Databricks Named A Leader in Gartner Magic Quadrant for Data Science and Machine Learning Platforms
by Adam Conway, Bharath Gowda and Clemens Mewald
Gartner has released its 2020 Data Science and Machine Learning Platforms
Magic Quadrant, and we are excited to announce that Databricks has been recognized as a Leader.
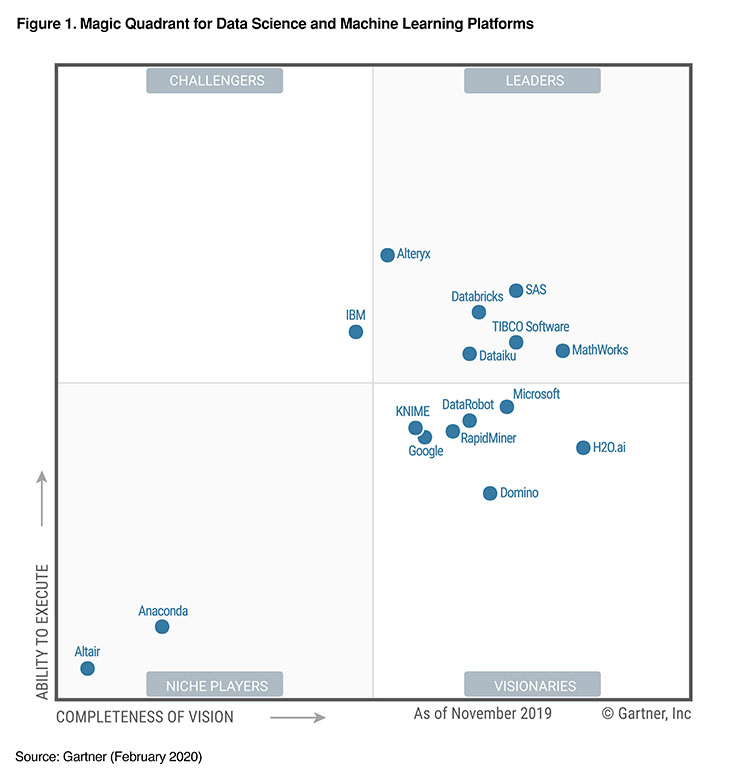
Gartner evaluated 17 vendors for their completeness of vision and ability to execute.
We are confident the following attributes contributed to the company's success:
- Our unique ability to unify data and machine learning workloads, and scale these workloads for customers across all industries and sizes
- Our strong market momentum and ability to execute on our vision and expand through partner and sales strategies across industries
- Our continued focus on customer success and innovations in the open-source community
Unification of Data and AI, and Operationalization at Scale
The biggest advantage of Databricks’ Unified Data Analytics Platform is its ability to run data processing and machine learning workloads at scale and all in one place. Customers praise Databricks for significantly reducing TCO and accelerating time to value, thanks to its seamless end-to-end integration of everything from ETL to exploratory data science to production machine learning.
With Databricks, data teams can build reliable data pipelines with Delta Lake, which adds reliability and performance to existing data lakes. Data scientists can explore data and build models in one place with collaborative notebooks, track and manage experiments and models across the lifecycle with MLflow, and benefit from built-in and optimized ML environments (including the most common ML frameworks). Databricks also makes it easy to set up and leverage auto-managed and scalable clusters — from experimentation to production — capable of running all analytics processes at unprecedented speed and scale.
Running all steps of the workflow on one cohesive platform makes data teams far more productive because they can easily work securely, collaborate and manage knowledge.
"Databricks has been an incredibly powerful end-to-end solution for us. It's allowed a variety of different team members from different backgrounds to quickly get in and utilize large volumes of data to make actionable business decisions." Paul Fryzel – Principal Engineer of AI Infrastructure, Condé Nast
Large and growing ecosystem of ISV and technology partners
Databricks has an established and rapidly growing ecosystem of hundreds of ISV and Technology partners that have built connectors to leverage Databricks as the core processing platform for Data Science and Data Engineering.
Our unique and strategic partnership with Microsoft allowed us to build a ‘first-party service’ on Azure called Azure Databricks, which operates seamlessly with Azure security and natively integrates with a host of core Azure data services such as Azure Data Lake Storage, Azure Data Factory, Azure SQL Data Warehouse and Azure Machine Learning.
AWS continues to be a strategic partner, with deep integrations to AWS S3, AWS Glue, AWS Redshift and AWS SageMaker plus the Identity and Access Management services for security.
A number of additional data source connectors make it easy to access data wherever it lives. User analytics and visualizations of data in Databricks tables is made broadly accessible with BI Tools that connect directly to Databricks, including Power BI, Tableau, Looker, Alteryx, Qlik, Mode, etc. The development of data pipelines, ETL jobs, data prep and application integration is extended into tools like Azure Data Factory, Informatica, Talend and many more. In addition to the Azure Machine Learning and AWS SageMaker integrations mentioned above, Databricks integrates with popular data science and machine learning tools like RStudio, Dataiku and DataRobot.
Laser Focused on Customer Success and Open Source
We've grown globally across industries and geos to better serve thousands of our customers across the world. Our portfolio of services coupled with our customer success engineers provide a comprehensive approach to ensure our clients get the most out of the platform through personalized assistance, consulting, education, and training. Furthermore, our global support team is now distributed across 3 continents and 6 different time zones to provide rapid responses to customer inquiries.
Data science is an open-source movement and Databricks, founded by the original creators of Apache Spark, Delta Lake, and MLflow, has always maintained a strong commitment to the community, continuously innovating and contributing to open source projects. For example, we've trained and certified over 100,000 developers on Apache SparkTM to date.
Originally announced at Spark + AI Summit 2018 in San Francisco, MLflow: an open-source platform for the complete ML lifecycle, has gained significant momentum in the community. With over 900,000 monthly downloads on PyPI and over 160 contributing users, MLflow is now the standard for managing the ML lifecycle.
Following the announcement that Delta Lake would be open-sourced in April 2019 and the resulting massive adoption by enterprises since then, we donated the project to the Linux Foundation to help the open-source community improve the reliability, quality and performance of data lakes. Since its launch in October 2017, Delta Lake has been adopted by more than 4,000 organizations and processes over two exabytes of data each month.
Conclusion
With the Unified Data Analytics Platform, customers can now achieve desirable business outcomes with data-driven innovation thanks to one cohesive platform for data science, ML and analytics that brings together teams, processes and technologies. This allows for effective data lineage and governance throughout the Data & ML pipelines.
Contact us to find out more or schedule a demo.
Gartner "Magic Quadrant for Data Science and Machine Learning," written by Peter Krensky, Pieter den Hamer, Erick Brethenoux, Jim Hare, Carlie Idoine, Alexander Linden, Svetlana Sicular, Farhan Choudhary, February 11, 2020.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.