How to Use MLflow To Reproduce Results and Retrain Saved Keras ML Models
Examine experiment results with TensorBoard and MLFlow UI
by Jules Damji
In part 2 of our series on MLflow blogs, we demonstrated how to use MLflow to track experiment results for a Keras network model using binary classification. We classified reviews from an IMDB dataset as positive or negative. And we created one baseline model and two experiments. For each model, we tracked its respective training accuracy and loss and validation accuracy and loss.
In this third part in our series, we’ll show how you can save your model, reproduce results, load a saved model, predict unseen reviews—all easily with MLFlow—and view results in TensorBoard.
Saving Models in MLFlow
MLflow logging APIs allow you to save models in two ways. First, you can save a model on a local file system or on a cloud storage such as S3 or Azure Blob Storage; second, you can log a model along with its parameters and metrics. Both preserve the Keras HDF5 format, as noted in MLflow Keras documentation.
First, if you save the model using MLflow Keras model API to a store or filesystem, other ML developers not using MLflow can access your saved models using the generic Keras Model APIs. For example, within your MLflow runs, you can save a Keras model as shown in this sample snippet:
Once saved, ML developers outside MLflow can simply use the Keras APIs to load the model and predict it. For example,
Second, you can save the model as part of your run experiments, along with other metrics and artifacts as shown in the code snippet below:
With this second approach, you can access its run_uuid or location from the MLflow UI runs as part of its saved artifacts:
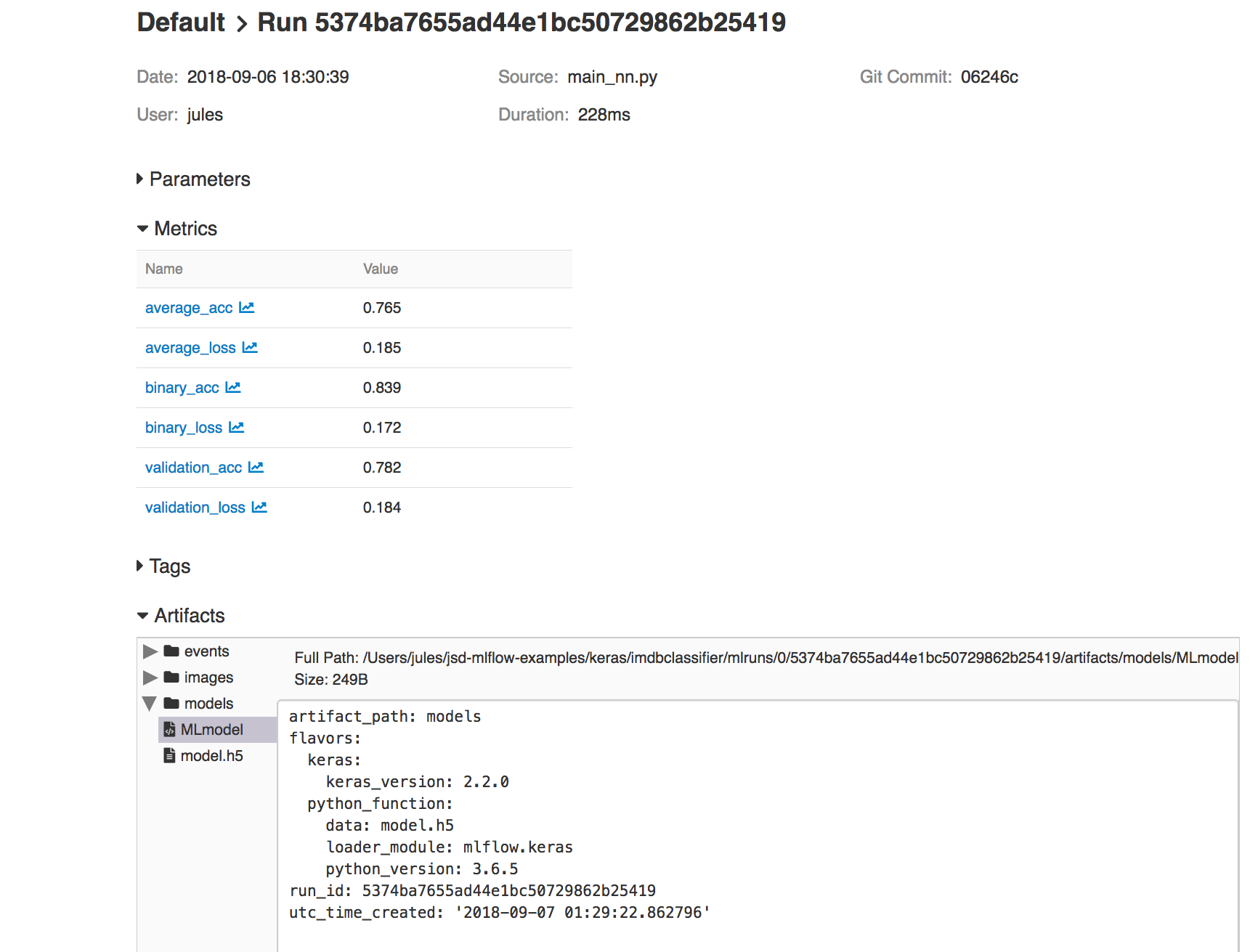
In our IMDB example, you can view code for both modes of saving in train_nn.py, class KTrain(). Saving model in this way provides access to reproduce the results from within MLflow platform or reload the model for further predictions, as we’ll show in the sections below.
Reproducing Results from Saved Models
As part of machine development life cycle, reproducibility of any model experiment by ML team members is imperative. Often you will want to either retrain or reproduce a run from several past experiments to review respective results for sanity, audibility or curiosity.
One way, in our example, is to manually copy logged hyper-parameters from the MLflow UI for a particular run_uuid and rerun using main_nn.py or reload_nn.py with the original parameters as arguments, as explained in the README.md.
Either way, you can reproduce your old runs and experiments:
Or use mlflow run command:
By default, the tracking_server defaults to the local mlruns directory. Here is an animated sample output from a reproducible run:
https://www.youtube.com/watch?v=tAg7WiraUm0
Fig 2. Run showing reproducibility from a previous run_uuid
Loading and Making Predictions with Saved Models
In the previous sections, when executing your test runs, the models used for these test runs also saved via the mlflow.keras.log_model(model, "models"). Your Keras model is saved in HDF5 file format as noted in MLflow > Models > Keras. Once you have found a model that you like, you can re-use your model using MLflow as well.
This model can be loaded back as a Python Function as noted noted in mlflow.keras using mlflow.keras.load_model(path, run_id=None).
To execute this, you can load the model you had saved within MLflow by going to the MLflow UI, selecting your run, and copying the path of the stored model as noted in the screenshot below.
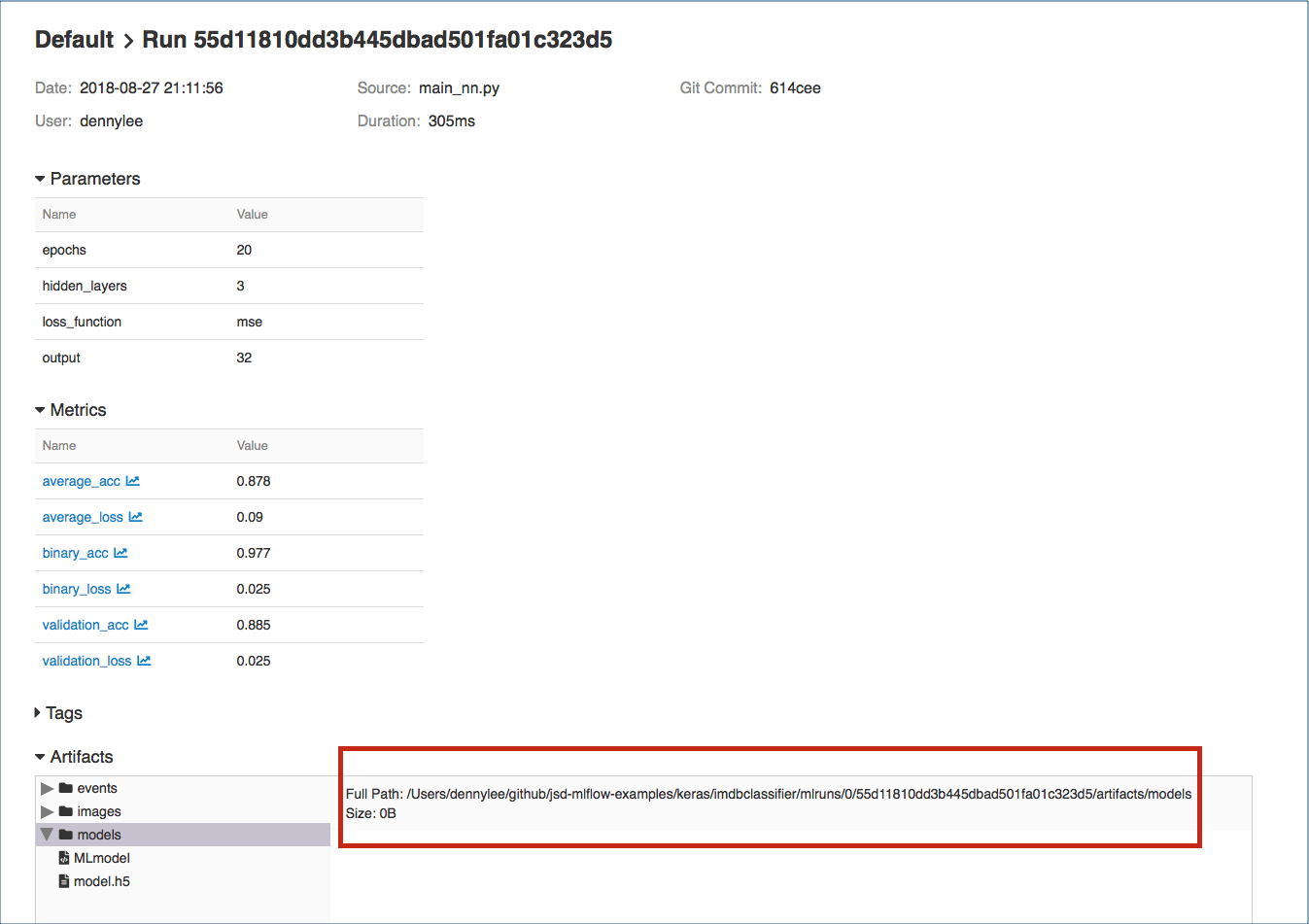
With your model identified, you can type in your own review by loading your model and executing it. For example, let’s use a review that is not included in the IMDB Classifier dataset:
this is a wonderful film with a great acting, beautiful cinematography, and amazing direction
To run a prediction against this review, use the predict_nn.py against your model:
Or you can run it directly using mlflow and the imdbclassifer repo package:
The output for this command should be similar to the following output predicting a positive sentiment for the provided review.
Examining Results with TensorBoard
In addition to reviewing your results in the MLflow UI, the code samples save TensorFlow events so that you can visualize the TensorFlow session graph. For example, after executing the statement python main_nn.py, you will see something similar to the following output:
You can extract the TensorBoard log directory with the output line stating Writing TensorFlow events locally to .... And to start TensorBoard, you can run the following command:
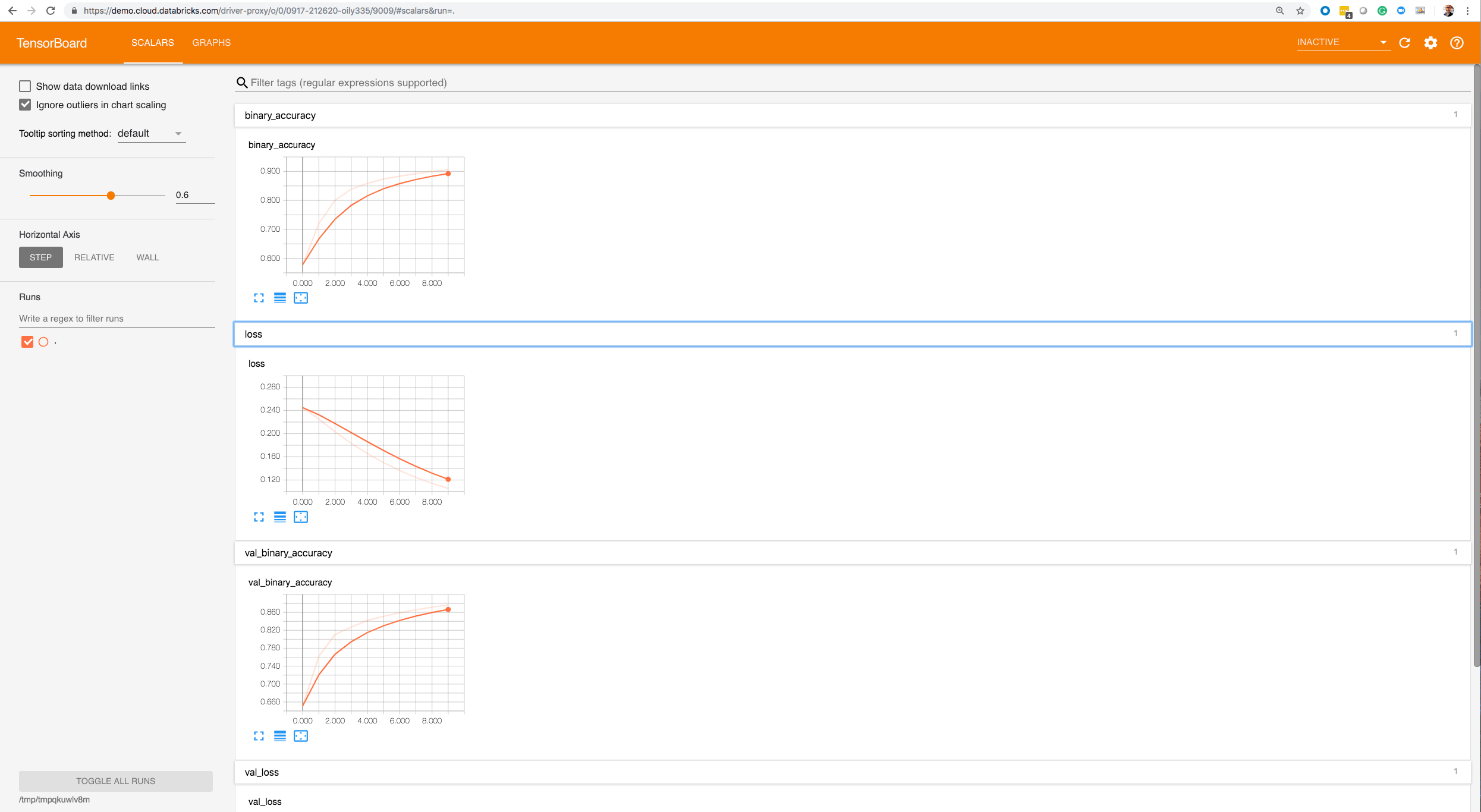
Within the TensorBoard UI:
- Click on Scalars to review the same metrics recorded within MLflow: binary loss, binary accuracy, validation loss, and validation accuracy.
- Click on Graph to visualize and interact with your session graph
Closing Thoughts
In this blog post, we demonstrated how to use MLflow to save models and reproduce results from saved models as part of the machine development life cycle. In addition, through both python and mlflow command line, we loaded a saved model and predicted the sentiment of our own custom review unseen by the model. Finally, we showcased how you can utilize MLflow and TensorBoard side-by-side by providing code samples that generate TensorFlow events so you can visualize the metrics as well as the session graph.
What’s Next?
You have seen, in three parts, various aspects of MLflow: from experimentation to reproducibility and using MLlfow UI and TensorBoard for visualization of your runs.
You can try MLflow at mlflow.org to get started. Or try some of tutorials and examples in the documentation, including our example notebook Keras_IMDB.py for this blog.
Read More
Here are some resources for you to learn more:
- Read MLflow Docs
- Find out How to Use Keras, TensorFlow, and MLflow with PyCharm
- Learn How to Use MLflow to Experiment a Keras Network Model: Binary Classification for Movie Reviews
- Learn from Introducing mlflow-apps: A Repository of Sample Applications for MLflow
- View MLflow Meetup Presentations and Slides
- Get Github sources for this blog example
- Find out New Features in MLflow Release v0.6.0
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.