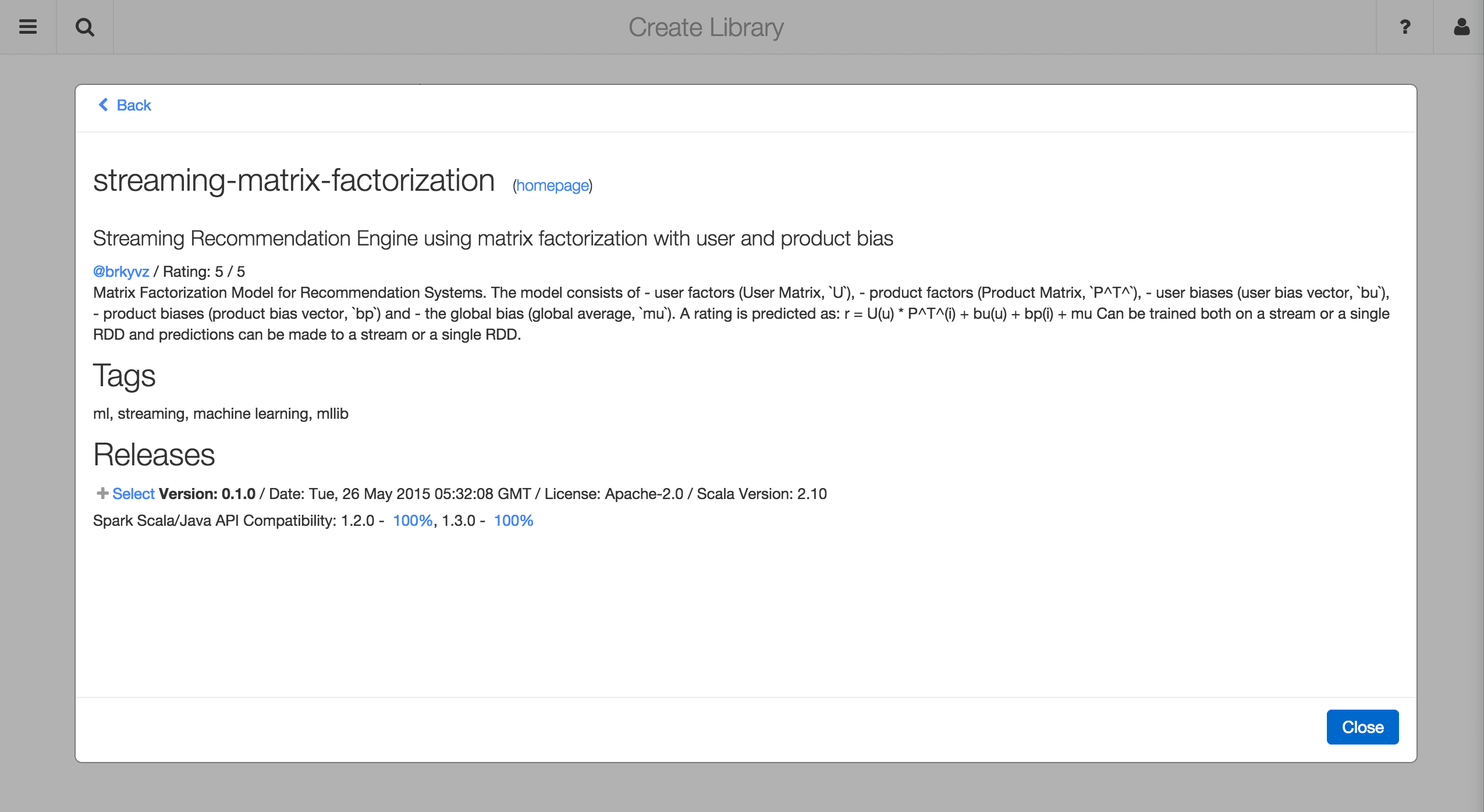
If you want to find out more details about a package, simply click on its name in the browser.
To browse Maven Central, by select the Maven Central option from the drop-down menu on the top right.
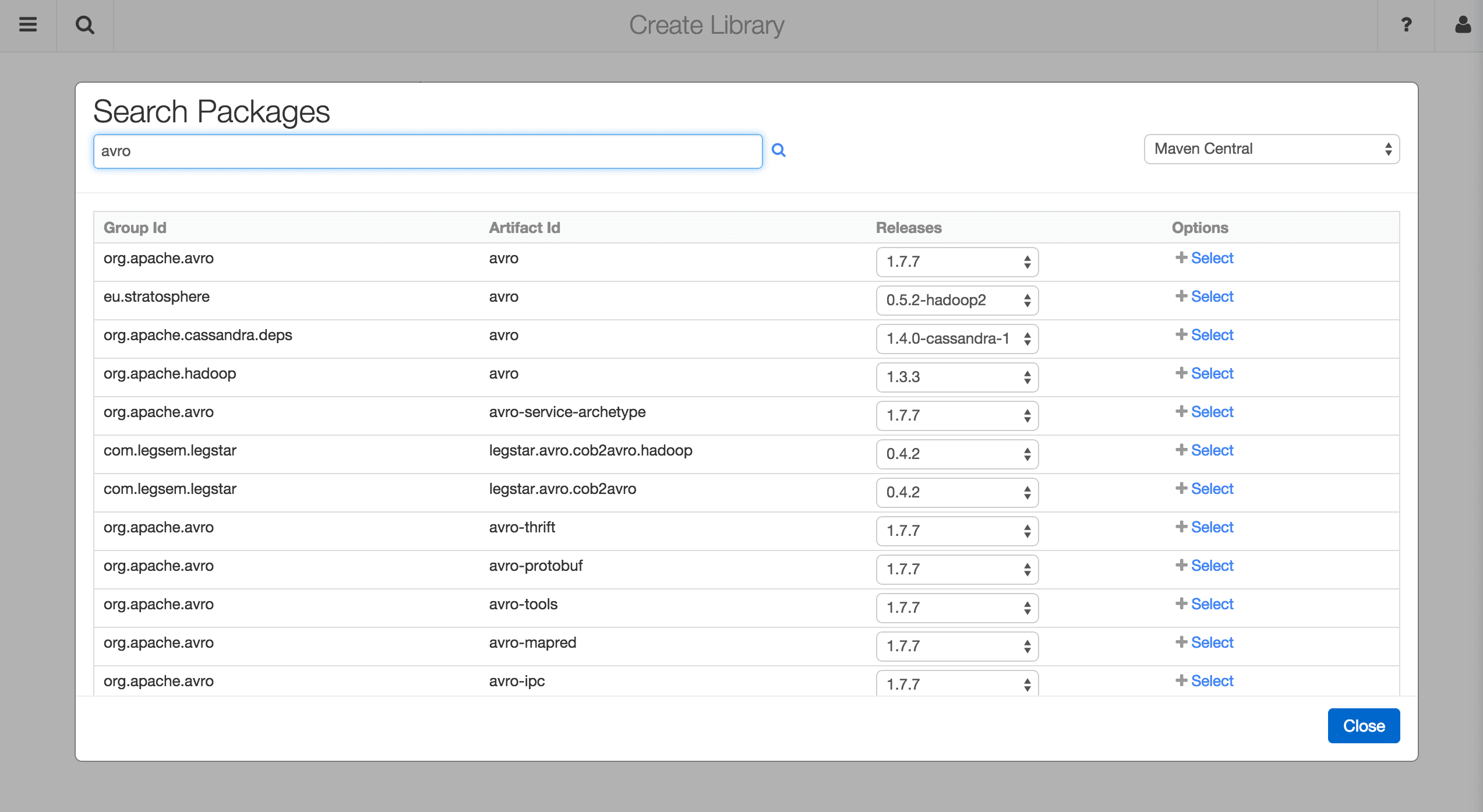
After you identify the package you are interested in, you can choose the release version from the drop-down menu. Once you click the Select button, the Maven Coordinate field from the previous menu will be automatically filled for you.
You can also provide more advanced options, such as the URL for a repository, and any dependencies that you would like to exclude (in case of dependency conflicts).
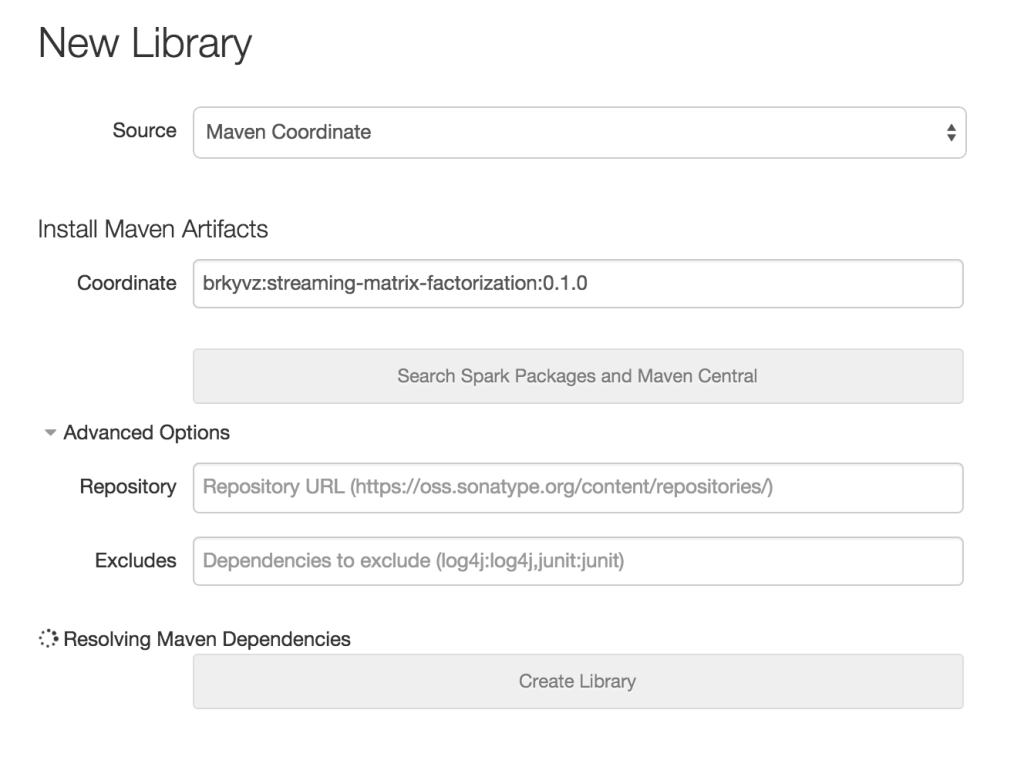
Once you click the Create Library button, and the library and all its dependencies will be fetched for you automatically!

Now you can attach it to any cluster that you wish, and start using the library immediately!
Summary
In this post, we showed how simple it is to integrate Spark Packages to your applications in Databricks using Maven coordinate support. Spark Packages help you to find the code you need to get the job done, and its tight integration with Databricks makes reusing existing code to speed up your Spark application development even simpler.
To try out Spark Packages in Databricks for yourself, sign-up for a 14-day free trial today!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.