Running Streaming Jobs Once a Day For 10x Cost Savings
Part 6 of Scalable Data @ Databricks
by Burak Yavuz and Tyson Condie
This is the sixth post in a multi-part series about how you can perform complex streaming analytics using Apache Spark.
Traditionally, when people think about streaming, terms such as “real-time,” “24/7,” or “always on” come to mind. You may have cases where data only arrives at fixed intervals. That is, data appears every hour or once a day. For these use cases, it is still beneficial to perform incremental processing on this data. However, it would be wasteful to keep a cluster up and running 24/7 just to perform a short amount of processing once a day.
Fortunately, by using the new Run Once trigger feature added to Structured Streaming in Spark 2.2, you will get all the benefits of the Catalyst Optimizer incrementalizing your workload, and the cost savings of not having an idle cluster lying around. In this post, we will examine how to employ triggers to accomplish both.
Triggers in Structured Streaming
In Structured Streaming, triggers are used to specify how often a streaming query should produce results. Once a trigger fires, Spark checks to see if there is new data available. If there is new data, then the query is executed incrementally on whatever has arrived since the last trigger. If there is no new data, then the stream sleeps until the next trigger fires.
The default behavior of Structured Streaming is to run with the lowest latency possible, so triggers fire as soon as the previous trigger finishes. For use cases with lower latency requirements, Structured Streaming supports a ProcessingTime trigger which will fire every user-provided interval, for example every minute.
While this is great, it still requires the cluster to remain running 24/7. In contrast, a RunOnce trigger will fire only once and then will stop the query. As we'll see below, this lets you effectively utilize an external scheduling mechanism such as Databricks Jobs.
Triggers are specified when you start your streams.
[code_tabs]
[/code_tabs]
Why Streaming and RunOnce is Better than Batch
You may ask, how is this different than simply running a batch job? Let’s go over the benefits of running Structured Streaming over a batch job.
Bookkeeping
When you’re running a batch job that performs incremental updates, you generally have to deal with figuring out what data is new, what you should process, and what you should not. Structured Streaming already does all this for you. In writing general streaming applications, you should only care about the business logic, and not the low-level bookkeeping.
Table Level Atomicity
The most important feature of a big data processing engine is how it can tolerate faults and failures. The ETL jobs may (in practice, often will) fail. If your job fails, then you need to ensure that the output of your job should be cleaned up, otherwise you will end up with duplicate or garbage data after the next successful run of your job.
While using Structured Streaming to write out a file-based table, Structured Streaming commits all files created by the job to a log after each successful trigger. When Spark reads back the table, it uses this log to figure out which files are valid. This ensures that garbage introduced by failures are not consumed by downstream applications.
Stateful Operations Across Runs
If your data pipeline has the possibility of generating duplicate records, but you would like exactly once semantics, how do you achieve that with a batch workload? With Structured Streaming, it’s as easy as setting a watermark and using dropDuplicates(). By configuring the watermark long enough to encompass several runs of your streaming job, you will make sure that you don’t get duplicate data across runs.
Cost Savings
Running a 24/7 streaming job is a costly ordeal. You may have use cases where latency of hours is acceptable, or data comes in hourly or daily. To get all the benefits of Structured Streaming described above, you may think you need to keep a cluster up and running all the time. But now, with the “execute once” trigger, you don’t need to!
At Databricks, we had a two stage data pipeline, consisting of one incremental job that would make the latest data available, and one job at the end of the day that processed the whole day’s worth of data, performed de-duplication, and overwrote the output of the incremental job. The second job would use considerably larger resources than the first job (4x), and would run much longer as well (3x). We were able to get rid of the second job in many of our pipelines that amounted to a 10x total cost savings. We were also able to clean up a lot of code in our codebase with the new execute once trigger. Those are cost savings that makes both financial and engineering managers happy!
Scheduling Runs with Databricks
Databricks’ Jobs scheduler allows users to schedule production jobs with a few simple clicks. Jobs scheduler is ideal for scheduling Structured Streaming jobs that run with the execute once trigger.
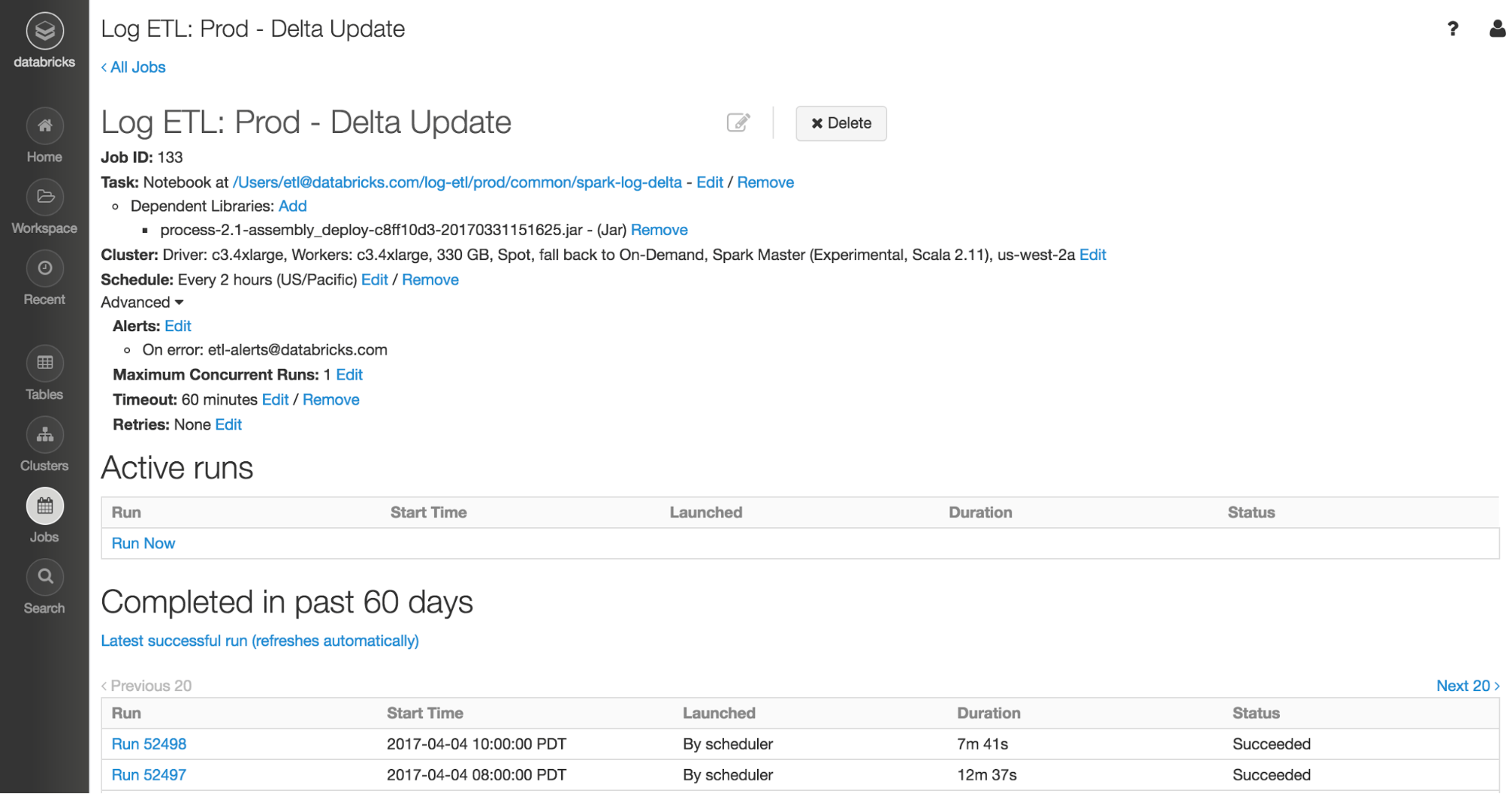
At Databricks, we use the Jobs scheduler to run all of our production jobs. As engineers, we ensure that the business logic within our ETL job is well tested. We upload our code to Databricks as a library, and we set up notebooks to set the configurations for the ETL job such as the input file directory. The rest is up to Databricks to manage clusters, schedule and execute the jobs, and Structured Streaming to figure out which files are new, and process incoming data. The end result is an end-to-end — from data origin to data warehouse, not only within Spark — exactly once data pipeline. Check out our documentation on how to best run Structured Streaming with Jobs.
Summary
In this blog post we introduced the new “execute once” trigger for Structured Streaming. While the execute once trigger resembles running a batch job, we discussed all the benefits it has over the batch job approach, specifically:
- Managing all the bookkeeping of what data to process
- Providing table level atomicity for ETL jobs to a file store
- Ensuring stateful operations across runs of the job, which allow for easy de-duplication
In addition to all these benefits over batch processing, you also get the cost savings of not having an idle 24/7 cluster up and running for an irregular streaming job. The best of both worlds for batch and streaming processing are now under your fingertips.
Try Structured Streaming today in Databricks by signing up for a 14-day free trial .
Other parts of this blog series explain other benefits as well:
- Real-time Streaming ETL with Structured Streaming in Apache Spark 2.1
- Working with Complex Data Formats with Structured Streaming in Apache Spark 2.1
- Processing Data in Apache Kafka with Structured Streaming in Apache Spark 2.2
- Event-time Aggregation and Watermarking in Apache Spark’s Structured Streaming
- Taking Apache Spark’s Structured Structured Streaming to Production
- Running Streaming Jobs Once a Day For 10x Cost Savings
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.