Transform Your AWS Data Lake using Databricks Delta and the AWS Glue Data Catalog Service
by Denis Dubeau
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
In this blog post we will explore how to reliably and efficiently transform your AWS Data Lake into a Delta Lake seamlessly using the AWS Glue Data Catalog service. The AWS Glue service is an Apache compatible Hive serverless metastore which allows you to easily share table metadata across AWS services, applications, or AWS accounts.
This provides several concrete benefits:
- Simplifies manageability by using the same AWS Glue catalog across multiple Databricks workspaces.
- Simplifies integrated security by using Identity and Access Management Credential Passthrough for metadata in AWS Glue. Refer to the Databricks blog introducing Databricks AWS IAM Credential Passthrough for a detailed explanation.
- Provides easier access to metadata across the Amazon services and access to data catalogued in AWS Glue.
Databricks Delta Lake Integration with the AWS Core Services
This reference implementation illustrates the uniquely positioned Databricks Delta Lake integration with the AWS core services helping you solve your most complex Data Lake challenges.
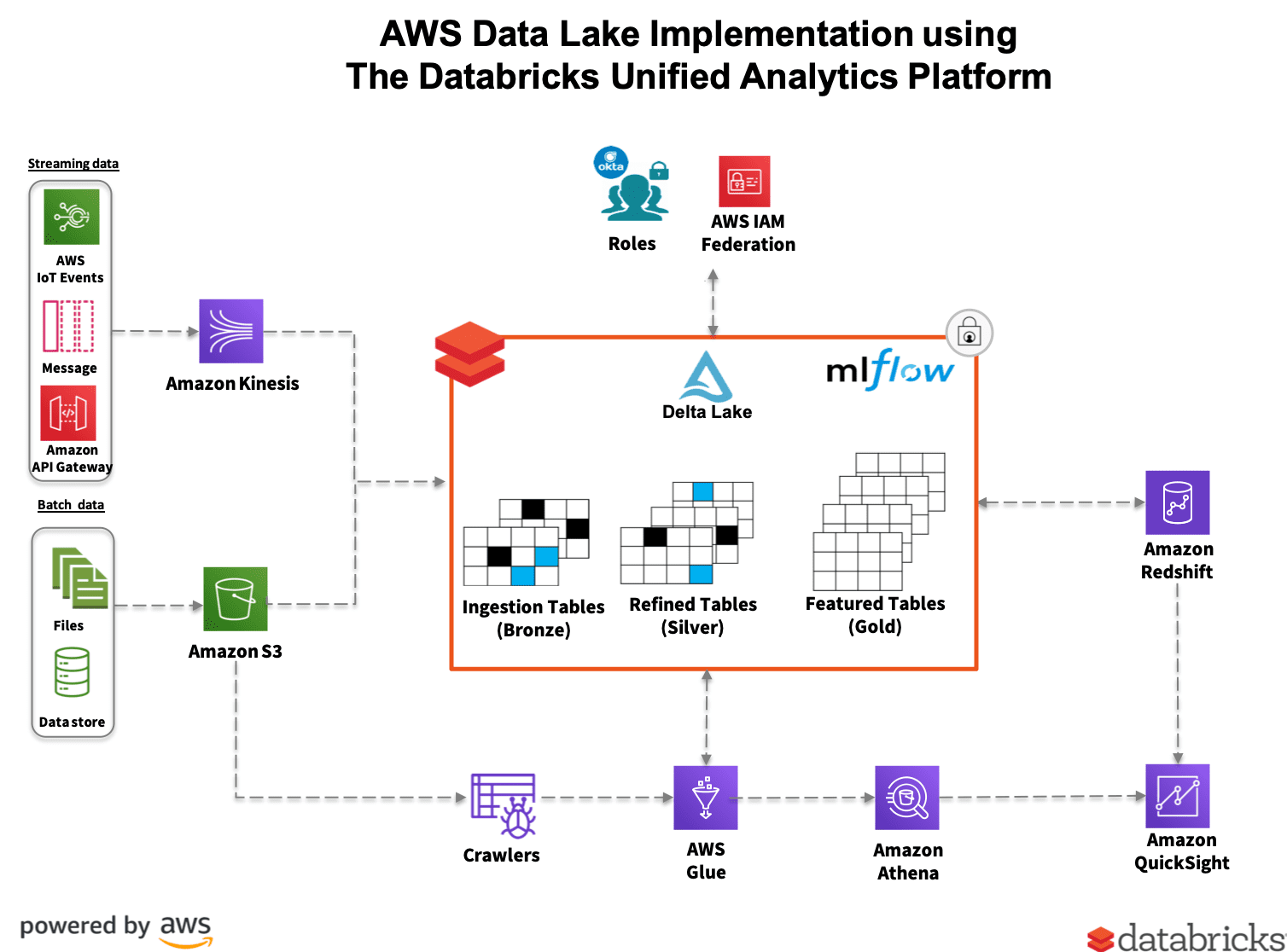
Overview
What is Delta Lake?
Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
Download this ebook to gain an understanding of the key data reliability challenges typical facing data lakes and how Delta Lake helps address those challenges.
Databricks recently open-sourced Delta Lake at the 2019 Spark Summit. You can learn more about Delta Lake at delta.io.
Presto and Amazon Athena compatibility support for Delta Lake
As of Databricks runtime 5.5, you can now query Delta Lake tables from Presto and Amazon Athena. When an external table is defined in the Hive metastore using manifest files, Presto and Amazon Athena use the list of files in the manifest file rather than finding the files by directory listing. These tables can be queried just like tables with data stored in formats like Parquet.
Step 1. How to configure a Databricks cluster to access your AWS Glue Catalog
First, you must launch the Databricks computation cluster with the necessary AWS Glue Catalog IAM role. The IAM role and policy requirements are clearly outlined in a step-by-step manner in the Databricks AWS Glue as Metastore documentation.
For the purpose of this blog, I’ve created an AWS IAM role called Field_Glue_Role which also has delegated access to my S3 bucket. I’m attaching the role to my cluster configuration, as depicted in Figure 1.
Figure 1.
Next, the Spark Configuration properties of the cluster configuration must be set prior to the cluster startup as shown in Figure 2.
Figure 2. Updating the Databricks Cluster Spark Configuration properties
Step 2. Setting up the AWS Glue database using a Databricks notebook
Before creating an AWS Glue database let’s attach the cluster to your notebook, created in the previous step, and test your setup issuing the following command:
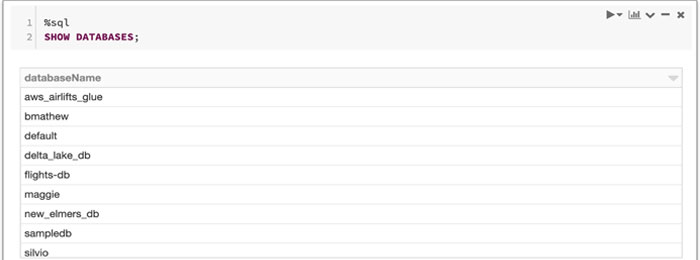
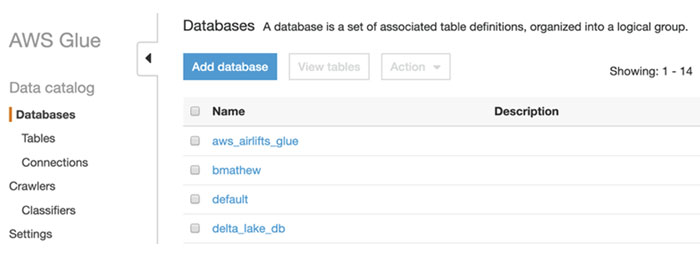
Then validate that the same list of databases is displayed using the AWS Glue console and list the databases.
We are now ready to create a new AWS Glue database directly from our notebook as follows:
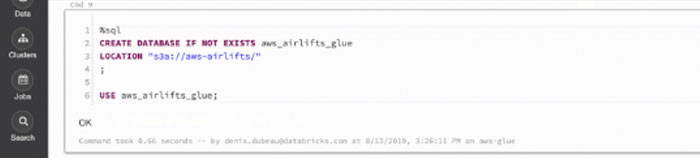
And verify that the new AWS Glue database has been created successfully by re-issuing the SHOW DATABASES. The AWS Glue database can also be viewed via the data pane.
Step 3. Create a Delta Lake table and manifest file using the same metastore
Now, let’s create and catalog our table directly from the notebook into the AWS Glue Data Catalog. Refer to how Populating the AWS Glue data catalog for creating and cataloging tables using crawlers.
I’m using the movie recommendation site MovieLens dataset which is comprised of movie ratings. I first created a DataFrame with this python code:

and then register the DataFrame as a temporary table to access it using SQL as follows:

Now let’s create a Delta Lake table using SQL and the temporary table created in the previous step:
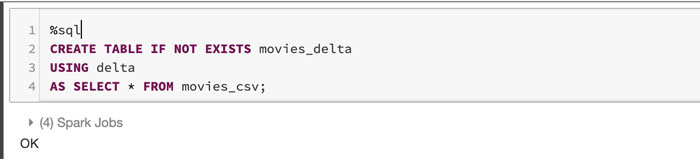
Note: It’s very easy to create a Delta Lake table as described in this Delta Lake Delta Lake Quickstart Guide.
We can now generate the manifest file required by Amazon Athena using the following steps.
- Generate manifests by running this Scala method. Remember to prefix the cell with %scala if you have created a python, SQL or R notebook.

- Create a table in the Hive metastore connected to Athena using the special format SymlinkTextInputFormat and the manifest file location:
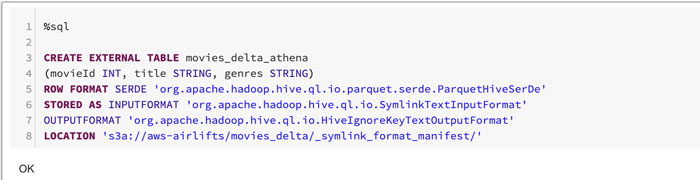
In the above sample code, notice that the manifest file is created in the s3a://aws-airlifts/movies_delta/_symlink_format_manifest/ file location.
Step 4. Query the Delta Lake table using Amazon Athena
Athena is a serverless service that does not need any infrastructure to manage and maintain. Therefore, you can query the Delta table without the need of a Databricks cluster running.
From the Amazon Athena console, select your database, then preview the table as follows:
Conclusion
With the support of AWS Glue we have introduced a powerful serverless metastore strategy for all enterprises using the AWS ecosystem. Furthermore, we are elevating the reliability of your Data Lake with Delta Lake and provide seamless as well as serverless data access for your enterprise by integrating with Amazon Athena.
You can now safely enable your analysts, data engineers, and data scientists to use the Databricks Unified Analytics Platform to power your Data Lake strategy on AWS.
Related Resources:
- Open Sourcing Delta Lake
- eBook: Building Reliable Data Lakes at Scale with Delta Lake
- Delta Lake Quickstart
- Databricks Runtime
Try it!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.