
Today we are excited to announce persistent clusters for analytics in Databricks. With persistent clusters, users no longer need to go through the laborious process of providing all the cluster and Apache Spark configuration every time they need a cluster. Admins can provide all the configurations to setup multiple clusters once and then allow users of their organization to easily start and terminate those clusters based on usage needs.
Persistent clusters will empower the admins to set up clusters and enforce certain limits while giving the regular users control over creating and terminating the clusters when they want them. When setup with the right permissions, users just need to click on a 'Start' button when they need the cluster without having to worry about the complexities of creating and terminating clusters.
This will tremendously simplify how different teams work with clusters on Databricks and will also allow them to better optimize and control infrastructure costs.
Cluster Management Complexities
Clusters are pivotal for working with data. In Databricks, different users can set up clusters with different configurations based on their use cases, workload needs, resource requirements and the volume of the data they are processing. Databricks empowers the users to set up a cluster in a myriad of ways to meet their needs. Some examples:
- Teams can provide specific cloud instance types and availability zones if they have purchased reserved instances from the cloud provider.
- Teams can provide a hybrid composition of on-demand and spot instances to maintain a balance between costs and reliability.
- Data engineers and scientists can fine-tune their jobs with custom Spark parameters.
- Admins can provide access control permissions and IAM roles to restrict access to the cluster and data.
On the flip side, teams also run into problems as they use clusters on a more day-to-day basis:
- Auto-termination of clusters: Since organizations get billed based on their cluster usage, teams want the ability to automatically terminate the clusters that are not being in use to avoid incurring unnecessary compute costs.
- Recreation of clusters is cumbersome: As mentioned above, users want to set up clusters with different custom configurations to meet their needs. In such cases, it is really painful to provide all these parameters manually every time a cluster is required again.
- No enforcement of cluster parameters: Admins don't have control over how users create and setup their clusters. Very often, admins want to enforce certain configurations like:
- Tags to charge back costs.
- IAM roles to control access to data.
- Spot instance to save costs.
- Reattaching libraries, notebooks, jobs every time: It is common to set up a cluster with multiple libraries installed and many notebooks and jobs attached to the cluster. Terminating such a cluster means all that information is lost and will need to be reattached again. This becomes a big nightmare as more users start using the platform.
Your compact guide to modern analytics

Simplifying Cluster Management with Persistent Clusters
"Persistent clusters" is a series of features to help administrators and teams resolve the problem around easily terminating and recreating clusters to address the aforementioned issues. Let's walk through these features with some examples and use cases.
Imagine two teams in an organization using Databricks - a data engineering team running production batch pipelines and a data science team doing ad-hoc analytics on historical data. The two teams want two different types of clusters - one for development and one for production.
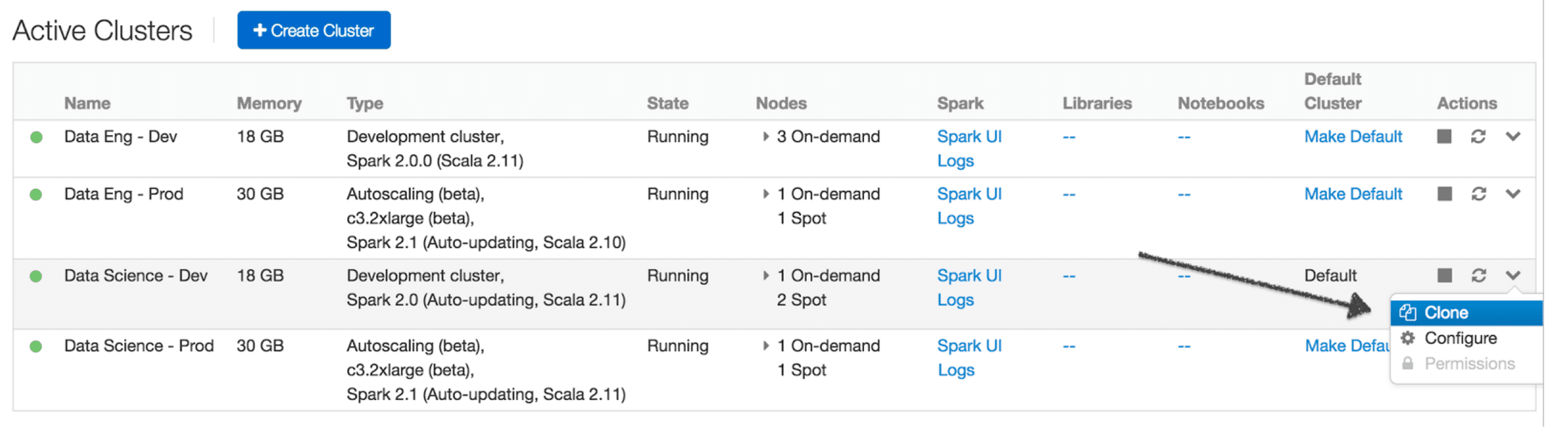
Creating and Cloning Clusters
The Databricks admin can create four different persistent clusters for these purposes. Based on the team's usage needs, the admin can set up the cluster with different configurations for instance types, auto-scaling limits, spot and on-demand composition, logging and SSH parameters, etc.
The admin can also clone an existing cluster if the new cluster needs to have a similar configuration as one of the existing ones. The cluster creation form will be pre-filled with configurations of the cluster being cloned.
Enabling Auto-Termination to Save Costs
One of Databricks' most requested features has been auto-termination. Now during cluster creation, the cluster creator can enable auto-termination to save costs. For every cluster, the admin can specify the amount of idle time after which the cluster needs to be terminated. Databricks uses a low-level Spark-native task tracking algorithm to determine the cluster's idle period and automatically terminates them after the specified idle time to save costs both with Databricks and the cloud provider.
Setting up the right cluster permissions
Once the clusters are created, the admin can now give the right permissions for the users of their platform. The below table captures the different permissions and the actions allowed with them:
| Permission Levels | |||
|---|---|---|---|
| Actions | Can Attach To | Can Restart | Can Manage |
| View Spark UI & logs | [db_icon name="checkmark"]Yes | [db_icon name="checkmark"]Yes | [db_icon name="checkmark"]Yes |
| Attach notebooks and libraries | [db_icon name="checkmark"]Yes | [db_icon name="checkmark"]Yes | [db_icon name="checkmark"]Yes |
| Start cluster | [db_icon name="checkmark"]Yes | [db_icon name="checkmark"]Yes | |
| Terminate cluster | [db_icon name="checkmark"]Yes | [db_icon name="checkmark"]Yes | |
| Restart cluster | [db_icon name="checkmark"]Yes | [db_icon name="checkmark"]Yes | |
| Resize cluster | [db_icon name="checkmark"]Yes | ||
| Give other users access to the cluster | [db_icon name="checkmark"]Yes | ||
Databricks recommends the following guidelines for admins to setup the permissions for clusters:
- Can Attach To: Use this permission if the users should not have a direct influence on the cost. They can attach notebooks and libraries and run commands but they cannot start or terminate the clusters.
- Can Restart: Use this permission if you would like your users to freely start and terminate the cluster as well. They have an impact on the cost, but they cannot modify the max limits and other cluster configurations that are set.
- Can Manage: Use this permission if you want to give a user full control of the cluster. They can adjust the max limits and also give other users permissions to access the cluster.
Enforcing Cluster Configuration
Admins can also enforce certain configurations for clusters so that users cannot change them. Databricks recommends the following workflow for organizations that need to enforce configurations:
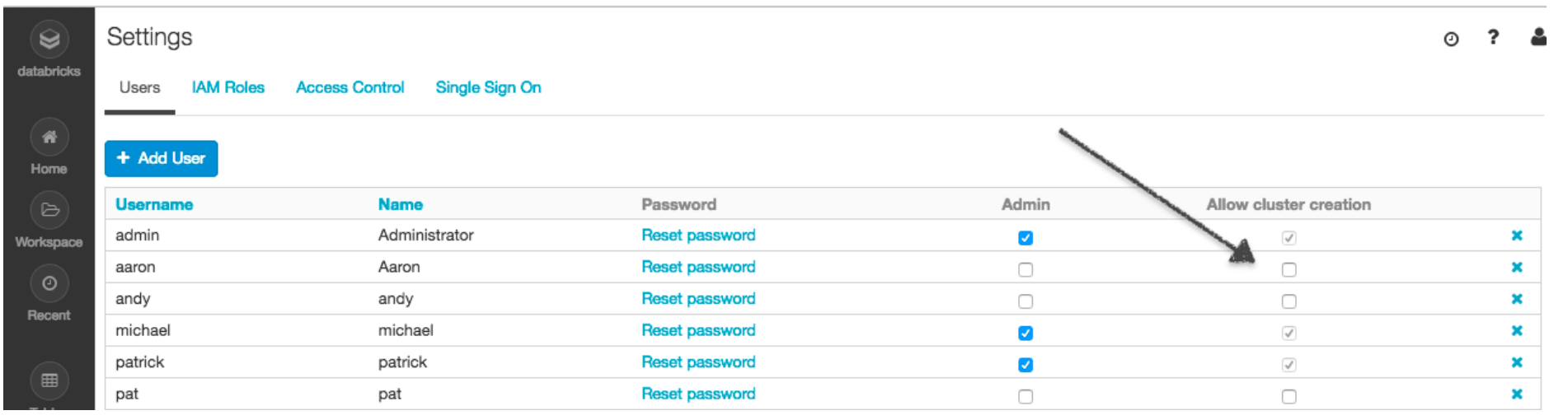
- Disable 'Allow cluster creation' option in the admin console for all the non-admin users.
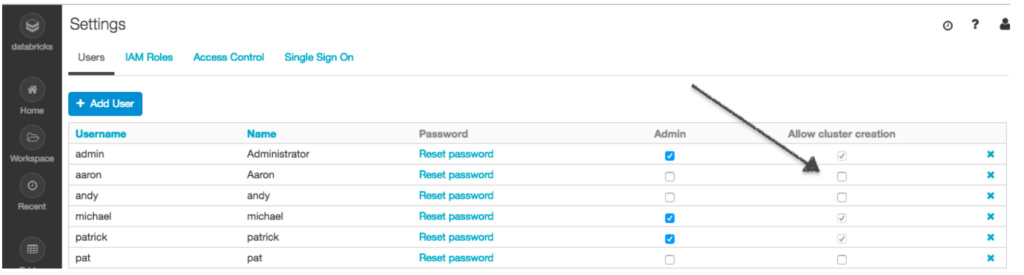
-
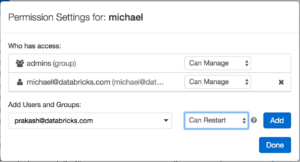
After creating all of the cluster configurations that you would like your users to use, you can give all the users who need to have access to that given cluster 'Can Restart' permission. This will allow a given user, with that permission, to freely start and terminate the cluster without having to set up all the configurations manually.
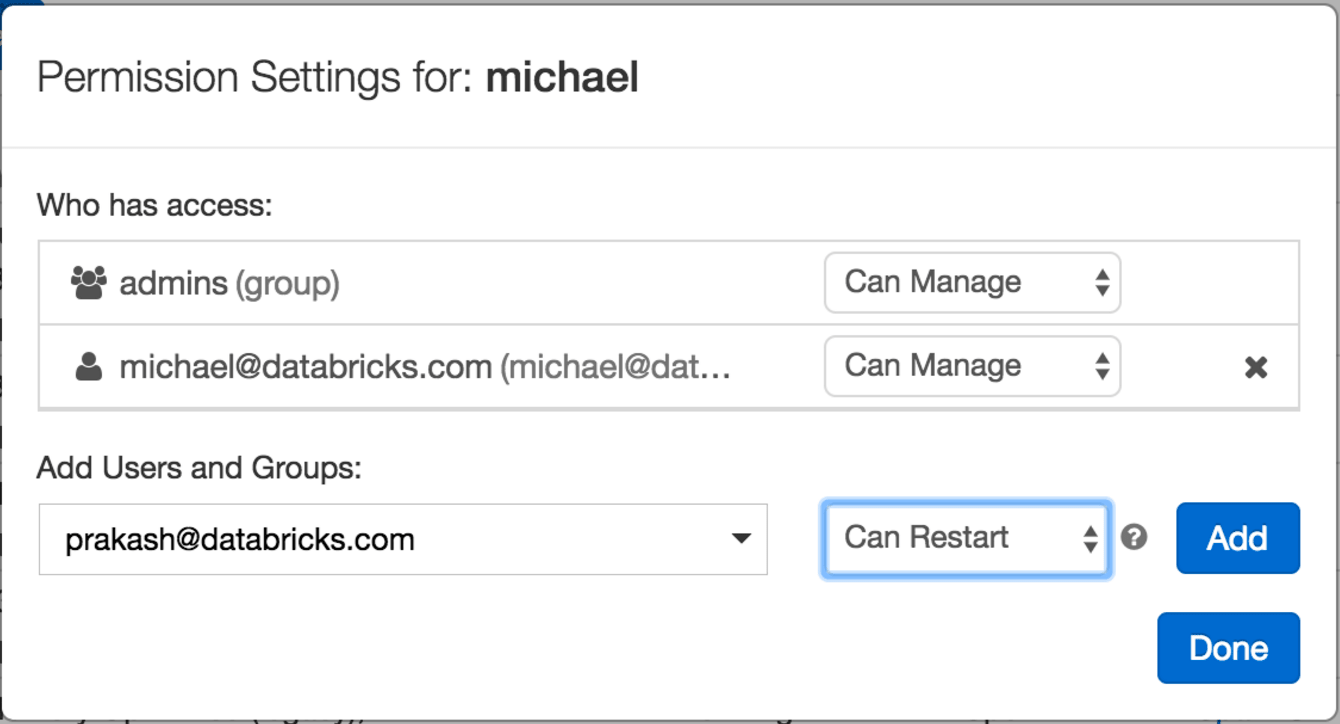
Starting Clusters
As mentioned above, once a user has 'Can Restart' permission, they simply need to click the 'Start' button in the cluster page to start that cluster again. The cluster will be recreated with all the existing configuration and all libraries and notebooks will reattach automatically. This functionality is also available through the REST API for users provisioning the clusters through REST APIs.
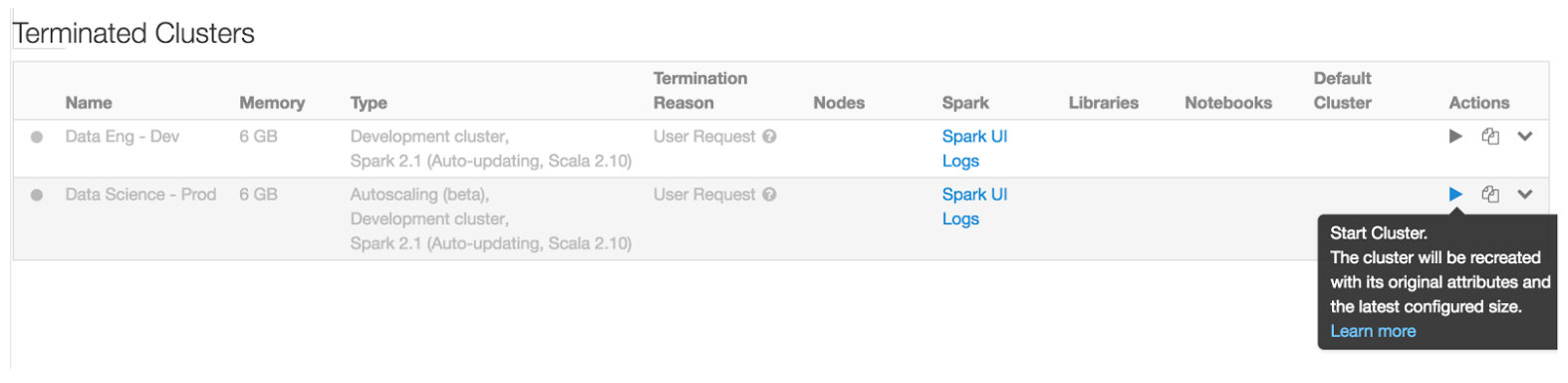
Terminating Clusters
Previously in Databricks, users or administrators would have to manually terminate clusters when they were done with them. Now, if auto-termination was specified at cluster creation, then users never need to remember to turn off a cluster when they are done - Databricks will handle that for them. If manual termination is needed, then users who have 'Can Restart' permission to a cluster can terminate the cluster any time.
What's next
Want to learn more about other cluster management features? Check out the user guide for all the existing functionalities and best practices.
Try out the new cluster management functionalities by signing up for a free trial of Databricks.