Notebook Workflows: The Easiest Way to Implement Apache Spark Pipelines
by Dave Wang, Eric Liang and Maddie Schults
[glossary_parse]Today we are excited to announce Notebook Workflows in Databricks. Notebook Workflows is a set of APIs that allow users to chain notebooks together using the standard control structures of the source programming language — Python, Scala, or R — to build production pipelines. This functionality makes Databricks the first and only product to support building Apache Spark workflows directly from notebooks, offering data science and engineering teams a new paradigm to build production data pipelines.
Traditionally, teams need to integrate many complicated tools (notebooks, Spark infrastructure, external workflow manager just to name a few) to analyze data, prototype applications, and then deploy them into production. With Databricks, everything can be done in a single environment, making the entire process much easier, faster, and more reliable.
Simplifying Pipelines with Notebooks
Notebooks are very helpful in building a pipeline even with compiled artifacts. Being able to visualize data and interactively experiment with transformations makes it much easier to write code in small, testable chunks. More importantly, the development of most data pipelines begins with exploration, which is the perfect use case for notebooks.
On the flip side, teams also run into problems as they use notebooks to take on more complex data processing tasks:
- Logic within notebooks becomes harder to organize. Exploratory notebooks start off as simple sequences of Spark commands that run in order. However, it is common to make decisions based on the result of prior steps in a production pipeline - which is often at odds with how notebooks are written during the initial exploration.
- Notebooks are not modular enough. Teams need the ability to retry only a subset of a data pipeline so that a failure does not require re-running the entire pipeline.
These are the common reasons that teams often re-implement notebook code for production. The re-implementation process is time-consuming, tedious, and negates the interactive properties of notebooks.
Databricks Notebook Workflows
We took a fresh look at the problem and decided that a new approach is needed. Our goal is to provide a unified platform that eliminates the friction between data exploration and production applications. We started out by providing a fully managed notebook environment for ad hoc experimentation, as well as a Job Scheduler that allows users to deploy notebooks directly to production via a simple UI. By adding Notebook Workflows on top of these existing functionalities, we are providing users the fastest, easiest way to create complex workflows out of their data processing code.
Databricks Notebook Workflows are a set of APIs to chain together Notebooks and run them in the Job Scheduler. Users create their workflows directly inside notebooks, using the control structures of the source programming language (Python, Scala, or R). For example, you can use if statements to check the status of a workflow step, use loops to repeat work, or even take decisions based on the value returned by a step. This approach is much simpler than external workflow tools such as Apache Airflow, Oozie, Pinball, or Luigi because users can transition from exploration to production in the same environment instead of operating another system.
Notebook Workflows are supervised by the Databricks Jobs Scheduler. This means that every workflow gets the production functionality provided by Jobs, such as fault recovery and timeout mechanisms. It also takes advantage of Databricks’ version control and security features — helping teams manage the evolution of complex workflows through GitHub, and securing access to production infrastructure through role-based access control.
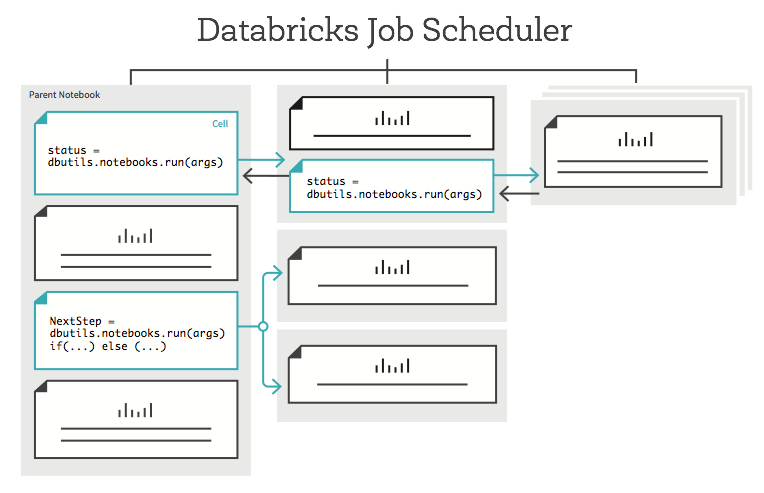
How to Use Notebook Workflows
Running a notebook as a workflow with parameters
The most basic action of a Notebook Workflow is to simply run a notebook with the dbutils.notebook.run() command. The command runs the notebook on the cluster the caller notebook is attached to, provided that you have the right permissions (see our ACLs documentation to learn more about notebook and cluster level permissions).
The dbutils.notebook.run() command also allows you to pass in arguments to the notebook, like this:

Getting return values
To create more flexible workflows, the dbutils.notebook.run() command can pass back a return value, like this:
The dbutils.notebook.exit() command in the callee notebook needs to be invoked with a string as the argument, like this:
It is also possible to return structured data by referencing data stored in a temporary table or write the results to DBFS (Databricks’ caching layer over Amazon S3) and then return the path of the stored data.
Control flow and exception handling
You can control the execution flow of your workflow and handle exceptions using the standard if/then statements and exception processing statements in either Scala or Python. For example:
You can also use workflows to perform retries and pass more complex data between notebooks. See the documentation for more details.
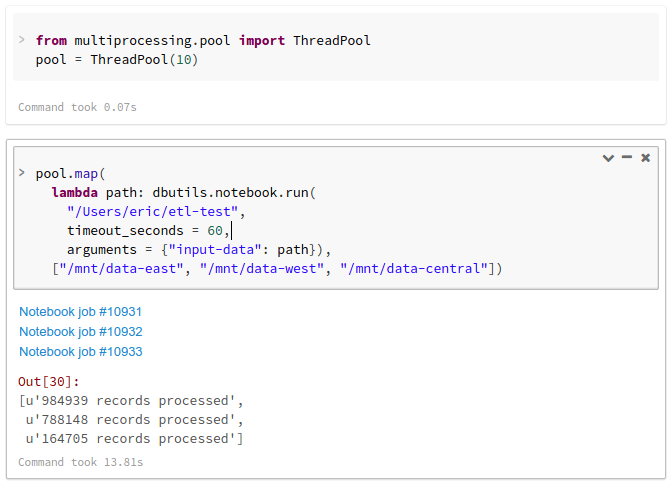
Running concurrent notebook workflows
Using built-in libraries in Python and Scala, you can launch multiple workflows in parallel. Here we show a simple example of running three ETL tasks in parallel from a Python notebook. Since workflows are integrated with the native language, it is possible to express arbitrary concurrency and retry behaviors in the user's preferred language, in contrast to other workflow engines.
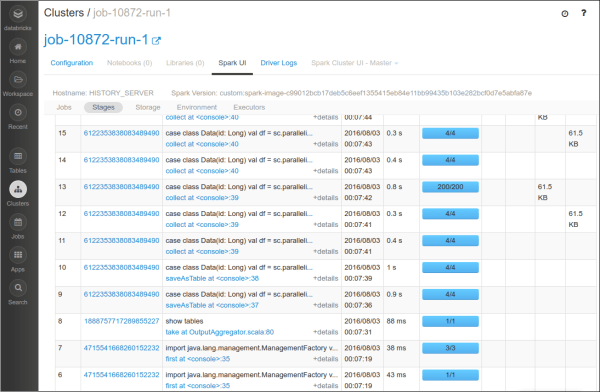
Debugging
The run command returns a link to a job, which you can use to deep-dive on performance and debug the workflow. Simply open the caller notebook and click on the callee notebook link as shown below and you can start drilling down with the built-in Spark History UI.
What’s Next
Have questions? Got tips you want to share with others? Visit the Databricks forum and participate in our user community.
We are just getting started with helping Databricks users build workflows. Stay tuned for more functionality in the near future. Try to build workflows by signing up for a trial of Databricks today. You can also find more detailed documentation here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.