Introducing Command Line Interface for Databricks Developers
Work easily with Databricks File System and Workspace
by Andrew Chen
Introduction
As part of Unified Analytics Platform, Databricks Workspace along with Databricks File System (DBFS) are critical components that facilitate collaboration among data scientists and data engineers: Databricks Workspace manages users’ notebooks, whereas DBFS manages files; both have REST API endpoints to manage notebooks and files respectively.
While the REST APIs are principally designed for general programmatic use, ad-hoc tasks of exploring and manipulating desired content is not that easy with REST APIs without writing repetitive boilerplate code. So to simplify this task for Databricks developers, we have implemented an easy command line interface that interacts with Databricks workspaces and filesystem APIs.
In part 1 of our blog aimed at Databricks developers, we outline some use cases where you can employ a command line interface to interact with Databricks workspaces and manipulate files and folders.
Usage Scenarios
Checking in notebooks to version control systems (VCS)
One of the most common usages of the Databricks CLI is to enable an alternative integration point to VCS.
To check notebooks into VCS, you need a canonical text-based file for the notebook. With the workspace APIs, you can export and import notebooks to this canonical text-based file format. The Databricks CLI builds on this idea further by wrapping these APIs into an easy to use command line interface with support for recursive import and export.
For example, consider a scenario with two users’ workspace and a production workspace: Alice with workspace A, Bob with workspace B, and a production workspace P with notebooks that are run through Databricks Job Scheduler. After developing code in her workspace A, Alice may export her code with databricks workspace export_dir to her git repository and initiate a pull request. Bob can then review and approve the PR, after which Alice can merge her changes to the master. This merge will trigger a Continuous Delivery job in which production workspace P will initiate a databricks workspace import_dir, bringing all new changes into production.
Copying small datasets to DBFS
Another use case for the CLI is importing small datasets to DBFS.
For example:
- (Recursively) copying datasets/files between local file system and DBFS
Installation
To begin, install the CLI by running the following command on your local machine.
pip install --upgrade databricks-cli
Note that the Databricks CLI currently cannot run with Python 3.
After installation is complete, the next step is to provide authentication information to the CLI. The first and recommended way is to use an access token generated from Databricks. To do this run databricks configure --token. A second way is to use your username and password pair. To do this run databricks configure and follow the prompts. After following the prompts, your access credentials will be stored in the file ~/.databrickscfg.
Workspace CLI examples
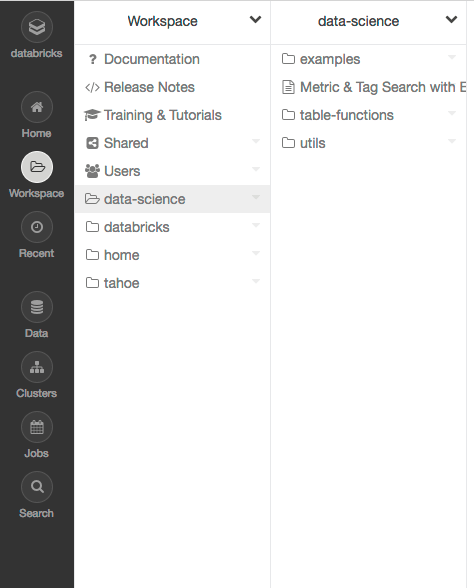
The implemented commands for the Workspace CLI can be listed by running databricks workspace -h. Commands are run by appending them to databricks workspace. To make it easier to use the workspace CLI, feel free to alias databricks workspace to something shorter. For more information reference Aliasing Command Groups and Workspace API.
Listing Workspace Files
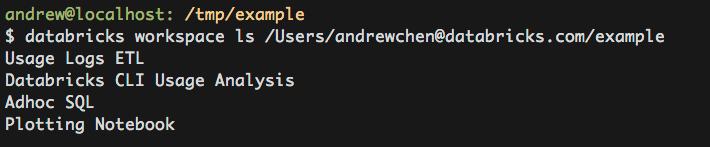
Exporting a workspace directory to the local filesystem
The databricks workspace export_dir command will recursively export a directory from the Databricks workspace to the local filesystem. Only notebooks are exported and when exported, the notebooks will have the appropriate extensions (.scala, .py, .sql, .R) appended to their names).

Importing a local directory of notebooks
Similarly, the databricks workspace import_dir command will recursively import a directory from the local filesystem to the Databricks workspace. Only directories and files with the extensions of .scala, .py, .sql, .r, .R are imported. When imported, these extensions will be stripped off the name of the notebook.
To overwrite existing notebooks at the target path, the flag -o must be added.
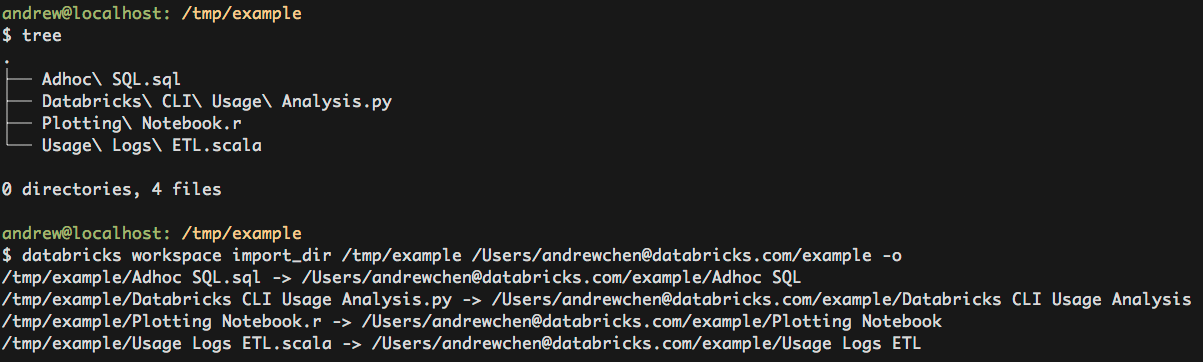
DBFS CLI Examples
The implemented commands for the DBFS CLI can be listed by running databricks fs -h. Commands are run by appending them to databricks fs and all dbfs paths should be prefixed with dbfs:/. To make the command less verbose, we’ve gone ahead and aliased dbfs to databricks fs. For more information reference DBFS API.
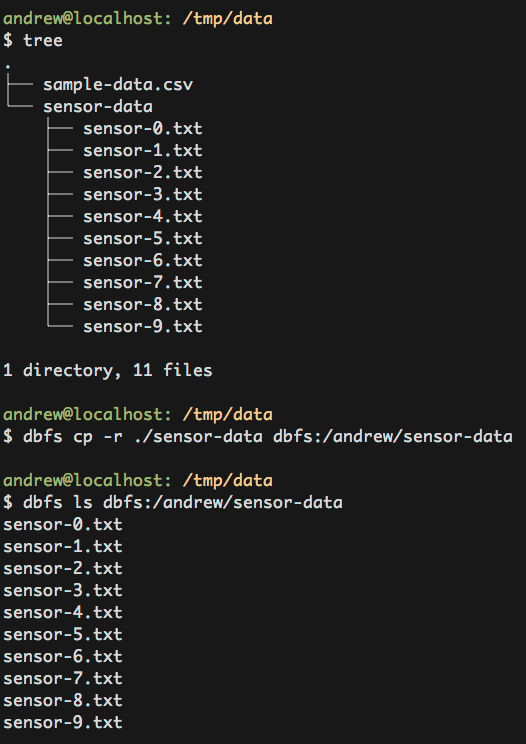
Copying a file to DBFS
It’s possible to copy files from your localhost to DBFS both file by file and recursively. For example to copy a CSV to DBFS, you can run the following command.

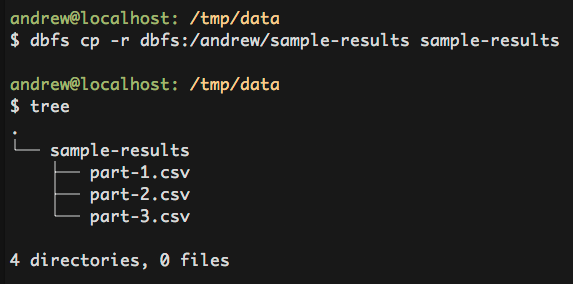
For recursive copying, add the -r flag.
Copying a file from DBFS
Similarly, it is possible to copy files from DBFS back to the local filesystem.

What's Next
We’re actively developing new features for the Databricks CLI for developers. The next item immediately on our roadmap is to support cluster and jobs APIs endpoints. We will cover in the second part of this blog series.
In the spirit of our open source Apache Spark heritage, the source code for the CLI is released on Github. If you have feedback on a feature, please leave an issue on our Github project.
Try this out today on Databricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.