Simple, Reliable Upserts and Deletes on Delta Lake Tables using Python APIs
Delta Lake 0.4.0 includes Python APIs and In-place Conversion of Parquet to Delta Lake table
by Tathagata Das and Denny Lee
We are excited to announce the release of Delta Lake 0.4.0 which introduces Python APIs for manipulating and managing data in Delta tables. The key features in this release are:
- Python APIs for DML and utility operations (#89) - You can now use Python APIs to update/delete/merge data in Delta Lake tables and to run utility operations (i.e., vacuum, history) on them. These are great for building complex workloads in Python, e.g., Slowly Changing Dimension (SCD) operations, merging change data for replication, and upserts from streaming queries. See the documentation for more details.
- Convert-to-Delta (#78) - You can now convert a Parquet table in place to a Delta Lake table without rewriting any of the data. This is great for converting very large Parquet tables which would be costly to rewrite as a Delta table. Furthermore, this process is reversible - you can convert a Parquet table to Delta Lake table, operate on it (e.g., delete or merge), and easily convert it back to a Parquet table. See the documentation for more details.
- SQL for utility operations - You can now use SQL to run utility operations vacuum and history. See the documentation for more details on how to configure Spark to execute these Delta-specific SQL commands.
For more information, please refer to the Delta Lake 0.4.0 release notes and Delta Lake Documentation > Table Deletes, Updates, and Merges.
In this blog, we will demonstrate on Apache Spark™ 2.4.3 how to use Python and the new Python APIs in Delta Lake 0.4.0 within the context of an on-time flight performance scenario. We will show how to upsert and delete data, query old versions of data with time travel and vacuum older versions for cleanup.
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
How to start using Delta Lake
The Delta Lake package is available as with the --packages option. In our example, we will also demonstrate the ability to VACUUM files and execute Delta Lake SQL commands within Apache Spark. As this is a short demonstration, we will also enable the following configurations:
spark.databricks.delta.retentionDurationCheck.enabled=falseto allow us to vacuum files shorter than the default retention duration of 7 days. Note, this is only required for the SQL command VACUUM.spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtensionto enable Delta Lake SQL commands within Apache Spark; this is not required for Python or Scala API calls.
Loading and saving our Delta Lake data
This scenario will be using the On-time flight performance or Departure Delays dataset generated from the RITA BTS Flight Departure Statistics; some examples of this data in action include the 2014 Flight Departure Performance via d3.js Crossfilter and On-Time Flight Performance with GraphFrames for Apache Spark™. This dataset can be downloaded locally from this github location. Within pyspark, start by reading the dataset.
Next, let’s save our departureDelays dataset to a Delta Lake table. By saving this table to Delta Lake storage, we will be able to take advantage of its features including ACID transactions, unified batch and streaming, and time travel.
Note, this approach is similar to how you would normally save Parquet data; instead of specifying format("parquet"), you will now specify format("delta"). If you were to take a look at the underlying file system, you will notice four files created for the departureDelays Delta Lake table.
Note, the _delta_log is the folder that contains the Delta Lake transaction log. For more information, refer to Diving Into Delta Lake: Unpacking The Transaction Log.
Now, let’s reload the data but this time our DataFrame will be backed by Delta Lake.

Finally, let’s determine the number of flights originating from Seattle to San Francisco; in this dataset, there are 1698 flights.
In-place Conversion to Delta Lake
If you have existing Parquet tables, you have the ability to perform in-place conversions your tables to Delta Lake thus not needing to rewrite your table. To convert the table, you can run the following commands.
For more information, including how to do this conversion in Scala and SQL, refer to Convert to Delta Lake.
Delete our Flight Data
To delete data from your traditional Data Lake table, you will need to:
- Select all of the data from your table not including the rows you want to delete
- Create a new table based on the previous query
- Delete the original table
- Rename the new table to the original table name for downstream dependencies.
Instead of performing all of these steps, with Delta Lake, we can simplify this process by running a DELETE statement. To show this, let’s delete all of the flights that had arrived early or on-time (i.e. delay ).

After we delete (more on this below) all of the on-time and early flights, as you can see from the preceding query there are 837 late flights originating from Seattle to San Francisco. If you review the file system, you will notice there are more files even though you deleted data.
In traditional data lakes, deletes are performed by re-writing the entire table excluding the values to be deleted. With Delta Lake, deletes instead are performed by selectively writing new versions of the files containing the data be deleted and only marks the previous files as deleted. This is because Delta Lake uses multiversion concurrency control to do atomic operations on the table: for example, while one user is deleting data, another user may be querying the previous version of the table. This multi-version model also enables us to travel back in time (i.e. time travel) and query previous versions as we will see later.
Update our Flight Data
To update data from your traditional Data Lake table, you will need to:/p>
- Select all of the data from your table not including the rows you want to modify
- Modify the rows that need to be updated/changed
- Merge these two tables to create a new table
- Delete the original table
- Rename the new table to the original table name for downstream dependencies.
Instead of performing all of these steps, with Delta Lake, we can simplify this process by running an UPDATE statement. To show this, let’s update all of the flights originating from Detroit to Seattle.

With the Detroit flights now tagged as Seattle flights, we now have 986 flights originating from Seattle to San Francisco. If you were to list the file system for your departureDelays folder (i.e. $../departureDelays/ls -l), you will notice there are now 11 files (instead of the 8 right after deleting the files and the four files after creating the table).
Merge our Flight Data
A common scenario when working with a data lake is to continuously append data to your table. This often results in duplicate data (rows you do not want inserted into your table again), new rows that need to be inserted, and some rows that need to be updated. With Delta Lake, all of this can be achieved by using the merge operation (similar to the SQL MERGE statement).
Let’s start with a sample dataset that you will want to be updated, inserted, or deduplicated with the following query.
The output of this query looks like the following table below. Note, the color-coding has been added to this blog to clearly identify which rows are deduplicated (blue), updated (yellow), and inserted (green).
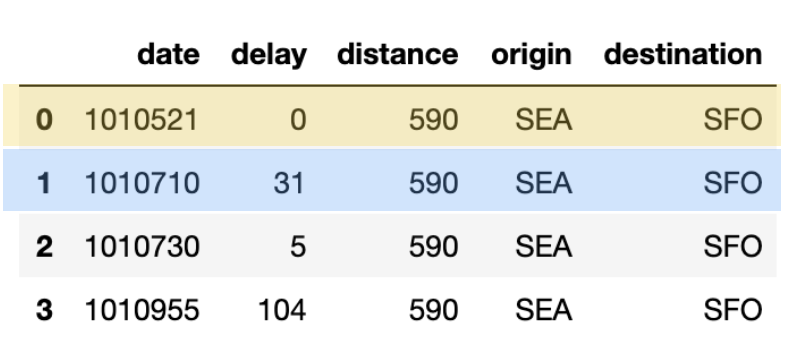
Next, let’s generate our own merge_table that contains data we will insert, update or de-duplicate with the following code snippet.
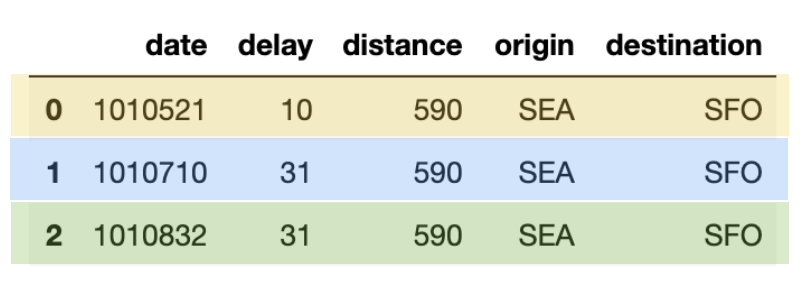
In the preceding table (merge_table), there are three rows that with a unique date value:
- 1010521: this row needs to update the flights table with a new delay value (yellow)
- 1010710: this row is a duplicate (blue)
- 1010822: this is a new row to be inserted (green)
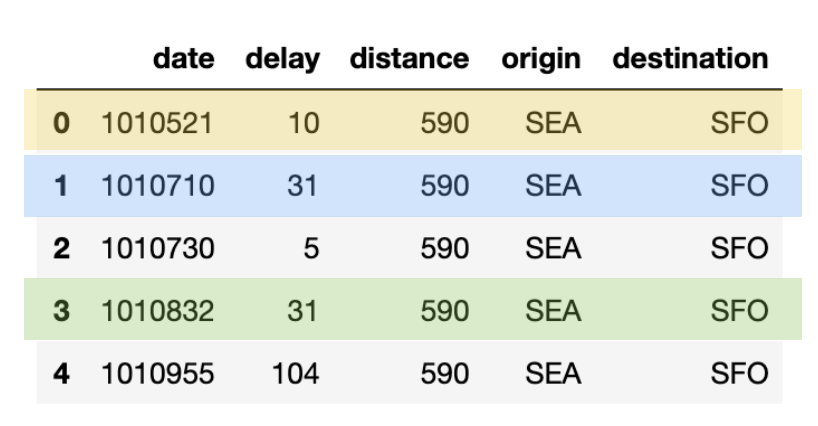
With Delta Lake, this can be easily achieved via a merge statement as noted in the following code snippet.
All three actions of de-duplication, update, and insert was efficiently completed with one statement.
View Table History
As previously noted, after each of our transactions (delete, update), there were more files created within the file system. This is because for each transaction, there are different versions of the Delta Lake table. This can be seen by using the DeltaTable.history() method as noted below.
Note, you can also perform the same task with SQL:spark.sql("DESCRIBE HISTORY '" + pathToEventsTable + "'").show()
As you can see, there are three rows representing the different versions of the table (below is an abridged version to help make it easier to read) for each of the operations (create table, delete, and update):
| version | timestamp | operation | operationParameters |
|---|---|---|---|
| 2 | 2019-09-29 15:41:22 | UPDATE | [predicate -> (or... |
| 1 | 2019-09-29 15:40:45 | DELETE | [predicate -> ["(... |
| 0 | 2019-09-29 15:40:14 | WRITE | [mode -> Overwrit... |
Travel Back in Time with Table History
With Time Travel, you can see review the Delta Lake table as of the version or timestamp. For more information, refer to Delta Lake documentation > Read older versions of data using Time Travel. To view historical data, specify the version or Timestamp option; in the code snippet below, we will specify the version option
Whether for governance, risk management, and compliance (GRC) or rolling back errors, the Delta Lake table contains both the metadata (e.g. recording the fact that a delete had occurred with these operators) and data (e.g. the actual rows deleted). But how do we remove the data files either for compliance or size reasons?
Cleanup Old Table Versions with Vacuum
The Delta Lake vacuum method will delete all of the rows (and files) by default that are older than 7 days (reference: Delta Lake Vacuum). If you were to view the file system, you’ll notice the 11 files for your table.
To delete all of the files so that you only keep the current snapshot of data, you will specify a small value for the vacuum method (instead of the default retention of 7 days).
Note, you perform the same task via SQL syntax:¸# Remove all files older than 0 hours oldspark.sql("VACUUM '" + pathToEventsTable + "' RETAIN 0 HOURS")
Once the vacuum has completed, when you review the file system you will notice fewer files as the historical data has been removed.
Note, the ability to time travel back to a version older than the retention period is lost after running vacuum.
What’s Next
Try out Delta Lake today by trying out the preceding code snippets on your Apache Spark 2.4.3 (or greater) instance. By using Delta Lake, you can make your data lakes more reliable (whether you create a new one or migrate an existing data lake). To learn more, refer to https://delta.io/ and join the Delta Lake community via Slack and Google Group. You can track all the upcoming releases and planned features in github milestones.
Coming up, we’re also excited to have Spark AI Summit Europe from October 15th to 17th. At the summit, we’ll have a training session dedicated to Delta Lake.
Credits
We want to thank the following contributors for updates, doc changes, and contributions in Delta Lake 0.4.0: Andreas Neumann, Burak Yavuz, Jose Torres, Jules Damji, Jungtaek Lim, Liwen Sun, Michael Armbrust, Mukul Murthy, Pranav Anand, Rahul Mahadev, Shixiong Zhu, Tathagata Das, Terry Kim, Wenchen Fan, Wesley Hoffman, Yishuang Lu, Yucai Yu, lys0716.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.