Working with Nested Data Using Higher Order Functions in SQL on Databricks
by Herman van Hövell and Bill Chambers
View this notebook on Databricks
Nested data types offer Databricks customers and Apache Spark users powerful ways to manipulate structured data. In particular, they allow you to put complex objects like arrays, maps and structures inside of columns. This can help you model your data in a more natural way. While this feature is certainly useful, it can be a bit cumbersome to manipulate data inside of the complex objects because SQL (and Spark) do not have primitives for working with such data. In addition, it is time-consuming, non-performant, and non-trivial.
For these reasons, we are excited to offer higher order functions in SQL in the Databricks Runtime 3.0 Release, allowing users to efficiently create functions, in SQL, to manipulate array based data. Higher-order functions are a simple extension to SQL to manipulate nested data such as arrays. For example, the TRANSFORM expression below shows how we can add a number to every element in an array:
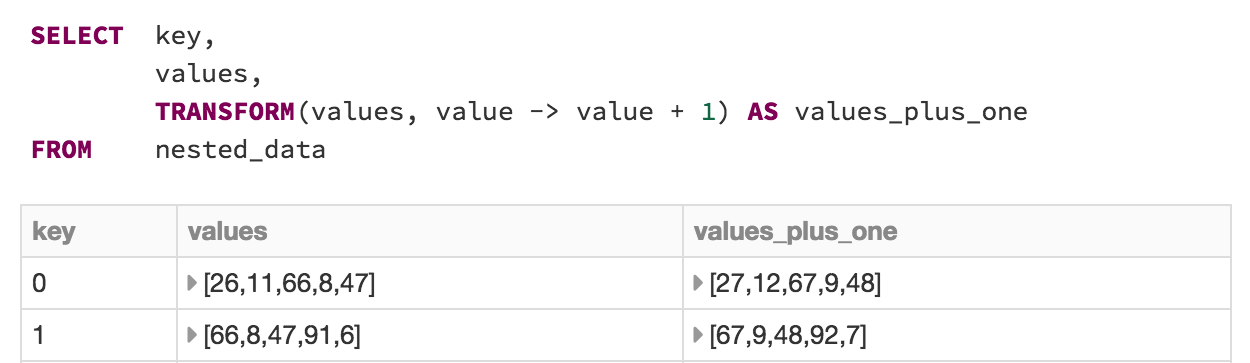
In this post, we'll cover previous approaches to nested data manipulation in SQL, followed by the higher-order function syntax we have introduced in Databricks.
Check out the Why the Data Lakehouse is Your Next Data Warehouse ebook to discover the inner workings of the Databricks Lakehouse Platform.
Past Approaches
Before we introduce the new syntax for array manipulation, let's first discuss the current approaches to manipulating this sort of data in SQL:
- built-in functions (limited functionality)
- unpack the array into individual rows, apply your function, then repack them into an array (many steps, hence inefficient)
- UDFs (not generic or efficient)
We'll explore each of these independently so that you can understand why array manipulation is difficult. Let’s start off with a table with the schema below (see the included notebook for code that’s easy to run).
Built-In Functions
Spark SQL does have some built-in functions for manipulating arrays. For example, you can create an array, get its size, get specific elements, check if the array contains an object, and sort the array. Spark SQL also supports generators (explode, pos_explode and inline) that allow you to combine the input row with the array elements, and the collect_list aggregate. This functionality may meet your needs for certain tasks, but it is complex to do anything non-trivial, such as computing a custom expression of each array element.
Unpack and Repack
The common approach for non-trivial manipulations is the "unpack and repack" method. This is a "Spark SQL native" way of solving the problem because you don't have to write any custom code; you simply write SQL code. The unpack and repack approach works by applying the following steps:
- Use
LATERAL VIEW explodeto flatten the array, and combine the input row with each element in the array; - Apply a given transformation, in this example
value + 1, to each element in the exploded array; and - Use
collect_listorcollect_setto create a new array.
We can see an example of this in the SQL code below:
While this approach certainly works, it has a few problems. First, you must be absolutely sure that the key you are used for grouping is unique, otherwise the end result will be incorrect. Second, there is no guaranteed ordering of arrays in Spark SQL. Specifying an operation that requires a specific ordering nearly guarantees incorrect results. Finally, the generated Spark SQL plan will likely be very expensive.
User-Defined Functions (UDFs)
Lastly, we can write custom UDFs to manipulate array data. Our UDFs must define how we traverse an array and how we process the individual elements. Let's see some basic examples in Python and Scala.
[code_tabs]
[/code_tabs]
Once registered, we can use those functions to manipulate our data in Spark SQL.
This approach has some advantages over the previous version: for example, it maintains element order, unlike the pack and repack method. However, it has two key disadvantages. First, you have to write functions in other languages than SQL and register them before running. Second, data serialization into Scala and Python can be very expensive, slowing down UDFs over Spark's SQL optimized built-in processing.
Our Approach: Higher Order Functions
As observed from the examples above, the traditional ways to manipulate nested data in SQL are cumbersome. To that end, we have built a simple solution in Databricks: higher order functions in SQL.
Run the following examples in this notebook.
Our solution introduces two functional programming constructions to SQL: higher order functions and anonymous (lambda) functions. These work together to allow you to define functions that manipulate arrays in SQL. The higher order function, such as TRANSFORM, takes an array and a lambda function from the user to run on it. It then calls this lambda function on each element in the array.
A Simple Example: TRANSFORM
Let's illustrate the previous concepts with the transformation from our previous example. In this case, the higher order function, TRANSFORM, will iterate over the array, apply the associated lambda function to each element, and create a new array. The lambda function, element + 1, specifies how each element is manipulated.
To be abundantly clear, the transformation TRANSFORM(values, value -> value + 1) has two components:
TRANSFORM(values..)is the higher order function. This takes an array and an anonymous function as its input. Internally transform will take care of setting up a new array, applying the anonymous function to each element, and assigning the result to the output array.- The
value -> value + 1is an anonymous function. The function is divided into two components separated by a->symbol:
a. The argument list. In this case, we only have one argument: value. We also support multiple arguments by creating a comma separated list of arguments enclosed by parenthesis, for example:(x, y) -> x + y.
b. The body. This is an expression that can use the arguments and outer variables to calculate the new value. In this case, we add 1 to the value argument.
Capturing Variables
We can also use other variables than the arguments in a lambda function; this is called capture. We can use variables defined on the top level, or variables defined in intermediate lambda functions. For example, the following transform adds the key (top level) variable to each element in the values array:
Nested Calls
Sometimes data is deeply nested. If you want to transform such data, you can can use nested lambda functions. The following example transforms an array of integer arrays, and adds the key (top level) column and the size of the intermediate array to each element in the nested array.
Supported Functions
We have added the following higher order functions to the 3.0 version of the Databricks Runtime.
transform(array, function): array
This produces an array by applying a function to each element of an input array.
Note that the functional programming equivalent operation is map. This has been named transform in order to prevent confusion with the map expression (that creates a map from a key value expression).
The following query transforms the values array by adding the key value to each element:
exists(array, function): Boolean
Return true if predicate function holds for any element in input array.
The following examples checks if the values array contains an elements for which the modulo 10 is equal to 1:
filter(array, function): array
Produce an output array from an input array by only only adding elements for which predicate function holds.
The following examples filters the values array only elements with a value > 50 are allowed:
aggregate(array, B, function, function): R
Reduce the elements of array into a single value R by merging the elements into a buffer B using function and by applying a finish function on the final buffer. The initial value B is determined by a zero expression. The finalize function is optional, if you do not specify the function the finalize function the identity function (id -> id) is used.
This is the only higher order function that takes two lambda functions.
The following example sums (aggregates) the values array into a single (sum) value. Both a version with a finalize function (summed_values) and one without a finalize function summed_values_simple is shown:
You can also compute more complex aggregates. The code below shows the computation of the geometric mean of the array elements.
Conclusion
Higher order functions will available in Databricks Runtime 3.0. If you have any nested data, be sure to try them!
This work adds initial support for using higher order functions with nested array data. Additional functions and support for map data are on their way. Be sure to check out the Databricks blog and documentation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.