Databricks Serverless: Next Generation Resource Management for Apache Spark
by Greg Owen, Eric Liang, Prakash Chockalingam and Srinath Shankar
As the amount of data in an organization grows, more and more engineers, analysts and data scientists need to analyze this data using tools like Apache Spark. Today, IT teams constantly struggle to find a way to allocate big data infrastructure, budget among different users, and optimize performance. End-users like data scientists and analysts also spend enormous amounts of time tuning their big data infrastructure for optimum performance, which is neither their core expertise nor their primary goal of deriving insights from data.
To remove these operational complexities for users, the next generation of cloud computing is headed toward serverless computing. Products like BigQuery offer serverless interfaces that require zero infrastructure management for users. But all these existing products only address simple, stateless SQL use cases.
Today, we are excited to announce Databricks Serverless, a new initiative to offer serverless computing for complex data science and Apache Spark workloads. Databricks Serverless is the first product to offer a serverless API for Apache Spark, greatly simplifying and unifying data science and big data workloads for both end-users and DevOps.
Specifically, in Databricks Serverless, we set out to achieve the following goals:
- Remove all operational complexities for both big data and interactive data science.
- Reduce operational cost by an order of magnitude by letting organizations maximize their resource utilization in a shared environment spanning all their workloads.
- Minimize query latencies for interactive analysis.
- Achieve all of the above without compromising on reliability.
At Data + AI Summit today, we have launched our first phase of Databricks Serverless, called Serverless Pools, which allow customers to run a pool for serverless workloads in their own AWS account. Hundreds of users can share a pool, while DevOps can control the resource cost of their whole workload in a single place. In future phases, we will also provide services to run serverless workloads outside the customer's AWS environment.
What Are Serverless Pools?
Databricks Serverless pools are automatically managed pools of cloud resources that are auto-configured and auto-scaled for interactive Spark workloads. Administrators only need to provide the minimum and maximum number of instances they want in their pool, for the purpose of budget control. End-users then program their workloads using Spark APIs in SQL or Python, and Databricks will automatically and efficiently run these workloads.
The three key benefits of serverless pools are:
- Auto-configuration: The Spark version deployed in serverless pools is automatically optimized for interactive SQL and Python workloads.
- Spark-aware elasticity: Databricks automatically scales the compute and local storage resources in the serverless pools in response to Apache Spark’s changing resource requirements for user jobs.
- Reliable fine-grained sharing: Serverless pools embed preemption and fault isolation into Spark, enabling a pool's resources to be shared among many users in a fine-grained manner without compromising on reliability.
Why Serverless Pools?
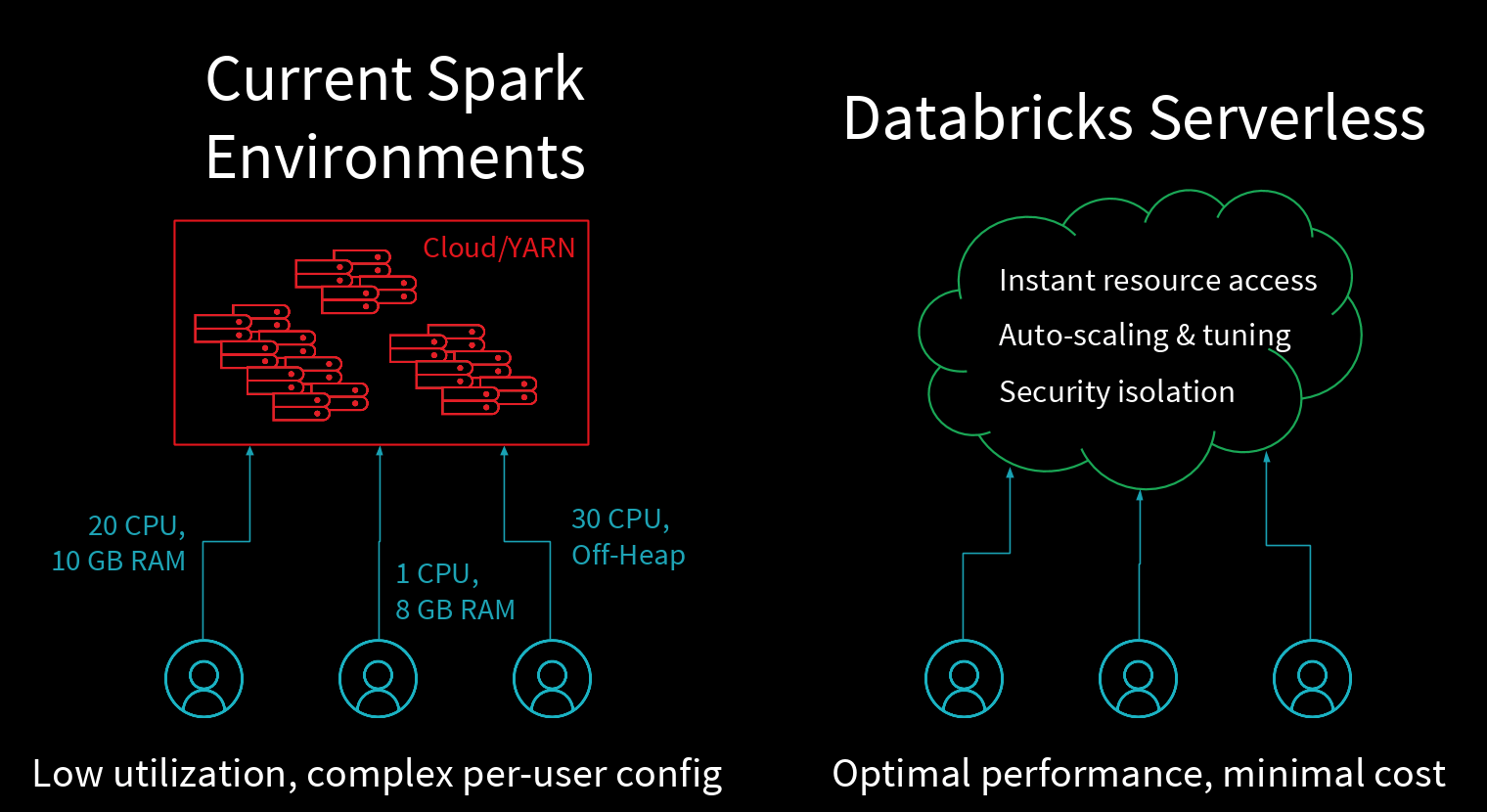
There are multiple existing resource managers for Apache Spark, but none of them provides the high concurrency and automatic elasticity of serverless pools. Existing cluster managers, such as YARN, and cloud services, such as EMR, suffer from the following issues:
- Complex configuration: Each user needs to configure their Spark application by specifying its resource demands (e.g. memory size for containers). The wrong configuration will result in poor performance.
- Low utilization: Applications will often consume fewer resources than they have been allocated in the system, resulting in a wasted resources and higher cost. Reallocation is only done at coarse-grained time scales.
- High query latencies: Users working on interactive data science need their queries to return quickly so that they can plan their next steps in exploring their data sets. If each query requires a few minutes of overhead to submit a job or spin up a new cluster, these latency-sensitive users will have a very poor user experience.
Databricks Serverless pools combine elasticity and fine-grained resource sharing to tremendously simplify infrastructure management for both admins and end-users:
- IT admins can easily manage costs and performance across many users and teams through one setting, without having to configure multiple Spark clusters or YARN jobs.
- Users can focus on their queries, writing stateful data processing code in collaborative environments such as notebooks, without having to think about infrastructure. They simply connect their notebook or job to a serverless pool.
Next, we look at the three key properties of serverless pools in detail.
Auto-Configuration
Typically, configuring a Spark cluster involves the following stages:
- IT admins are tasked with provisioning clusters and managing budgets. They look at all the usage requirements and the cost options available, including things like choosing the right instance types, reserving instances, selecting a spot bid, etc.
- Data engineers and Spark experts then jump in and play around with hundreds of Spark configurations (off-heap memory, serialization formats, etc.) to fine-tune their Spark jobs for good performance.
- If the cluster is going to be used for machine learning workloads, data scientists then spend additional time optimizing the clusters for their algorithms and utilization needs.
Serverless pools drastically simplifies stage 1 and eliminates stage 2 and stage 3, by allowing admins to create a single pool with key AWS parameters such as spot bidding.
Spark-Aware Elasticity
As mentioned earlier, predicting the correct amount of resources for a cluster is one of the hardest tasks for admins and users as they don’t know the usage requirements. This results in a lot of trial and error for users. With serverless pools, users can just specify the range of desired instances and the serverless pools elastically scales the compute and local storage based on individual Spark job’s resource requirements.
Autoscaling Compute: The compute resources in a serverless pool are autoscaled based on Spark tasks queued up in the cluster. This is different from the coarse-grained autoscaling found in traditional resource managers. The Spark-native approach to scaling helps in best resource utilization thereby bringing the infrastructure costs down significantly. Furthermore, serverless pools combine this autoscaling with a mix of on-demand and spot instances to further optimize costs. Read more in our autoscaling documentation.
Autoscaling Storage: Apart from compute and memory, Spark requires disk space for supporting data shuffles and spilling from memory. Having the right amount of disk space is critical to get Spark jobs working without any failures, and data engineers and scientists typically struggle to get this right. Serverless pools use logical volume management to address this issue. As the local storage of worker instances fills up, serverless pools automatically provision additional EBS volumes for the instances and the running Spark jobs seamlessly use the additional space. No more "out of disk space" failures ever!
Reliable Fine-Grained Sharing
Since serverless pools allow for fine-grained sharing of resources between multiple users, dynamic workload management and isolation are essential for predictable performance.
Preemption: When multiple users are sharing a cluster, it is very common to have a single job from a user monopolize all the cluster resources, thereby slowing all other jobs on the cluster. Spark’s fair scheduler pool can help address such issues for a small number of users with similar workloads. As the number of users on a cluster increase, however, it becomes more and more likely that a large Spark job will hog all the cluster resources. The problem can be more aggravated when multiple data personas are running different types of workloads on the same cluster. For example, a data engineer running a large ETL job will often prevent a data analyst from running short, interactive queries. To combat such problems, the serverless pool will proactively preempt Spark tasks from over-committed users to ensure all users get their fair share of cluster time. This gives each user a highly interactive experience while still minimizing overall resource costs.
Fault Isolation: Another common problem when multiple users share a cluster and do interactive analysis in notebooks is that one user's faulty code can crash the Spark driver, bringing down the cluster for all users. In such scenarios, the Databricks resource manager provides fault isolation by sandboxing the driver processes belonging to different notebooks from one another so that a user can safely run commands that might otherwise crash the driver without worrying about affecting the experience of other users.
Performance Evaluation
We did some benchmarking to understand how the serverless pools fare when there is a concurrent and heterogeneous load. Here is the setup: many data scientists are running Spark queries on a cluster. These are short-running interactive jobs that last at most a few minutes. What happens when we introduce a large ETL workload to the same cluster?
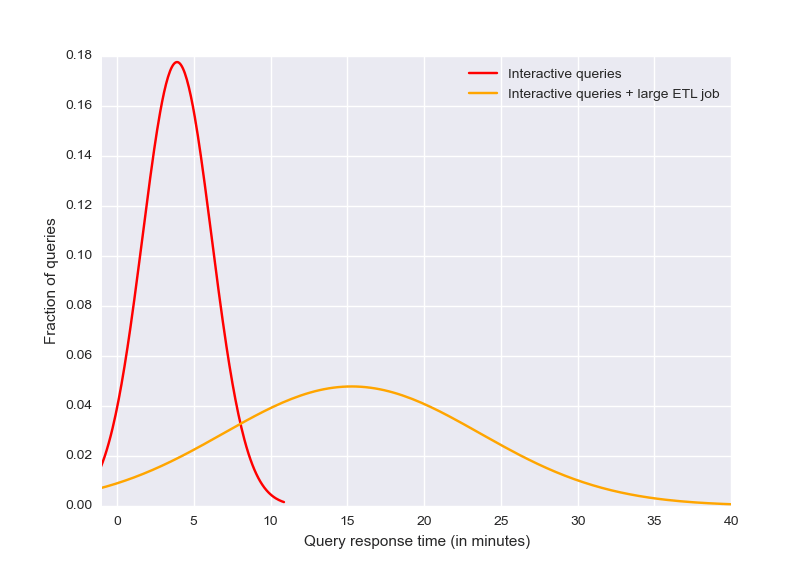
20 Users on Standard Cluster
For standard Spark clusters, when ETL jobs are added, average response times increase from 5 minutes (red line) to 15 (orange line), and in the worst case more than 40 minutes.
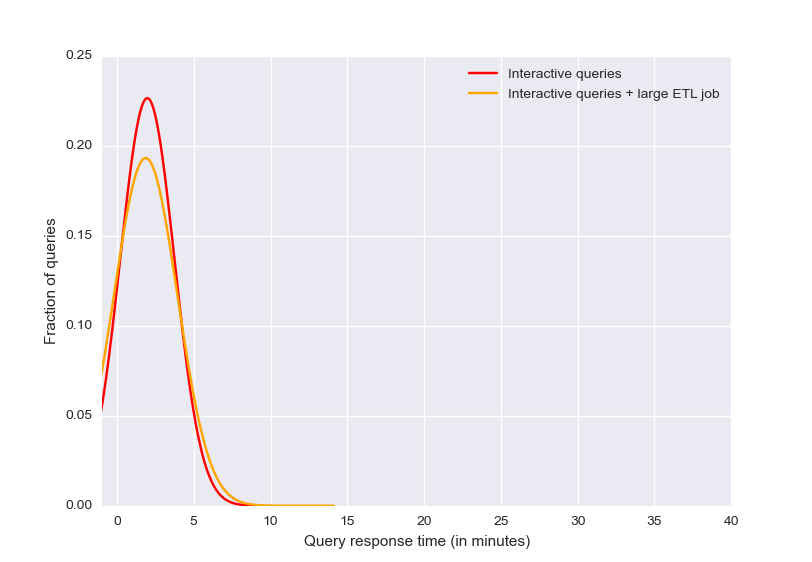
20 Users on Serverless Pool
With a serverless pool, the interactive queries get a little slower when the ETL jobs start, but the Databricks scheduler is able to guarantee performance isolation and limit their impact. The ETL jobs runs in the background, efficiently utilizing idle resources. Users get excellent performance for both workloads without having to run a second cluster.
Comparison with Other Systems
We also tested the performance of larger, concurrent TPC-DS workloads on three environments: (1) Presto on EMR, (2) Apache Spark on EMR and (3) Databricks Serverless.
When there were 5 users each running a TPC-DS workload concurrently on the cluster, the average query latencies for Serverless pools were an order of magnitude lower than Presto.
With 20 users and a background ETL job on the cluster, the difference is even larger, to 12x faster than Presto and 7x faster than Spark on EMR.
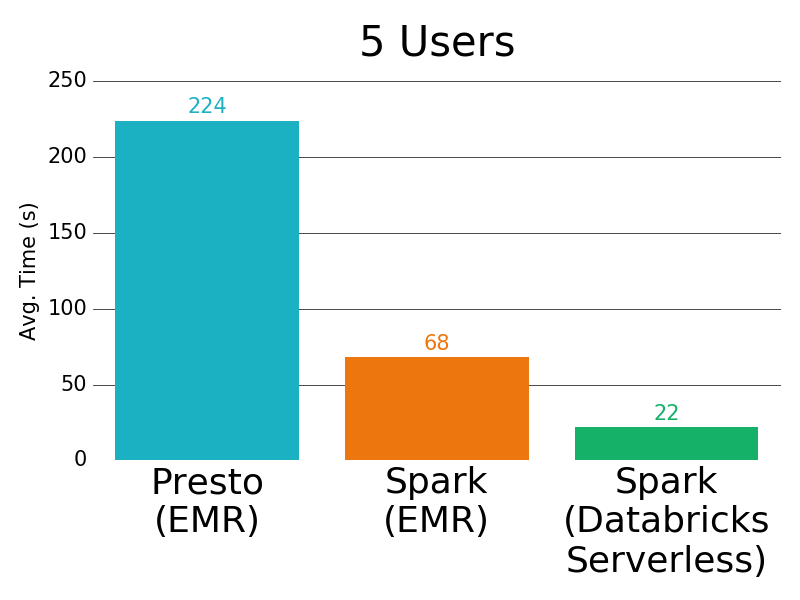
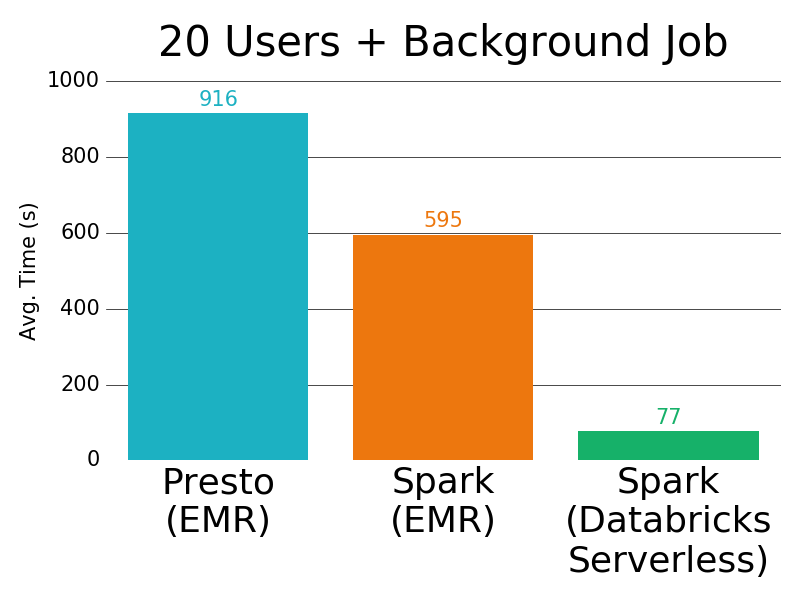
Conclusion
Serverless pools are the first step in our mission to eliminate all operational complexities involved with big data. They take all of the guesswork out of cluster management -- just set the minimum and maximum size of a pool and it will automatically scale within those bounds to adapt to the load being placed on it. They also provide a zero-management experience for users -- just connect to a pool and start running code from notebooks or jobs. We are excited that Databricks Serverless is the first platform to offer all of these serverless computing features for the full power of Apache Spark.
You can try Databricks Serverless in beta form today by signing up for a free Databricks trial.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.